
Linux的Netfilter框架深度思考-對比Cisco的ACL-
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
在前面
0.1.本文不涉及具體實現,也不涉及原始碼,不剖析程式碼
0.2.本文不爭辯Linux或者Cisco IOS不同版本之間的實現細節
0.3.本文不正確處請指出
Cisco無疑是網路領域的領跑者,而Linux則是最具活力的作業系統核心,Linux幾乎可以實現網路方面的所有特性,然而肯定還有一定的優化空間,本文首先向Cisco看齊,然後從不同的角度分析Netfilter的對應特性,最終提出一個ip_conntrack的優化方案。
0.4.昨天女兒出生,她不哭也不鬧,因此才能整理出這篇文件,這幾天累壞了,但還是撐著整理了這篇文件
1.設計的異同
Netfilter是一個設計良好的框架,之所以說它是一個框架是因為它提供了最基本的底層支撐,而對於實現的關注度卻沒有那麼高,這種底層支撐實際上就是其5個HOOK點:
PREROUTING:資料包進入網路層馬上路由前
FORWARD:資料包路由之後確定要轉發之後
INPUT:資料包路由之後確定要本地接收之後
OUTPUT:本地資料包傳送(詳情見附錄4)
POSTROUTING:資料包馬上發出去之前
1).HOOK點的設計:
Netfilter的hook點其實就是固定的“檢查點”,這些檢查點是內嵌於網路協議棧的,它將檢查點無條件的安插在協議棧中,這些檢查點的檢查是無條件執行的
2.資料流的異同-僅考慮轉發情況
1).對於Cisco,資料包的通過路徑如下: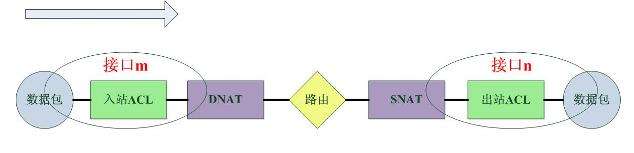
2).對於Linux的Netfilter,資料包的通過路徑如下: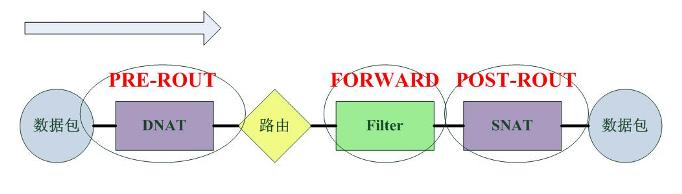
3.效率和靈活性
3.1.過濾的位置
從資料流的圖示中可以看出Netfilter的資料包過濾發生在網路層,這實際上是一個很晚的時期,從安全性上考慮,很多攻擊-特別是針對路由器/伺服器本身的Dos攻擊-此時已經形成了,一個有效的預防方式就是在更早的時候丟棄資料包,這也正是Cisco的策略:“在儘可能早的時候丟棄資料包”。而Cisco也正是這麼做的,這個從上面的圖示中可以看出。Cisco的過濾發生在路由之前。
3.2.過濾表的條目
由於Netfilter是內嵌在協議棧中的全域性的過濾框架,加之其位置較高,很難對“哪些包應該匹配哪些策略”進行區分,而Cisco的ACL配置在網絡卡介面,並且指定了匹配資料包的方向,因此通過區分網絡卡介面和方向,最終一個數據包只需要經過“一部分而不是全部”的策略的匹配。比如從Ether0進入的資料包只會匹配配置在Ether0上入站方向的ACL。
3.3.NAT的位置
Netfilter的NAT發生在filter之前和之後,而Cisco的nat也發生在filter之中,這對二者filter策略的配置有很大的影響,對於使用Netfilter的系統,需要配置DNAT之後或者SNAT之前的地址,而對於Cisco,則需要配置DNAT之前或者SNAT之後的地址。
3.4.配置靈活性
3.4.1.Cisco的acl配置很靈活,甚至“配置到介面”,“指明方向”這一類資訊都是外部的,十分符合UNIX哲學的KISS原則,但是在具體的配置上對工程師的要求更高一些,他們不僅僅要考慮匹配項等資訊,而且還要考慮介面的規劃。
