
強化學習三:Dynamic Programming
1,Introduction
1.1 What is Dynamic Programming?
Dynamic:某個問題是由序列化狀態組成,狀態step-by-step的改變,從而可以step-by-step的來解這個問題。
Programming:是在已知環境動力學的基礎上進行評估和控制,具體來說就是在瞭解包括狀態和行為空間、轉移概率矩陣、獎勵等資訊的基礎上判斷一個給定策略的價值函式,或判斷一個策略的優劣並最終找到最優的策略和最優價值函式。
動態規劃演算法把求解複雜問題分解為求解子問題,通過求解子問題進而得到整個問題的解。在解決子問題的時候,其結果通常需要儲存起來被用來解決後續複雜問題。
1.2 Requirements for Dynamic Programming
當問題具有下列特性時,通常可以考慮使用動態規劃來求解:
第一個特性是:一個複雜問題的最優解由數個小問題的最優解構成,可以通過尋找子問題的最優解來得到複雜問題的最優解;
第二個特性是:子問題在複雜問題內重複出現,使得子問題的解可以被儲存起來重複利用。
馬爾科夫決策過程具有上述兩個屬性:貝爾曼方程把問題遞迴為求解子問題,價值函式相當於儲存了一些子問題的解,可以複用。因此可以使用動態規劃來求解馬爾科夫決策過程。
動態規劃求解最優策略,指的是在瞭解整個MDP的基礎上求解最優策略,也就是清楚模型結構的基礎上:包括狀態行為空間、轉換矩陣、獎勵等。
1.3 Planning by Dynamic Programming
動態規劃求解最優策略,指的是在瞭解整個MDP的基礎上求解最優策略,也就是清楚模型結構的基礎上:包括狀態行為空間、轉換矩陣、獎勵等。
預測和控制是規劃的兩個重要內容。預測是對給定策略的評估過程,控制是尋找一個最優策略的過程。對預測和控制的數學描述是這樣:
預測(prediction):已知一個馬爾科夫決策過程MDP⟨S,A,P,R,γ⟩和一個策略
MRP⟨S,Pπ,Rπ,γ⟩,求解基於該策略π的價值函式Vπ。
控制 (control):已知一個馬爾科夫決策過程MDP⟨S,A,P,R,γ⟩,求解最優價值函式v∗和最優策略π∗。
2,Policy Evaluation
2.1 Iterative Policy Evaluation
策略評估 (policy evaluation) 指給定一個MDP和一個策略π,我們來評價這個策略有多好。如何判斷這個策略有多好呢?根據基於當前策略π的價值函式vπ來決定。所以我們的關鍵就是給定一個MDP和一個策略π,求出價值函vπ。
如何求解呢?我們可以使用同步迭代聯合動態規劃的演算法:從任意一個狀態價值函式開始,依據給定的策略,結合貝爾曼期望方程、狀態轉移概率和獎勵同步迭代更新狀態價值函式,直至其收斂,得到該策略下最終的狀態價值函式。理解該演算法的關鍵在於在一個迭代週期內如何更新每一個狀態的價值。該迭代法可以確保收斂形成一個穩定的價值函式。
用演算法的角度來描述就是:每次迭代過程中,對於第k+1次迭代,所有的狀態ss的價值用貝爾曼方程計算vk(s′)並更新該狀態第k+1次迭代中使用的價值vk(s),其中s′是s的後繼狀態。此種方法通過反覆迭代最終將收斂至Vπ 。 
舉例使用同步迭代法進行小型方格世界的策略評估:
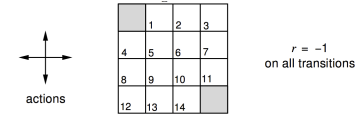
