
【5】pytorch torchvision原始碼解讀之DenseNet
pytorch框架中有一個非常重要且好用的包:torchvision,顧名思義這個包主要是關於計算機視覺cv的。這個包主要由3個子包組成,分別是:torchvision.datasets、torchvision.models、torchvision.transforms。
具體介紹可以參考官網:https://pytorch.org/docs/master/torchvision
具體程式碼可以參考github:https://github.com/pytorch/vision
torchvision.models這個包中包含alexnet、densenet、inception、resnet、squeezenet、vgg等常用經典的網路結構,並且提供了預訓練模型,可以通過簡單呼叫來讀取網路結構和預訓練模型。
今天我們來解讀一下DenseNet的原始碼實現。如果對DenseNet不是很瞭解 可以檢視這裡的論文筆記
DenseNet由Dense Block組成,而Dense Block石油DenseLayer組成,下面就是DenseLayer類,可以看到每一層卷積之前都是用了batchnorm和relu,然後就是1*1的卷積和3*3的卷積。bn_size引數是bottleneck layer瓶頸層數的乘法因子。bottleneck layer就是指在3*3的卷積之前的那層1*1的卷積,它降低輸入的feature map的數量。drop_rate是drop out的概率大小。
注意到最後返回值是torch.cat([x, new_features], 1),也就是包括自己本身和提取的feature層堆疊在一起。
class _DenseLayer(nn.Sequential): def __init__(self, num_input_features, growth_rate, bn_size, drop_rate): super(_DenseLayer, self).__init__() self.add_module('norm1', nn.BatchNorm2d(num_input_features)), self.add_module('relu1', nn.ReLU(inplace=True)), self.add_module('conv1', nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False)), self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)), self.add_module('relu2', nn.ReLU(inplace=True)), self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)), self.drop_rate = drop_rate def forward(self, x): new_features = super(_DenseLayer, self).forward(x) if self.drop_rate > 0: new_features = F.dropout(new_features, p=self.drop_rate, training=self.training) return torch.cat([x, new_features], 1)
有了DenseLayer,就能用它來構建Dense Block。解釋一下一些引數的含義:growth_rate (int) - 代表每一層有多少個新的feature層新增進去 (paper裡面是k),num_input features(int) - 輸入的feature層數,num_layers(int)- 代表了Dense Block有多少層DenseLayers。
for迴圈就是根據num_layers逐層新增Dense Block注意每一層的輸入num_input features不一樣,是因為每一個DenseLayer之後feature的數目都會增加growth rate。直觀一點理解,其實就是每一層的DenseLayer附帶了自己學習到的feature還有自己本身一起傳入下一個DenseLayer。所以後面的輸出的結果會不斷的增加,下圖不能體現資料流動這一點,因為下圖不是資料本身,而是代表卷積層。
class _DenseBlock(nn.Sequential):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features + i * growth_rate, growth_rate, bn_size, drop_rate)
self.add_module('denselayer%d' % (i + 1), layer)
DenseBlock的結構可以看下圖。
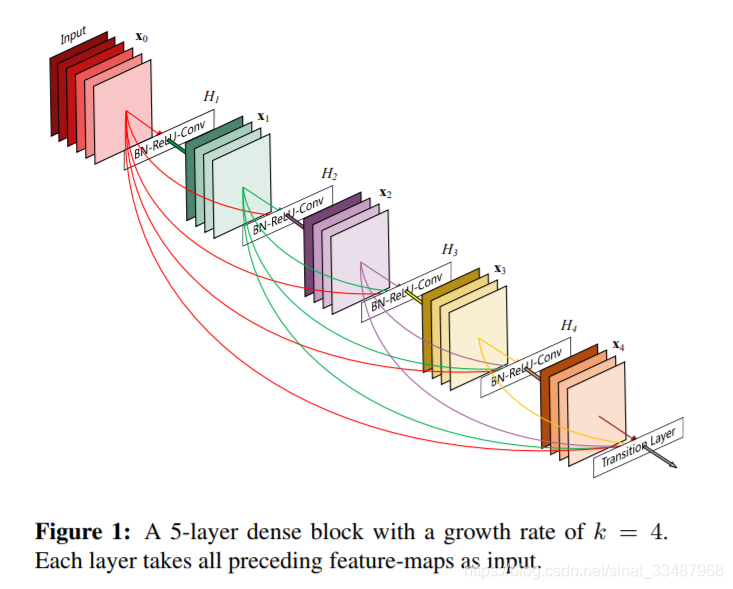
在Dense Block與Dense Block之間,論文添加了Transition層,這個層的作用是為了進一步提高模型的緊湊性,可以減少過渡層的特徵圖數量。這裡直接就把num_input_features壓縮成num_output_features,使用一層卷積實現的。
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module('norm', nn.BatchNorm2d(num_input_features))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
接下來就可以組合成一個DenseNet。DenseNet有不同的版本,不同版本之間可以參考論文給出結構:
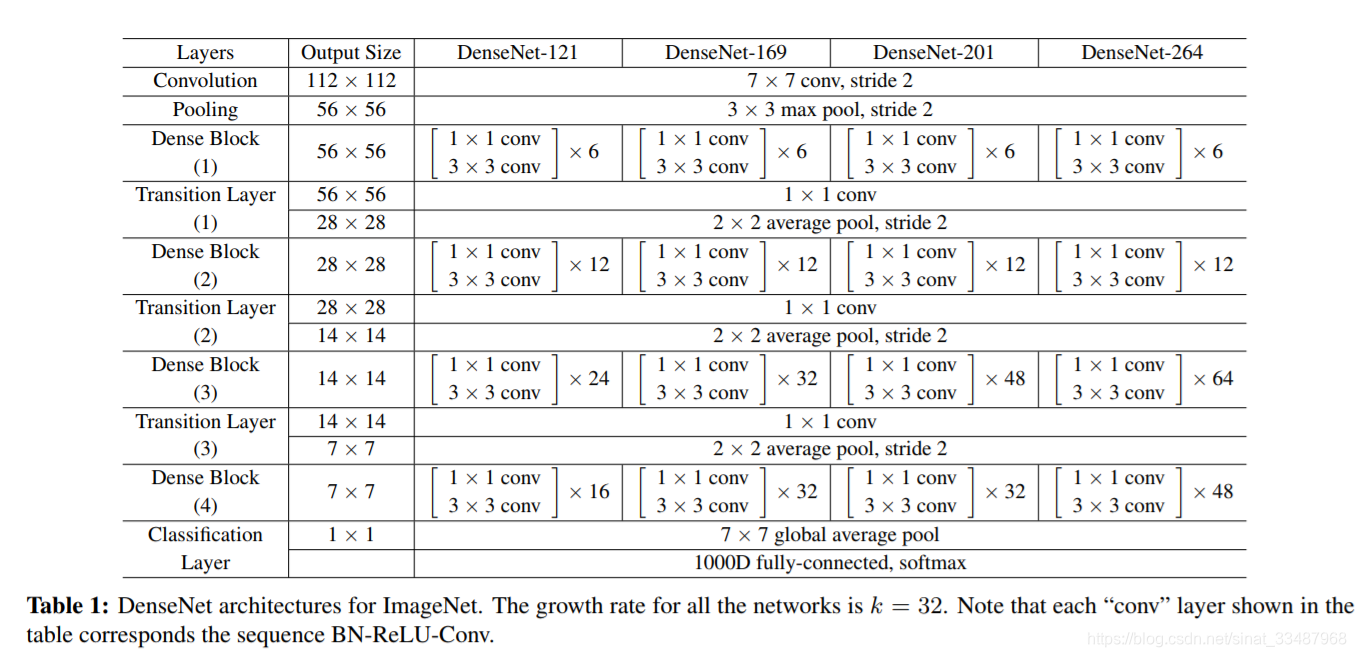
每個版本的共同特徵就是一開始是7*7的卷積和3*3的maxpooling,中間還加了batchnorm和relu,這部分都被寫進了OrderedDict裡。接著就要開始遍歷構造DenseBlock和Transition Layer,而不同版本的Dense Block每一層具體多少層Dense Layer,是由block_config(一個由4個整陣列成的列表)決定。
這裡關於Transition的操作,先判斷是否是最後一個DenseBlock(最後一個DenseBlock不需要,前面不同的DenseBlock需要Transition Layer),然後就新增一層Transition Layer,輸出是輸入feature的一半,這樣設定應該是根據實驗效果確定的。但直觀的理解就是這麼做之後不管我們多少層DenseBlock,最後輸出的資料都是緊湊的,不會無限增大它的厚度。
最後就是常規操作,新增batchnorm和一層線性分類器。後面還未每層的權重引數初始化,如果是卷積核,就使用kaiming_normal,具體可以參考pytorch官網。
class DenseNet(nn.Module):
r"""Densenet-BC model class, based on
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