3.4.2.Netfilter的設計更加整合化,它將介面和方向都統一地整合在了“匹配項”中,工程師只需要知道ip資訊或者傳輸層資訊就可以配置了,如果他們不關心介面,甚至不需要指明介面資訊,實際上在iptables中,不使用-i和-o選項的有很多。
4.Netfilter優化
4.1.防火牆策略查詢優化
4.1.1.綜述
傳統意義上,Netfilter將所有的規則按照配置的順序線性排列在一起,每一個數據包都要經過所有的這些規則,這大大降低了效率,隨著規則的增加,效率會近似線性的下降,如果能讓一個數據包僅僅通過一部分的規則的匹配就比較好了。這就是說,我們要對規則進行分類,然後先將過往的資料包用高效的演算法匹配到一個特定的分類,然後該資料包只需要再繼續匹配該分類中規則就可以了。
分類實際山很簡單,它基於一個再簡單不過的解析幾何事實:在一條線段上,一個點將整個線段分為3部分: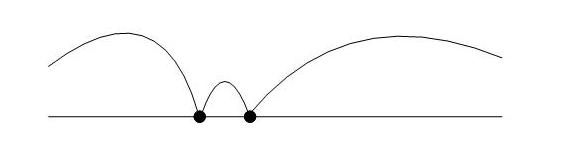
因此,任何一個匹配項都可以歸結為一個所謂的“鍵值”,在該鍵值空間中,一定有某種順序可供排序,那麼一個鍵值,就能將這個鍵值空間分為三個部分:大於,等於,小於。一維空間如此,N維空間亦如此,只是更精確,這裡N是我們挑選出來的匹配域。為了更好的理解下面的論述,先給出兩幅圖。傳統意義的防火牆規則匹配操作如下圖所示,它是平坦的:
而優化後的防火牆規則匹配操作如下圖所示,它是分維度的: 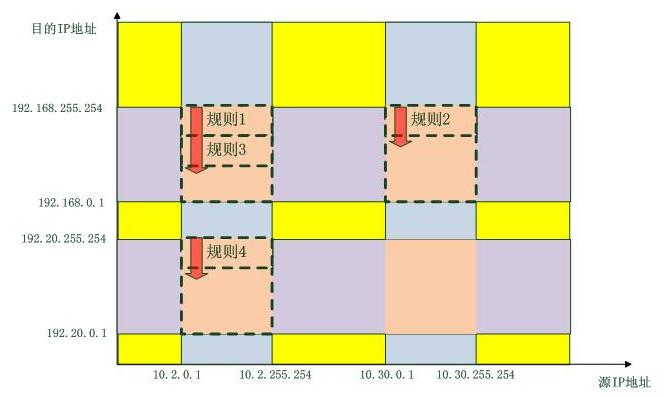
最終,只有虛線所圍的區域有規則要匹配,只有資料包“掉進了”這些區域,才需要匹配規則,否則全部按照“策略”行事。當然,一個數據包不可能掉進兩個區域。這裡只考慮了源IP地址和目的IP地址這種二維的情形,如果加上第四層協議,埠等資訊維度,匹配就更加精確了,並且,只要使用的“類”匹配演算法足夠精巧,操作是不會隨著規則的增加而增加的,而這一部分內容正是我們馬上就要討論的內容
4.1.2.Cisco的優化策略
很多用過Cisco的人都知道,Cisco有一個叫做Turbo ACL的概念,這個Turbo ACL的要旨就是“不再用規則匹配資料包,而成為了使用資料包的資訊查詢需要匹配它的規則”。這就意味著在ACL插入系統的時候就要對其進行排序,然後資料包進入的時候,通過資料包的資訊去查詢排過續的規則集。
想了解Cisco的技術細節,直接瀏覽其官方網站的Support是很有必要的,這裡有最直接的講述,Cisco的技術Support有一個很好的地方,那就是它有情景分析。我下面就用那上面的例子來進行分析,基本上基於一篇文件:《TURBO ACL》。
Turbo ACL定義了一系列的匹配域,如下圖所示: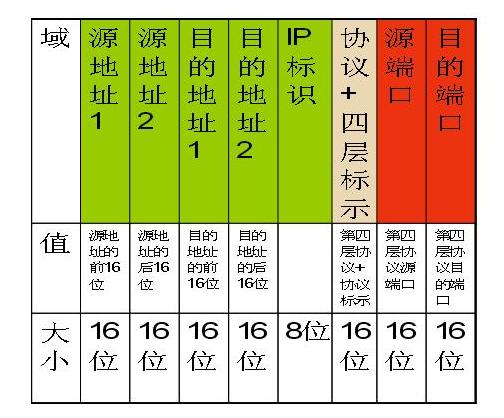
其中綠色的表示三層資訊,紅色的表示四層資訊,粉色的表示第三層+第四層的資訊。針對於每一個匹配域,都存在一個表,我們稱為“值表”:
其中索引是為了查詢和管理方便,而值則被填入規則中對應該表的匹配域的值,ACL點陣圖指示該表的該記錄匹配哪些ACL。因此,對於所有的匹配域,由於一共有8個匹配域,那麼就有8個這樣的表。為了更加容易理解,給出一個例子,首先看4條acl規則:
#access-list 101 deny tcp 192.168.1.0 0.0.0.255 192.168.2.0 0.0.0.255 eq telnet