這是一個強化學習的問題:如圖4×4 的方格陣列,我們把它看成一個小世界。這個世界環境有16個狀態,圖中每一個小方格對應一個狀態,依次用0−15標記它們。圖中狀態0和15分別位於左上角和右下角,是終止狀態,用灰色表示。假設在這個小型方格世界中有一個可以進行上、下、左、右移動的agent,它需要通過移動自己來到達兩個灰色格子中的任意一個來完成任務。這個小型格子世界作為環境有著自己的動力學特徵:當agent採取的移動行為不會導致agent離開格子世界時,agent將以 100% 的機率到達它所要移動的方向的相鄰的那個格子,之所以是相鄰的格子而不能跳格是由於環境約束agent每次只能移動一格,同時規定agent也不能斜向移動;如果agent採取會跳出格子世界的行為,那麼環境將讓agent以 100% 的概率停留在原來的狀態;如果agent到達終止狀態,任務結束,否則agent可以持續採取行為。每當agent採取了一個行為後,只要這個行為是agent在非終止狀態時執行的,不管agent隨後到達哪一個狀態,環境都將給予agent值為 −1 的獎勵值;而當agent處於終止位置時,任何行為將獲得值為 0 的獎勵並仍舊停留在終止位置。環境設定如此的獎勵機制是利用了agent希望獲得累計最大獎勵的天性,而為了讓agent在格子世界中用盡可能少的步數來到達終止狀態,因為agent在世界中每多走一步,都將得到一個負值的獎勵。為了簡化問題,我們設定衰減因子γ=1。
在這個小型格子世界的強化學習問題中,agent為了達到在完成任務時獲得儘可能多的獎勵(在此例中是為了儘可能減少負值獎勵帶來的懲罰)這個目標,它至少需要思考一個問題:“當處在格子世界中的某一個狀態時,我應該採取如何的行為才能儘快到達表示終止狀態的格子。”這個問題對於擁有人類智慧的我們來說不是什麼難題,因為我們知道整個世界環境的執行規律(動力學特徵)。但對於格子世界中的agent來說就不那麼簡單了,因為agent身處格子世界中一開始並不清楚各個狀態之間的位置關係,它不知道當自己處在狀態4時只需要選擇“向上”移動的行為就可以直接到達終止狀態。此時agent能做的就是在任何一個狀態時,它選擇朝四個方向移動的概率相等。agent想到的這個辦法就是一個基於均一概率的隨機策略(uniform random policy) 。agent遵循這個均一隨機策略,不斷產生行為,執行移動動作,從格子世界環境獲得獎勵(大多數是−1 代表的懲罰),併到達一個新的或者曾經到達過的狀態。長久下去,agent會發現:遵循這個均一隨機策略時,每一個狀態跟自己最後能夠獲得的最終獎勵有一定的關係:在有些狀態時自己最終獲得的獎勵並不那麼少;而在其他一些狀態時,自己獲得的最終獎勵就少得多了。agent最終發現,在這個均一隨機策略指導下,每一個狀態的價值是不一樣的。這是一條非常重要的資訊。對於agent來說,它需要通過不停的與環境互動,經歷過多次的終止狀態後才能對各個狀態的價值有一定的認識。agent形成這個認識的過程就是策略評估的過程。而作為人類,我們知曉描述整個格子世界的資訊特徵,不必要向格子世界中的agent那樣通過與環境不停的互動來形成這種認識,我們可以直接通過迭代更新狀態價值的辦法來評估該策略下每一個狀態的價值。 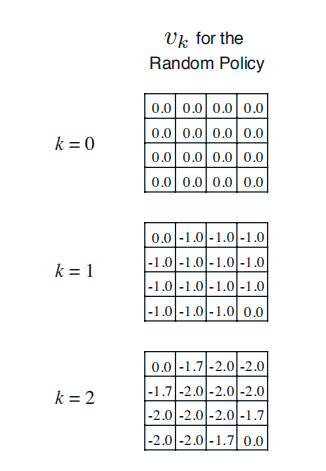

首先,我們假設所有除終止狀態以外的14個狀態的價值為0。同時,由於終止狀態獲得的獎勵為0,我們可以認為兩個終止狀態的價值始終保持為0。這樣產生了上圖(a)中第k=0次迭代的狀態價值函式。