growth_rate (int) - how many filters to add each layer (`k` in paper)
block_config (list of 4 ints) - how many layers in each pooling block
num_init_features (int) - the number of filters to learn in the first convolution layer
bn_size (int) - multiplicative factor for number of bottle neck layers
(i.e. bn_size * k features in the bottleneck layer)
drop_rate (float) - dropout rate after each dense layer
num_classes (int) - number of classification classes
"""
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16),
num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000):
super(DenseNet, self).__init__()
# First convolution
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
('norm0', nn.BatchNorm2d(num_init_features)),
('relu0', nn.ReLU(inplace=True)),
('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]))
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers=num_layers, num_input_features=num_features,
bn_size=bn_size, growth_rate=growth_rate, drop_rate=drop_rate)
self.features.add_module('denseblock%d' % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(num_input_features=num_features, num_output_features=num_features // 2)
self.features.add_module('transition%d' % (i + 1), trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.avg_pool2d(out, kernel_size=7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out那麼我們就來看看一個具體的版本是怎麼構建的:拿DenseNet121舉例,block_config=(6,12,24,16)就是上圖論文中的引數。pretrained是定義是否需要預訓練模型,這裡不必太在意他們是怎麼確定的,只要知道如果pretrained是True就返回一個已經訓練好的模型。
其他不同版本的DeseNet都大同小異,只是block_config的引數不同。這裡就不貼出來了。
def densenet121(pretrained=False, **kwargs):
r"""Densenet-121 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 24, 16),
**kwargs)
if pretrained:
# '.'s are no longer allowed in module names, but pervious _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = model_zoo.load_url(model_urls['densenet121'])
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
return model最後貼上原始碼:
import re
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo
from collections import OrderedDict
__all__ = ['DenseNet', 'densenet121', 'densenet169', 'densenet201', 'densenet161']
model_urls = {
'densenet121': 'https://download.pytorch.org/models/densenet121-a639ec97.pth',
'densenet169': 'https://download.pytorch.org/models/densenet169-b2777c0a.pth',
'densenet201': 'https://download.pytorch.org/models/densenet201-c1103571.pth',
'densenet161': 'https://download.pytorch.org/models/densenet161-8d451a50.pth',
}
def densenet121(pretrained=False, **kwargs):
r"""Densenet-121 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 24, 16),
**kwargs)
if pretrained:
# '.'s are no longer allowed in module names, but pervious _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = model_zoo.load_url(model_urls['densenet121'])
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
return model
def densenet169(pretrained=False, **kwargs):
r"""Densenet-169 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 32, 32),
**kwargs)
if pretrained:
# '.'s are no longer allowed in module names, but pervious _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = model_zoo.load_url(model_urls['densenet169'])
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