#access-list 101 permit tcp 192.168.1.0 0.0.0.255 192.168.2.0 0.0.0.255 eq http
#access-list 101 deny tcp 192.168.1.0 0.0.0.255 192.168.3.0 0.0.0.255 eq http
#access-list 101 deny icmp 192.168.1.0 0.0.0.255 200.200.200.0 0.0.0.255
這些規則填入匹配域表格後,匹配域表格如下: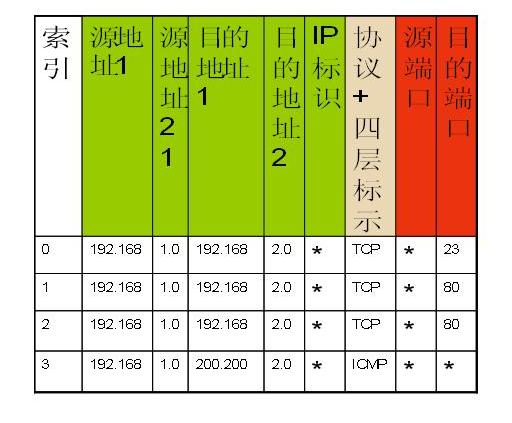
然後僅給出一個“源地址1”的值表:
到此為止,我們已經給出了所有的靜態的資料結構,接下來就是具體的動態操作了,歸為一種演算法。Cisco的規則匹配演算法是分層次的,並且是可並行運算的,因此它的效率極其高效,整個演算法分為兩大部分:
1).資料包基於所有匹配域的點陣圖查詢
這個步驟是可以並行的,比如可以同時在兩個處理器上查詢“源地址1”的值表和“源地址2”的值表,從而最大化CPU利用率,以最快的速度得到兩個點陣圖,演算法對於採用何種查詢演算法沒有規定,取決於新增ACL時如何將匹配域的值插入對應值表。另外,哪種查詢快用哪種,這是不爭的事實,我們一般很少有動態插入的,一般都是靜態插入的,因此對資料插入的效能要求並不高,關鍵要素是查詢。這個查詢演算法的查詢效率非常重要,好的演算法如果是O(1)的,那就意味著匹配規則的過程消耗的時間不會隨著規則的增加而增加,事實上即使是O(n)的查詢演算法, 也將N次的匹配操作轉化為了按照一個比例小得多的a*N次的查詢操作,往往a是一個很小的且小於1的數字...
2).多個位圖多次的AND操作
取多個結果的交集,最終得到一條或者幾條ACE。這種點陣圖的演算法是Cisco慣用的用空間換時間的策略,傳說中的256叉樹使用的也是這樣的策略。
下面給出操作的流程圖: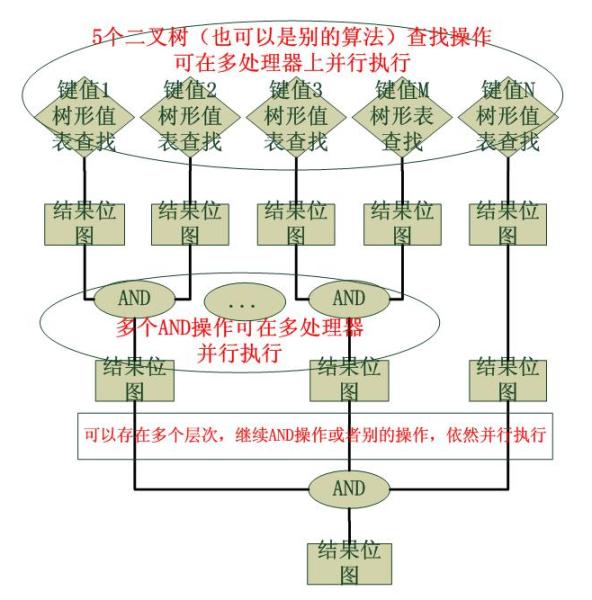
作為一個情景分析,我們考慮一個數據包到來,它的匹配域的值如下:
源地址1 : 192.168
源地址2 : 1.1
目的地址1 : 200.200
目的地址2 : 200.1
四層協議 : 0001 (ICMP)
針對此包的操作流程圖如下,假設僅有上述舉例的acl可用: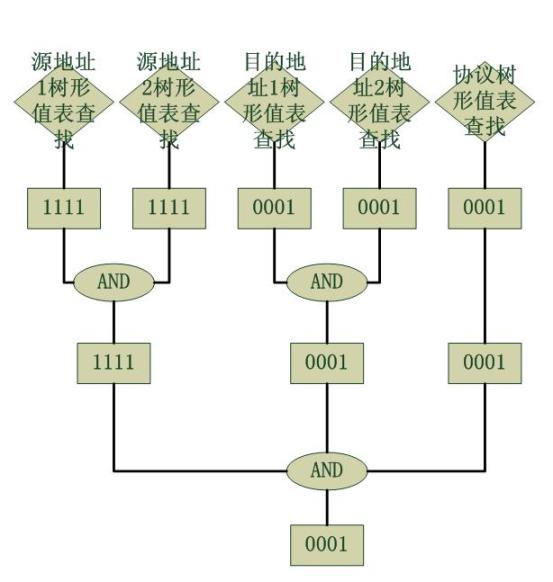
最終得到了0001,也就是僅有最後一條規則是匹配的。
這樣我們就結束了Turbo ACL的討論,接下來就要看看Linux的Netfilter有沒有什麼對等的優化策略
4.1.3.Netfilter的filter優化策略
Netfilter有一個專案,叫做nf-HiPAC,它的程式碼極端複雜,文件極端稀缺,功能相比iptables更加有限,加之Linux面對巨量規則的需求不多,因此HiPAC的受用性不高,然而從理論的角度去分析一下它也是有好處的。雖然啃HiPAC的程式碼是一件很恐怖的事情,然而瀏覽一下它並不很難,最終我們發現,它的實現和Turbo ACL基本是一致的,也是基於資料包首先匹配匹配域從而先得到分類,它使用了幾乎相同然而更多一些的匹配域,和Turbo ACL不同的是,它沒有使用點陣圖,因為Linux可能不允許以空間換時間,呵呵...