在隨後的每一次迭代內,agent處於在任意狀態都以均等的概率(1/4)選擇朝上、下、左、右等四個方向中的一個進行移動;只要agent不處於終止狀態,隨後產生任意一個方向的移動後都將得到−1的獎勵,並依據環境動力學將100%進入行為指向的相鄰的格子或碰壁後留在原位,在更新某一狀態的價值時需要分別計算4個行為帶來的價值分量。
以上圖(b)(c)(d)中加粗的狀態價值-1.0,-1.7和-2.4為例,詳細的計算過程如下:
計算公式:
當前迭代時狀態s的價值=
當前狀態s向上移動行為的概率 × [當前狀態s向上移動行為的獎勵 + γ (當前狀態s向上移動行為進行下一狀態s’的狀態轉化概率) × 上一輪迭代時狀態s’的價值 ] +
當前狀態s向下移動行為的概率 × [當前狀態s向下移動行為的獎勵 + γ (當前狀態s向下移動行為進行下一狀態s’的狀態轉化概率) × 上一輪迭代時狀態s’的價值 ] +
當前狀態s向左移動行為的概率 × [當前狀態s向左移動行為的獎勵 + γ (當前狀態s向左移動行為進行下一狀態s’的狀態轉化概率) × 上一輪迭代時狀態s’的價值 ] +
當前狀態s向右移動行為的概率 × [當前狀態s向右移動行為的獎勵 + γ (當前狀態s向右移動行為進行下一狀態s’的狀態轉化概率) ×上一輪迭代時狀態s’的價值 ]
代入計算:
−1.0=0.25∗(−1+1∗0)+0.25∗(−1+1∗0)+0.25∗(−1+1∗0)+0.25∗(−1+1∗0)−1.0=0.25∗(−1+1∗0)+0.25∗(−1+1∗0)+0.25∗(−1+1∗0)+0.25∗(−1+1∗0)
−1.7=0.25∗(−1+1∗0)+0.25∗(−1+1∗−1)+0.25∗(−1+1∗−1)+0.25∗(−1+1∗−1)−1.7=0.25∗(−1+1∗0)+0.25∗(−1+1∗−1)+0.25∗(−1+1∗−1)+0.25∗(−1+1∗−1)
−2.4=0.25∗(−1+1∗0)+0.25∗(−1+1∗−2)+0.25∗(−1+1∗−1.7)+0.25∗(−1+1∗−2)
3,Policy Iteration
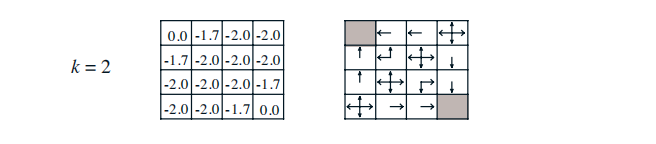
完成對一個策略的評估,將得到基於該策略下每一個狀態的價值。很明顯,不同狀態對應的價值一般也不同,那麼agent是否可以根據得到的價值狀態來調整自己的行動策略呢,例如考慮一種如下的貪婪策略:agent在某個狀態下選擇的行為是其能夠到達後續所有可能的狀態中價值最大的那個狀態。我們以均一隨機策略下第2次迭代後產生的價值函式為例說明這個貪婪策略。 
上圖所示,右側是根據左側各狀態的價值繪製的貪婪策略方案。agent處在任何一個狀態時,將比較所有後續可能的狀態的價值,從中選擇一個最大價值的狀態,再選擇能到達這一狀態的行為;如果有多個狀態價值相同且均比其他可能的後續狀態價值大,那麼個體則從這多個最大價值的狀態中隨機選擇一個對應的行為。
在這個小型方格世界中,新的貪婪策略比之前的均一隨機策略要優秀不少,至少在靠近終止狀態的幾個狀態中,agent將有一個明確的行為,而不再是隨機行為了。我們從均一隨機策略下的價值函式中產生了新的更優秀的策略,這是一個策略改善的過程。
更一般的情況是,當給定一個策略π時,可以得到基於該策略的價值函式vπ,基於產生的價值函式可以得到一個貪婪策略π′=greedy(vπ)。
依據新的策略π′會得到一個新的價值函式,併產生新的貪婪策略,如此重複迴圈迭代將最終得到最優價值函式v∗和最優策略π∗。策略在迴圈迭代中得到更新改善的過程稱為策略迭代(policy iteration) 。
回過頭看看小型方格世界,使用均一隨機策略初始化,然後用貪婪策略不斷改善的策略迭代過程:
首先零初始化價值函式(如下左圖),並採用均一隨機策略(如下右圖)。 
然後,根據上圖右邊的均一隨機策略,第一次迭代產生新的價值函式(如下左圖),根據這一新的價值函式,用貪婪策略改善前一箇舊的策略,產生新的策略(如下右圖)。

根據上圖右邊的經貪婪策略改善的策略,第二次迭代產生新的價值函式(如下左圖),根據這一新的價值函式,用貪婪策略改善前一箇舊的策略,產生新的策略(如下右圖)
重複迭代,迭代到第三輪,收斂到最優策略。左圖:當前迭代的價值函式;右圖:貪婪策略改善前一箇舊的策略,得到新的策略。

總結:下圖表達了策略迭代的過程。策略迭代分為兩個步驟:策略評估和策略改善。策略評估是基於當前的policy計算出每個狀態的價值函式;策略評估是基於當前的狀態價值函式,用貪婪演算法找到當前最優的policy。
我們可以看一下程式碼:
import numpy as np
world_h = 5
world_w = 6
length = world_h * world_w
gamma = 1
state = [i for i in range(length)]
action = ['n', 'e', 's', 'w']
ds_action = {'n': -world_w, 'e': 1, 's': world_w, 'w': -1}
value = [0 for i in range(length)]
def reward(s):
return 0 if s in [0, length - 1] else -1
def next_states(s, a):
next_state = s
if (s < world_w and a == 'n') or (s % world_w == 0 and a == 'w') \
or (s > length - world_w - 1 and a == 's') or (s % (world_w - 1) == 0 and a == 'e' and s != 0):
pass
else:
next_state = s + ds_action[a]
return next_state
def get_successor(s):
successor = []
for a in action:
next = next_states(s, a)
successor.append(next)
return successor
def value_update(s):
value_new = 0
if s in [0, length - 1]:
pass
else:
successor = get_successor(s)
rewards = reward(s)
for next_state in successor:
value_new += 1.00 / len(action) * (rewards + gamma * value[next_state])
return value_new
def main():
max_iter = 10
global value
v = np.array(value).reshape(world_h, world_w)
print(v, '\n')
iter = 0
while iter < max_iter:
new_value = [0 for i in range(length)]
for s in state:
new_value[s] = value_update(s)
