
《Inception V3-Rethinking the Inception Architecture for Computer Vision》論文筆記
1. 論文思想
在其它條件都滿足的(資料充足且足夠好)的情況下,增加模型的尺寸以及計算量會帶來實質上的優勢,但是可供計算的資源總是有限的,特別是在移動裝置上,並不能無節制的增加模型的尺寸。例如,在VggNet模型中使用的引數量是AlexNet引數量的三倍,實際取得的效果也是好於AlexNet的。在之前的Google-Net中採用了優化之後的Inception-V1結構以及去掉全連線層等方式使得模型的引數量為500W資料量,相比VggNet的6000W數量及的引數量,後者是前者的12倍。
2. 通用設計準則
這裡給出基於大規模各式各樣卷積網路實踐的準則。這些準則是推測性質的,需要後期的實驗去評估他們的精度以及可用的領域。在實際中偏移這些準則過多會導致網路惡化,而修正這些偏差通常會使得網路更優。
(1)避免網路表達瓶頸,特別是網路結構的前期。對於深度學習網路可以使用一個無環圖進行表示,這就對網路中資訊的流向做了明確的規定。通常來說從網路的輸入端到最後的輸出端網路的表達尺寸是緩慢減小的。
(2)更高維度的表示在網路中更容易區域性處理。在卷積網路中增加每個圖塊的啟用允許更多解耦的特徵。所產生的網路將訓練更快
(3)空間聚合可以通過更低維度的植入來實現,這個過程中不會損失過多或是不會損失表達的能力。例如,在使用大尺寸卷積的時候,將其輸入維度減小,並不會對預期帶來不利的影響。我們假設,如果在空間聚合上下文中使用輸出,則相鄰單元之間的強相關性會導致維度縮減期間的資訊損失少得多。鑑於這些訊號應該易於壓縮,因此尺寸減小甚至會促進更快的學習。
(4)平衡網路的寬度與深度。網路的最佳效能體現是由每個階段的濾波器組數量以及網路的深度取平衡得到的。同時增加網路的深度以及濾波器數量會使得網路效能提升。但是,在一定的計算量前提下亮著共同增加會使得網路達到最優提升。因而就需要在一定的計算量前提下在網路深度以及濾波器的數量上去的一個均衡值。
3. 大濾波器尺寸卷積的因式分解
GoogleNet的大量初始好處都是來自於降維,可以視為在卷積層上的因式分解,這時在計算效率層面的一中特殊案例。其在 的卷積核之後接 的卷積。在視覺任務中,我們希望啟用層的鄰近輸出是高度相關的。因而,我們可以預期,他們在聚合之前被減少,這將導致區域性表達具有相似性
3.1 因式分解到更小的卷積
大的卷積核(例如,
或是
)會帶來不協調的計算開銷。例如,
的卷積核是
大小卷積核引數的
倍。因而,使用
大小的卷積帶來的計算量消耗是大於
的。且
大小的卷積核在模型前期的時候可以用來感受更大的視野,也是有其存在的價值與意義。針對這樣的情況可以對其使用兩個