HiPAC沒有使用點陣圖,這是因為它根本不需要點陣圖,因為Cisco並行的同時得到了所有匹配域值表的點陣圖,因此只要將它們AND,就能得到最終結果,可是HiPAC並不是並行操作的,而是序列的,HiPAC對於每一個匹配域也有一個值表,由於一系列的匹配域按照一定的順序排列好,比如:源地址-目的地址-協議-源埠-目的埠,因此其值表也有這樣的串接關係,見下面:
在找到目的地址的匹配之前,是不會匹配協議以及後面的匹配域的。具體的規則掛接在最後的匹配域值表中。HiPAC並沒有保留原始的配置規則,然後通過點陣圖找到它們,而是直接將規則掛接在了它“應該在”的位置。一個HiPAC的流程圖如下: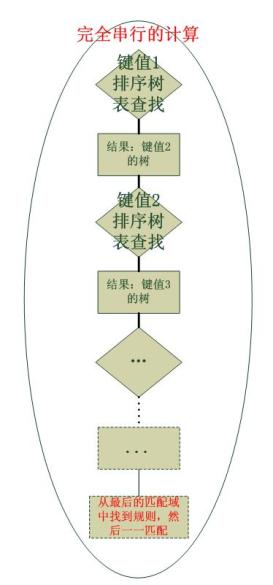
4.1.4.Cisco和Netfilter的對比
它們使用的查詢演算法十分一致,然而具體的操作卻大相徑庭,我們看到Cisco完全是在並行的處理,而Netfilter則一串到底。如果形象的理解,我們可以將整個操作比作在一個多維空間查詢一個點。有兩種方式:
1).N個維度同時向前推進,最終找到它們路徑的相交區域;
2).先在第一個維度匹配,然後再匹配第二個維度...
我們發現,Cisco使用了第一個方法,而Netfilter使用了第二個。我想Netfilter不使用並行方式的原因有二:第一,Netfilter一般應用於Linux,而Linux是一個通用的作業系統,對於協議棧的支援只是其一部分功能而已,如果為協議棧引入並行機制,勢必會造成一種不均衡的態勢。第二,Linux一般情況下不會有成千上萬的防火牆條目,而上述的優化演算法在規則條目越多的情形下效果越明顯。另外,對於Netfilter的nf-HiPAC的查詢機制,又使得我想起了Linux的頁表查詢和路由表的trie樹查詢演算法。
4.2.ip_conntrack優化
Netfilter的ip_conntrack模組實現了連線跟蹤的功能,然而這個實現我總覺得有個美中不足的地方。那就是它對於IP分片的處理,Netfilter的ip_conntrack對於分段的處理就是合併分段,理由就是IP層是無連線的,而IP分段則無法得到第四層資訊,因此為了得到第四層資訊,必須等待所有分段到達,然後才能繼續處理。這是個理由,並且說的很充分,然而我個人認為這肯定還是可以再優化的,我們可以再做一個層次來解決這件事,正如我們“僅僅保留一個流的五元素就能識別一個數據包是否屬於該流”一樣,我們也能為一個ip資料報保留一個“源ip/目的ip/協議/三層id”四元素,這四個元素唯一確定一個ip資料報(理由見附錄),我們僅僅需要用一個ip分片匹配這四元素就能確定它屬於哪個ip初始分片,而這也就知道了它屬於哪個流,當然僅僅針對分段資料報保留這四元素即可,但是由於ip是不保證順序的,如果到來的一個ip分片不是第一個分片,那怎麼辦?這個很簡單,那隻能等,等待第一個分片到來,得到四元素資訊,然後再處理。
這裡給出一個流程圖,原因是也只能給出這個圖了,這篇文件是在醫院寫的,我家小小估計快要出生了...回頭有時間再改程式碼吧,如果哪位大俠看了,覺得有點意思並且感興趣的話,請一定嘗試一下,然後給核心的Netfilter組提交一個patch,小弟在此大謝:

總之,nf-HIpac,採用序列(可以修正為並行)多維樹查詢演算法,源於一種包分類演算法,不再是規則匹配包,而成為了包尋找規則。維度的增加,約束相應增加,定位就更準確。查詢所需的時間不管怎樣要比依次匹配規則的時間更少,最終,最多隻有一部分規則參與抉擇。
4.3.基於優化後ip_conntrack的有狀態防火牆
既然ip_conntrack被優化了,那它就不會為ip分片所累了(其實它原來就不會為其所累)。基於ip_conntrack實現一個有狀態防火牆也不是一件難事,ip_conntrack中保留著該流第一個包到達時的資料包經過filter表時的匹配策略,具體來講就是一個target,然後對於後續的包都直接按照這個target來執行。
然而這種防火牆究竟和HiPAC相比有何不同的,這種防火牆在PREROUTING時去匹配流,第一個資料包還在在filter中匹配規則,而HiPAC只需要在filter中匹配規則即可,對於大量連線而言,流匹配肯定會慢,然而如果有大量規則,HiPAC不會降速的,這正是它的優勢所在,正和Cisco的Turbo ACL一樣。
5.一個細節-防火牆對IP分片的處理
5.1.問題之所在
在RFC1858中指明瞭兩類ip分片的攻擊
1).TCP小包攻擊
對於這類攻擊,很容易理解,首先給出一個IP資料報分片的第一個片: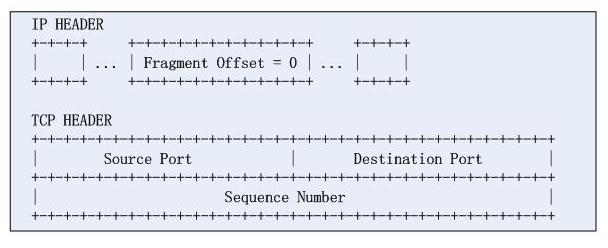
然後再看第二個片: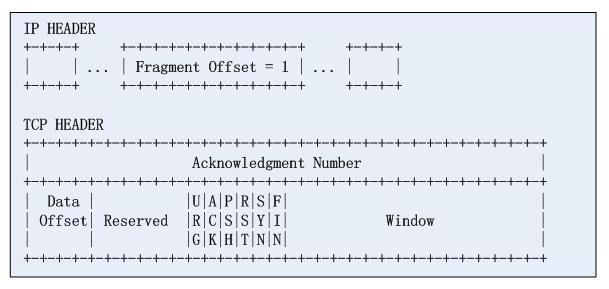
分片的offset欄位指示了tcp載荷的偏移,這樣,攻擊者認為防火牆無法識別分段的第四層資訊,從而成功的繞過了防火牆的檢測,攻擊要點在於,將一個完整的TCP協議頭硬拆成兩段,咋可好!。實際上很長一段時間,Cisco的ACL只要匹配到資料報分片的第三層資訊並且規則是permit,那麼是一律放過的。實際上,RFC1858中給出瞭解決方案,需要限制TCP載荷分片的最小值,這也是RFC的建議(然則Cisco並不一定遵守)。
2).TCP重疊攻擊(依賴重組演算法)
和1)相比,這是一種間接的攻擊方式,請看第一個IP分片: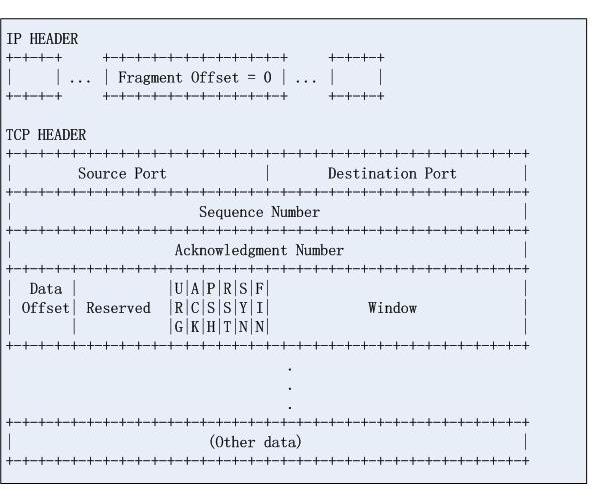
再看第二個分片:
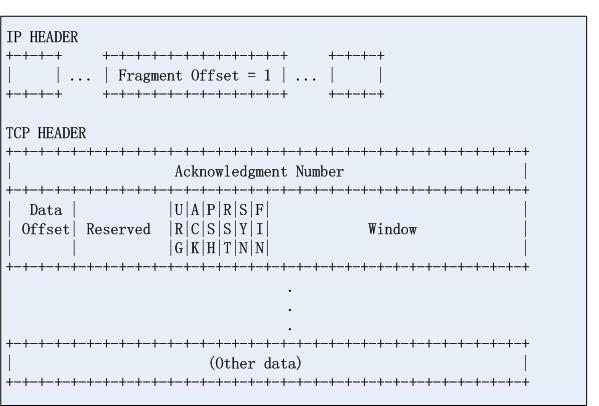
我們看到第一個都是正常的,只是第二個不正常,如果目的地主機的IP分片的合併演算法有問題,第二個分片的資訊就會覆蓋掉第一個分片的tcp協議頭資訊,由於過濾規則無法從IP分段中獲取四層資訊,因此資料輕鬆繞過防火牆,從而實施攻擊。標準並沒有規定IP分片合併的具體約束,這是導致這個攻擊得意存在的根本原因。
5.2.Cisco的處理
Cisco處理IP分片完全採用一種統一的方式,將是否允許其通過這件事完全交給了配置工程師們,它的流程圖如下所示,流程圖顯示單個數據包匹配ACE的情形: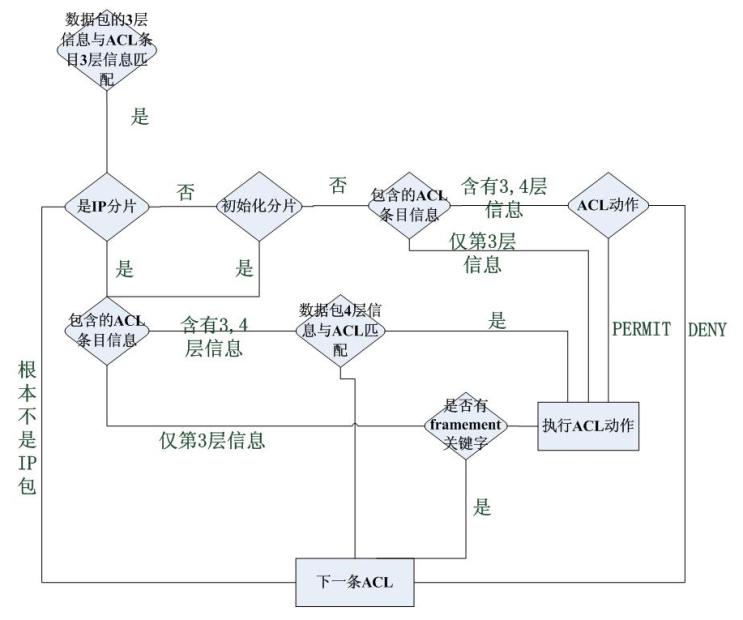
Cisco的工程師必須顯示配置哪些分片不能通過。然而Cisco的IOS的新版本還是限制了RFC1858中提到的攻擊分片的通過
5.3.Netfilter的處理
Netfilter直接禁止了RFC1858中提到的攻擊分片的通過,流程圖就不畫了,給出一段程式碼即可:
- static int
- tcp_match(const struct sk_buff *skb,
- const struct net_device *in,
- const struct net_device *out,
- const void *matchinfo,
- int offset,
- int *hotdrop)
- {
- struct tcphdr tcph;
- const struct ipt_tcp *tcpinfo = matchinfo;
- if (offset) {
- if (offset == 1) {
- duprintf("Dropping evil TCP offset=1 frag./n");
- *hotdrop = 1; //不允許這樣的包通過
- }
- return 0;
- }
- ...
- }
另外,Netfilter對於非第一個的IP分片,對於高於網路層的一切匹配項一律命中匹配,比如來了一個ip分片,對於tcp/udp的埠資訊,一律匹配,然後直接執行target,這和Cisco的策略是不一樣的,這一點從其流程圖中可以看出來。
5.4.對比
不管是Cisco還是Netfilter,它們都將匹配項分為了兩類,一類是隱含的匹配項,這些項只包含三層資訊,另一類是明確匹配項,這類匹配項包含更高層的資訊-對於Linux的Netfilter而言,這類隱含匹配項不需要註冊,而明確匹配項需要註冊,Cisco的方式未知,但是猜測不是這樣的,應該都需要或者都不要註冊。對於Netfilter的filter和Cisco的ACL,都是在隱含匹配項匹配的基礎上才匹配明確匹配項的,可以參見Cisco處理ACL的流程圖以及Linux核心的Netfilter程式碼:
- do {
- //判斷是否和隱含匹配項匹配,offset指示是否為ip分片
- if (ip_packet_match(ip, indev, outdev, &e->ip, offset)) {
- 針對每一個明確匹配項進行匹配,只要只要有一個不匹配,則跳到not-match,否則執行target。由於幾乎所有註冊的match對於ip分片都直接返回“匹配”,所有IP分片只需匹配隱含匹配則就算是匹配了。
- } else {
- not-match:
- 下一條規則
- }
- } while (還有其它規則)
6.總結
站在一個比較高的層面上仔細觀測Linux和Cisco IOS的網路設計,IOS的優勢更多的在於它將幾乎所有的精力都用到了網路方面,IOS的核心機制實際上要比Linux的簡單得多,然而它依託於一個總體的良好設計,使得幾乎任何事情都可以被配置出來,在IOS中,任何策略都是配置出來的,雖然它有一個預設配置檔案,然而那也是配置出來的。
而Linux的做法就完全不同,Linux的網路策略實際上是Netfilter和硬編碼的結合,在Linux核心中(網路方面的程式碼),我們可以看到很多註釋,這些註釋大多數是Alan Cox新增的,很多都是說“為了遵循RFCXXXX...”。當然,這種硬編碼也是可以配置的,比如使用sysctl工具,然而它不能使用一個統一的工具來配置,比如你不能使用ip命令開啟ip_forward...