value = new_value
v = np.array(value).reshape(world_h, world_w)
print(v, '\n')
iter += 1
if __name__ == '__main__':
main()
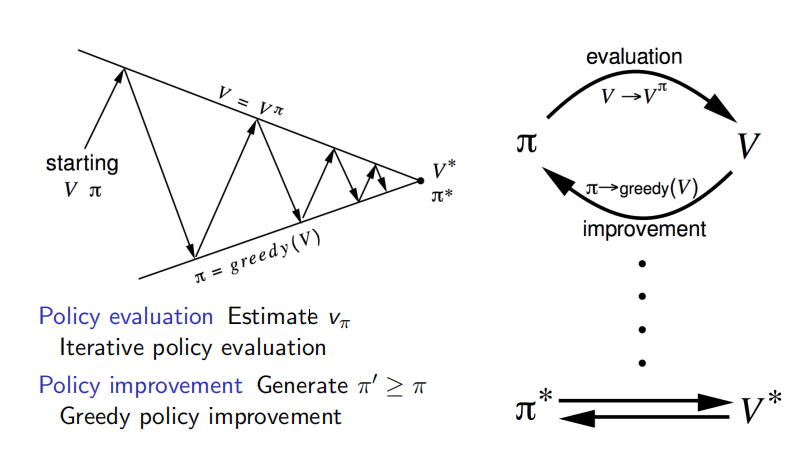
圖解:從一個初始策略ππ和初始價值函式VV開始,基於該策略進行完整的價值評估過程得到一個新的價值函式,隨後依據新的價值函式得到新的貪婪策略,隨後計算新的貪婪策略下的價值函式,整個過程反覆進行,在這個迴圈過程中策略和價值函式均得到迭代更新,並最終收斂值最有價值函式和最優策略。除初始策略外,迭代中的策略均是依據價值函式的貪婪策略。
3.1 policy improvement
Policy improvement的作用是對當前策略 ππ 進行提升,先討論一個簡單情況下的策略提升,再討論全域性意義上的策略提升。
首先,考慮僅僅在狀態 s 處選擇動作 a≠π(s),其他狀態下保持與原策略π(s) 相同,獲得新策略π′(s)。那麼可以根據當前策略的vπ(s)可以計算出新策略 π′(s) 在此處的action-value function qπ′(s,a) : 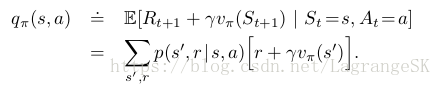
現在假設新策略π′(s)π′(s)是當前最優策略,比舊策略好,則有:
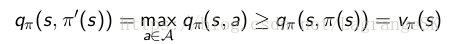
那麼在每一個state s處都選擇滿足maxqπ(s,a)的action a=π′(s),那麼可以推匯出 vπ′(s)≥vπ(s),推導如下
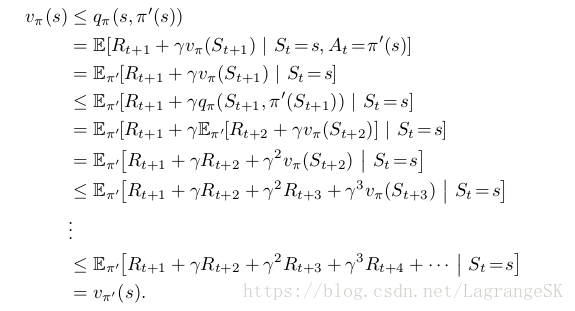
說明我們通過policy improvement 可以獲得比當前策略好的新策略。那麼我們如何獲得最優策略呢?當策略提升到一個極限時,無法再進一步的提升了,我們就獲得了最優策略,此時,有:
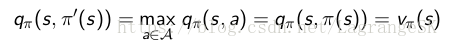
顯然,這滿足Bellman optimality equation :
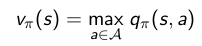
因此,對每一個state s 都滿足vπ(s)=v∗(s),即ππ為最優策略。
3.2 Policy iteration
當給定一個策略ππ時,如何獲得最優策略,結合Policy evaluation 和Policy improvement ,首先通過不斷迭代確定該策略的state-value function v(s),然後取最大的state-value function對應的Policy。
演算法虛擬碼如下
通過觀察方格世界的小例子的右邊最後一幅圖也發現,最優策略是指向state-value function 較大的方向。可是,我們發現儘管迭代次數不同,對應value function不同,但是右邊最後三幅圖都表示最優策略。那麼我們是不是可以考慮不迭代這麼多次,就能直接獲得最優策略呢?答案是肯定的,我們接下來介紹一種方法就是這麼幹的。
4、value iteration
Policy iteration可以獲得最優策略,但是他很費勁啊,在每次Policy improvement之前,都要進行很長的Policy evaluation,每一次Policy evaluation都需要遍歷所有的狀態,對時間和計算資源都是一種消耗。可不可以不這麼費勁呢?