return model
def densenet201(pretrained=False, **kwargs):
r"""Densenet-201 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 48, 32),
**kwargs)
if pretrained:
# '.'s are no longer allowed in module names, but pervious _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = model_zoo.load_url(model_urls['densenet201'])
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
return model
def densenet161(pretrained=False, **kwargs):
r"""Densenet-161 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = DenseNet(num_init_features=96, growth_rate=48, block_config=(6, 12, 36, 24),
**kwargs)
if pretrained:
# '.'s are no longer allowed in module names, but pervious _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = model_zoo.load_url(model_urls['densenet161'])
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
return model
class _DenseLayer(nn.Sequential):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module('norm1', nn.BatchNorm2d(num_input_features)),
self.add_module('relu1', nn.ReLU(inplace=True)),
self.add_module('conv1', nn.Conv2d(num_input_features, bn_size *
growth_rate, kernel_size=1, stride=1, bias=False)),
self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module('relu2', nn.ReLU(inplace=True)),
self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)),
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)
class _DenseBlock(nn.Sequential):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features + i * growth_rate, growth_rate, bn_size, drop_rate)
self.add_module('denselayer%d' % (i + 1), layer)
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module('norm', nn.BatchNorm2d(num_input_features))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
class DenseNet(nn.Module):
r"""Densenet-BC model class, based on
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
growth_rate (int) - how many filters to add each layer (`k` in paper)
block_config (list of 4 ints) - how many layers in each pooling block
num_init_features (int) - the number of filters to learn in the first convolution layer
bn_size (int) - multiplicative factor for number of bottle neck layers
(i.e. bn_size * k features in the bottleneck layer)
drop_rate (float) - dropout rate after each dense layer
num_classes (int) - number of classification classes
"""
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16),
num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000):
super(DenseNet, self).__init__()
# First convolution
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
('norm0', nn.BatchNorm2d(num_init_features)),
('relu0', nn.ReLU(inplace=True)),
('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]))
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers=num_layers, num_input_features=num_features,
bn_size=bn_size, growth_rate=growth_rate, drop_rate=drop_rate)
self.features.add_module('denseblock%d' % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(num_input_features=num_features, num_output_features=num_features // 2)
self.features.add_module('transition%d' % (i + 1), trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.avg_pool2d(out, kernel_size=7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out