我知道,使用Netfilter可以實現幾乎Cisco IOS的所有功能,並且也可以做和IOS類似的優化,這正是Netfilter框架的優越性所在,然而雖然從外部看起來是一樣的,但是要明白其實質是有很大差別的,另外Linux沒有必要追趕Cisco IOS,這是沒有意義的,即使做得比Cisco好,我相信大部分人還是會買Cisco的,因為市場的競爭中技術因素只佔很小的一部分份額,正如很多人都在大搞Linux的Windows的相容,這有必要嗎,在Windows中有個登錄檔,Linux中就一定要有類似的嗎?一切安好,在純技術領域的討論如果放到整個產品層面就會認為是倔強和頑固。
Netfilter框架設計的很好,每一個細節都值得細細品味,使用它,理解它,修改它,優化它,完善它,使用它...這是一個很不錯的學習過程,你也可以試試。
附錄
0.Netfilter到底屬於誰?
0.1.Netfilter是一個框架,它是獨立於Linux核心的,它有自己的網站:http://www.netfilter.org/
0.2.Netfilter擁有幾乎無限的可擴充套件性,Liuux中使用的僅僅是它的一個很小的部分,大部分的內容作為可插拔的module處於待命狀態
0.3.Netfilter的機制整合在Linux核心中,然而它的策略擴充套件卻處於一個獨立的空間,我們說這種所謂的機制也僅僅是5個HOOK點。我們瀏覽netfilter.org就會知道,它裡面融合了大量的策略,我們最熟悉的就是iptables了。上述提到的HiPAC也是Netfilter的擴充套件之一
0.4.足以看出,Netfilter有多強大,核心僅僅給出鉤子點而已。如果你嫌某些不好,你可以自己實現一個更好的
0.5.事實上,Netfilter中有很多的東西並沒有整合在Linux核心。
1.一幅圖:資料包的核心路徑圖
為了給出Linux核心中Netfilter的全景,給出一幅圖,圖中詳細標示了其各個部分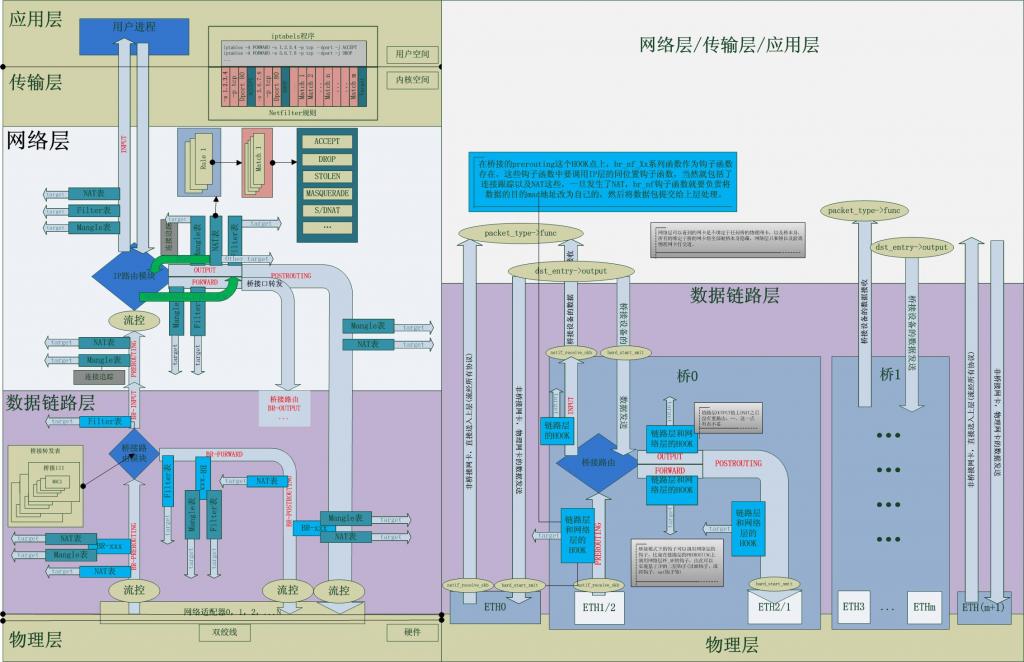
2.ip_conntrack優化中使用四元素的理由:
ip層給出了4元素,明確跟蹤了一個IP資料報,實際上TCP/IP的每一個層次的協議頭都會提供一些該層PDU的跟蹤資訊,由於IP層是基於報文的,因此其跟蹤資訊完全標示一個IP資料報,一個分片的IP資料報的所有報文片段的這些跟蹤資訊相同。理解這一點十分簡單和直接,正如TCP/UDP協議的埠號資訊加上更低層次的跟蹤資訊就能標示一個流一樣-一個流標示一個會話,有很多的資料報組成。在RFC791(非常非常重要的IP協議RFC)中,明確的指明瞭這一點,《tcp/ip詳解》中也指示了這一點:
“標識欄位唯一地標識主機發送的每一份資料報。通常每傳送一份報文它的值就會加1。”“RFC 791 [Postel 1981a]認為標識欄位應該由讓IP傳送資料報的上層來選擇。假設有兩個連續的IP資料報,其中一個是由TCP生成的,而另一個是由UDP生成的,那麼它們可能具有相同的標識欄位。儘管這也可以照常工作(由重組演算法來處理),但是在大多數從伯克利派生出來的系統中,每傳送一個IP資料報,IP層都要把一個核心變數的值加1,不管交給IP的資料來自哪一層。核心變數的初始值根據系統引導時的時間來設定。”《TCP/IP詳解(第一卷)》
3.conntrack-tools
首先宣告:這不是Linux的錯!也許,有時候,你的iptables規則清除了,然而資料包地址轉換還在進行。這是ip_conntrack的chache引起的,然而這並不是問題,只要能使用工具解決的事情都不是問題,這個問題也能用工具解決,這個工具就是conntrack-tools,它能在任意時間刪除任意的ip_conntrack的cache,具體怎麼用,教你:1.下載;2.安裝;3.man
