
為什麼NVIDIA NVENC 硬體H.264編碼器對XD和Horizon如此重要
本文翻譯自Magnar Johnsen的一篇文章,該文章論述了在Citrix XenDesktop和VMware Horizon解決方案中,如果使用了NVIDIA GRID card的NVENC的功能,那麼對於使用3D軟體的使用者來說,無論是效能還是使用者體驗,都有較大的提升。根據個人理解翻譯,如有理解不對的地方,還請指正。謝謝!
原文如下:https://www.virtualexperience.no/2016/09/20/why-nvidia-nvenc-hardware-h-264-encoder-is-important-for-citrix-xendesktop-and-vmware-horizon/
Nvidia Grid顯示卡本身內建了H.264硬體編碼器。藉助Citrix XenDesktop和VMware Horizon的產品,你可以利用此功能對H.264協議流進行硬體編碼。為何如此智慧呢?如果想理解這個問題,那你首先得搞明白“點選光子時間”這個概念。這個時間是指當你按下滑鼠按鈕到你看到螢幕更新的時間。這整個過程花費的時間取決於你的網速,但也還有其它的因素。請參考下面的圖幫助理解一下: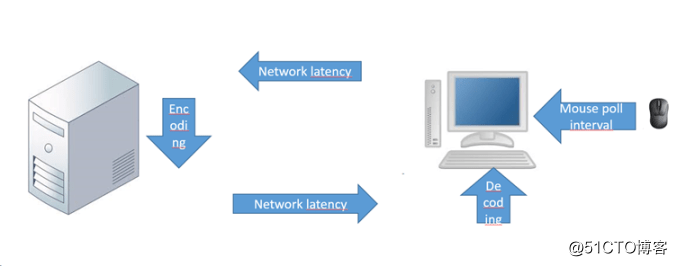
點選光子時間取決於上圖中標註的所有因素,另外還包括計算機硬體的延時。對於計算機顯示方面,或許有幾毫秒的延時。
以一臺本地電腦作為參考,一般點選光子時間大約有65毫秒,在這裡沒有網路和編碼/解碼延時的影響。一個PCoIP的會話,它的點選光子時間大約是215毫秒,所以大約150毫秒是消耗在LAN網路上。對於影象應用程式,移動圖片,翻看文件和網頁,肉眼可見的,據說低至120毫秒的話,成年人就感到有延時了,年輕人大概在100毫秒。
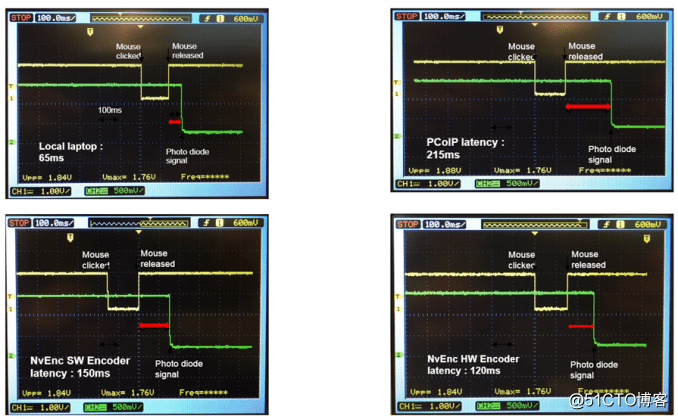
如想了解更多關於關於點選光子的內容,請參考此連結:http://www.virtualexperience.no/2016/03/07/how-to-use-click-to-photon-to-measure-end-to-end-latency/
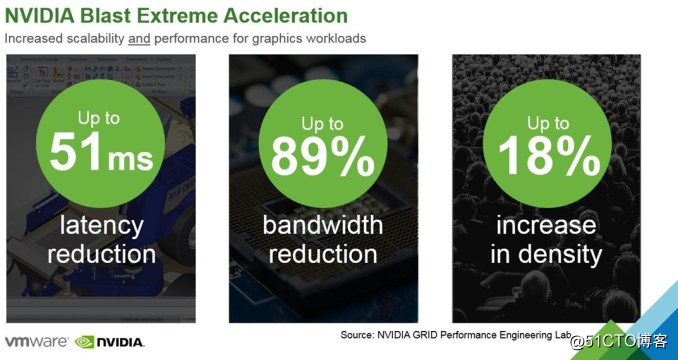
利用NVIDIA NVENC功能,這個時間將減少大約50毫秒。這個已經在VMWare Blast Extreme 測試過了,現在Citrix XenDesktop 7.11也同樣能實現。這意味著使用者將得到更好的使用者體驗,或者說在不減少點選光子時間情況下,可以允許你的WAN連結多50毫秒的延時。為什麼硬體編碼比軟體編碼速度更快?因為GPU是並行處理而CPU是序列處理。
另外一個好處就是伺服器使用H.264協議編碼時,可以減少CPU時間。
我還寫了另外一篇文章,是關於在啟用H.264硬體解碼的客戶端,使用Autocad時如何減少點選光子時間,外加增加FPS速度和滑鼠輪詢縮短了點選光子時間。
為什麼從協議層面上增加FPS可以減少點選光子時間呢?那是因為16FPS流在每個zhen之間有約1000ms/16 = 62.5ms,所以這個時間相當於點選光子時間。如果你把FPS增加到60,那每幀之間只有大約16.7ms,所以這裡幾乎可以減少50ms的延時。但是增加FPS需要更多的頻寬,所以不推薦WAN連結方式使用。這也會增加H.264編碼和解碼的負荷,這也是為什麼GPU硬體編碼和解碼會讓你在不增加伺服器和客戶端負荷的情況下,可以使用更多的FPS。
下面是一個16FPS~60FPS的一個區別動圖,供大家參考一下,對不同的FPS有一個更直觀的認識。

我已經做過虛擬VR的實驗,就是像HTC Vive和Oculus Rift的應用程式跑在遠端桌面一樣。在這種場景下,你需要更短的點選光子時間或者說光子運動時間,以避免有眩暈的感覺。為了達到這個目的,我希望將來遠端協議可以支援更高的FPS。當然你也需要更強大的GPU,底延時和高頻寬。
所以我的建議是:如果你要為將來建立一個VDI平臺,在移動內容上讓使用者得到更好的使用者體驗,所以一臺啟用GPU的VDI是必須的。如果你選擇NVIDIA GRID卡,那你不但能得到GPU視訊和影象加速,還可以利用NVENC得到更好的可擴充套件性和點選光子時間。目前,
Nvidia Grid M60 支援 36 個H.264 併發流,M10 擁有28個.