大小的卷積核來代替,減少引數量。其執行示意圖如下:
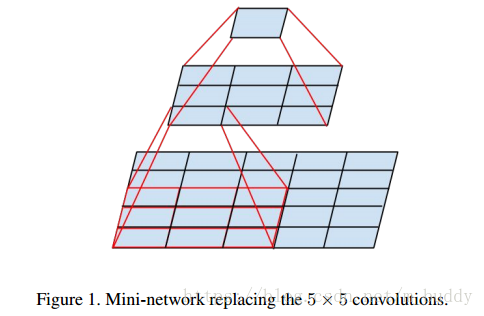
下圖是原論文中採用的Inception結構:
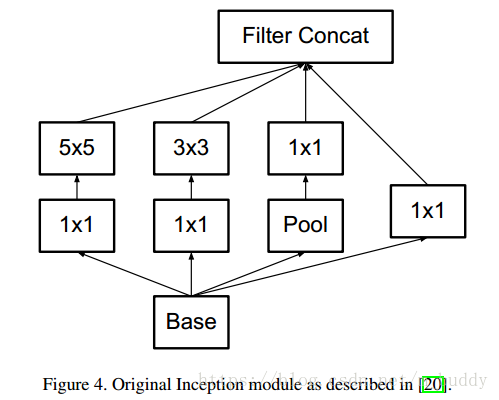
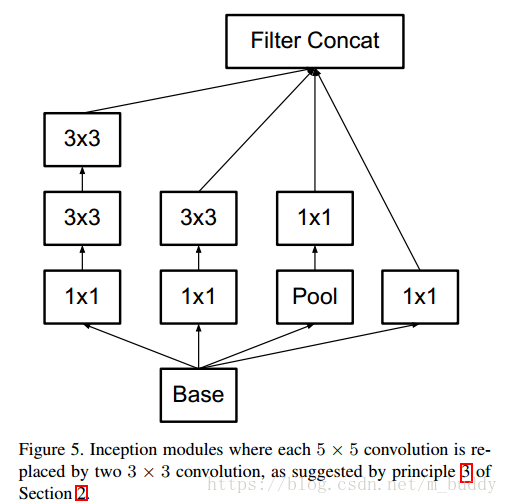
使用因式分解之後得到的結構:
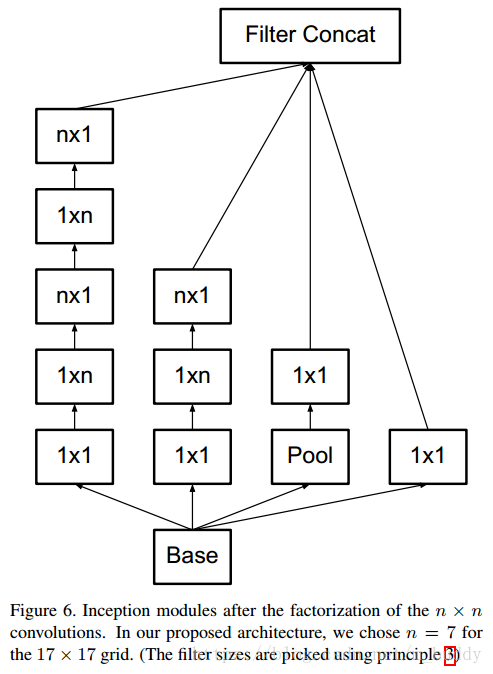
3.2 空間因式分解到部隊稱的卷積
在上面的內容中將大於
大小的可以因式分解為一系列
大小的卷積核。那麼
大小的卷積核是否可以分解成為更小的卷積核連線呢?答案是肯定的,文章中使用
大小的卷積核作為替換,就如下圖所示:
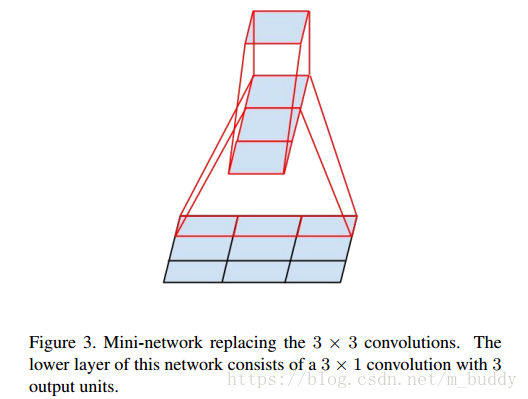
在上圖中原本
大小的卷積可以通過級聯
與
的卷積實現相同的感受視野。而且比原來的引數量節省了
的引數量。當然這種思路可以推廣到任意的
的卷積核上去。如下圖所示:
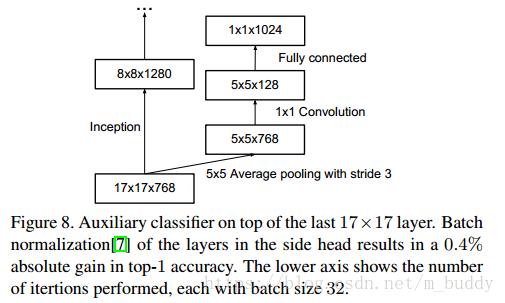
4. 附加損失函式使用
在之前的GoogleNet論文中提到新增附加損失函式會給網路帶來附加的梯度資訊,從而避免了梯度消失的問題。在論文中發現輔助損失函式並不能幫助網路儘早收斂,但是會使得網路獲得更高一些的精確率。並認為附加損失函式的加入最網路加入了正則約束。
5. 有效的網格尺寸減少
傳統上,卷積網路使用一些池化操作來縮減特徵圖的網格大小。為了避免表示瓶頸,在應用最大池化或平均池化之前,需要擴充套件網路濾波器的啟用維度。例如,開始有一個帶有
個濾波器的
網格,如果我們想要達到一個帶有
個濾波器的
網格,我們首先需要用
個濾波器計算步長為1的卷積,然後應用一個額外的池化步驟。這意味著總體計算成本由在較大的網格上使用
次運算的昂貴卷積支配。一種可能性是轉換為帶有卷積的池化,因此導致
次運算,將計算成本降低為原來的四分之一。然而,由於表示的整體維度下降到
,會導致表示能力較弱的網路,這會產生一個表示瓶頸。見下圖

上圖中,減少網格尺寸的兩種替代方式。左邊的解決方案違反了第2節中不引入表示瓶頸的原則1。右邊的版本計算量昂貴3倍
我們建議另一種變體,其甚至進一步降低了計算成本,同時消除了表示瓶頸(見下圖),而不是這樣做。我們可以使用兩個平行的步長為2的塊:PP和CC。PP是一個池化層(平均池化或最大池化)的啟用,兩者都是步長為2,其濾波器組連線下圖所示。
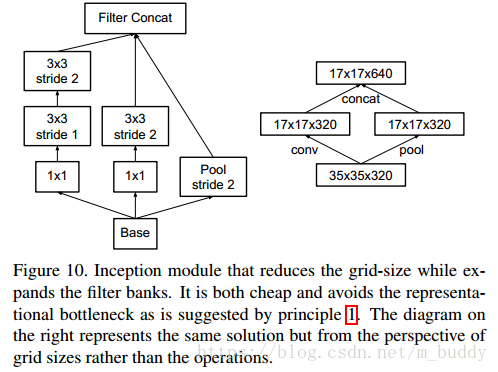
縮減網格尺寸的同時擴充套件濾波器組的Inception模組。它不僅廉價並且避免了原則1中提出的表示瓶頸。右側的圖表示相同的解決方案,但是從網格大小而不是運算的角度來看。