4.Netfilter的HOOK點之OUTPUT位置設計
Netfilter中output這個hook點比較特殊,按照常理,output應該設計在路由前的,這也符合過濾儘量在早期發生的原則,然而我們發現Netfiler的output鏈卻在路由之後,這裡面到底有什麼蹊蹺呢?
4.1.output鏈在路由之後,側重於“到底是容易被過濾還是容易沒有路由”
4.2.過濾發生在路由之後,權衡點在於“可能沒有路由還是可能被drop”。
4.3.skb的output函式是個回撥函式,而這個回撥函式是根據路由的結果以及路由策略設定的,因此最好將output鏈設置於路由之後,這樣就可以將ip的傳送函式簡單的寫成:
- int __ip_local_out(struct sk_buff *skb)
- {
- struct iphdr *iph = ip_hdr(skb);
- iph->tot_len = htons(skb->len);
- ip_send_check(iph);
- return nf_hook(PF_INET, NF_INET_LOCAL_OUT, skb, NULL, skb->dst->dev,
- dst_output);
- }
- static inline int dst_output(struct sk_buff *skb)
- {
- return skb->dst->output(skb);
- }
注意,以上的dst是根據路由查詢的結果初始化的。將DNAT掛在OUTPUT鏈上是沒有問題的,因為DNAT改變了目的地址後,會重新路由,然後就會重新初始化dst欄位,新的output函式也將獲得。Netfilter將output確定在了路由之後以及在output上實施dnat保證了必定在路由之後確定skb的dst欄位,否則dsk欄位不確定的話,nf_hook函式就不好寫了。
總結起來就一點,Linux的IP層往下的傳送例程是“路由查詢結果”決定的,因此只有在路由查詢之後才可確定傳送函式,才可以掛載繼續傳送的鉤子。
5.Cisco IOS/H3C VRP/GNU Linux
04年那年,接觸了華三的裝置,隨後又使用了Cisco的,大概2年後,我看到Linux的shell介面時,我還以為這是Cisco呢...IOS和VRP的操作介面很類似,它們都屬於核心網路裝置這一塊,側重於核心路由和防火牆,配置可以很難,但是一定要靈活,迎合各種需求,無可非議,VRP借鑑了Cisco-雖然它的核心是BSD化的,Linux屬於一個通用作業系統,核心網路不是它的應用場合。
6.預防IP欺騙的基於RFC2827經典配置
(1) 任何進入網路的資料包不能把網路內部的地址作為源地址。
(2) 任何進入網路的資料包必須把網路內部的地址作為目的地址。
(3) 任何離開網路的資料包必須把網路內部的地址作為源地址。
(4) 任何離開網路的資料包不能把網路內部的地址作為目的地址。
(5) 任何進入或離開網路的資料包不能把一個私有地址(Private Address)或在RFC1918中列出的屬於保留空間(包括10.x.x.x/8、172.16.x.x/12 或192.168.x.x/16 和網路回送地址127.0.0.0/8.)的地址作為源或目的地址。
(6) 阻塞任意源路由包或任何設定了IP選項的包。
給我老師的人工智慧教程打call!http://blog.csdn.net/jiangjunshow