我們觀察一個現象:
如下圖,當只採用基於均一隨機策略的迭代法進行策略迭代時,需要經過數十次迭代才會收斂,收斂到最優策略。
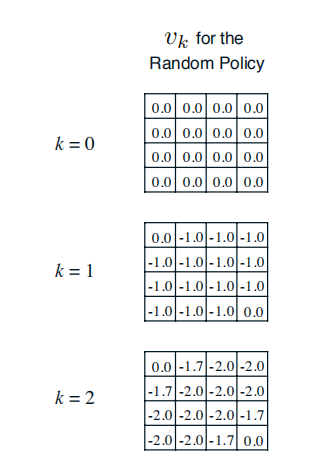

如下圖,當採用均一隨機策略初始化,貪婪策略改善進行策略迭代時,在第三次迭代時,得到的策略就是最優策略了。

可見,採用不同的策略,達到最優策略時,所需要的迭代次數不同。我們先從另一個角度剖析一下最優策略的意義。
任何一個最優策略可以分為兩個階段,首先該策略要能產生當前狀態下的最優行為,其次對於該最優行為到達的後續狀態時該策略仍然是一個最優策略。可以反過來理解這句話:如果一個策略不能在當前狀態下產生一個最優行為,或者這個策略在針對當前狀態的後續狀態時不能產生一個最優行為,那麼這個策略就不是最優策略。與價值函式對應起來,可以這樣描述狀態價值的最優化原則:一個策略能夠獲得某狀態ss的最優價值,當且僅當:該策略也同時獲得狀態s所有可能的後續狀態 s′的最優價值。
一個狀態的最優價值可以由其後續狀態的最優價值通過貝爾曼最優方程來計算: 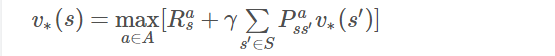
這個公式告訴我們,如果能知道最終狀態的價值和相關獎勵,可以直接計算得到最終狀態的前一個所有可能狀態的最優價值。更樂觀的是,即使不知道最終狀態是哪一個狀態,也可以利用上述公式進行純粹的價值迭代,不停的更新狀態價值,最終得到最優價值。而且這種單純價值迭代的方法甚至可以允許存在迴圈的狀態轉換乃至一些隨機的狀態轉換過程。下面以一個更簡單的方格世界來解釋什麼是單純的價值迭代。 
如圖所示是一個在 4×4 方格世界中尋找最短路徑的問題。與前述的方格世界問題唯一的不同之處在於,該世界只在左上角有一個最終狀態,agent在世界中需儘可能用最少步數到達左上角這個最終狀態。
首先考慮到agent知道環境的動力學特徵的情形。在這種情況下,agent可以直接計算得到與終止狀態直接相鄰(斜向不算)的左上角兩個狀態的最優價值均為−1。隨後agent又可以往右下角延伸計算得到與之前最優價值為−1的兩個狀態香相鄰的3個狀態的最優價值為−2。以此類推,每一次迭代agent將從左上角朝著右下角方向依次直接計算得到一排斜向方格的最優價值,直至完成最右下角的一個方格最優價值的計算。
現在考慮更廣泛適用的,agent不知道環境動力學特徵的情形。在這種情況下,agent並不知道終止狀態的位置,但是它依然能夠直接進行價值迭代。與之前情形不同的是,此時的agent要針對所有的狀態進行價值更新。為此,agent先隨機地初始化所有狀態價值 (V1),示例中為了演示簡便全部初始化為 0。在隨後的一次迭代過程中,對於任何非終止狀態,因為執行任何一個行為都將得到一個−1的獎勵,而所有狀態的價值都為0,那麼所有的非終止狀態的價值經過計算後都為−1 (V2)。在下一次迭代中,除了與終止狀態相鄰的兩個狀態外的其餘狀態的價值都將因採取一個行為獲得−1的獎勵以及在前次迭代中得到的後續狀態價值均為 −1,而將自身的價值更新為−2;而與終止狀態相鄰的兩個狀態在更新價值時需將終止狀態的價值0作為最高價值代入計算,因而這兩個狀態更新的價值仍然為−1(V3)。依次類推直到最右下角的狀態更新為−6後 (V7),再次迭代各狀態的價值將不會發生變化,於是完成整個價值迭代的過程。
兩種情形的相同點都是根據後續狀態的價值,利用貝爾曼最優方程來更新得到前接狀態的價值。兩者的差別體現在:前者每次迭代僅計算相關的狀態的價值,而且一次計算即得到最優狀態價值,後者在每次迭代時要更新所有狀態的價值。
可以看出價值迭代的目標仍然是尋找到一個最優策略,它通過貝爾曼最優方程從前次迭代的價值函式中計算得到當次迭代的價值函式,在這個反覆迭代的過程中,並沒有一個明確的策略參與,由於使用貝爾曼最優方程進行價值迭代時類似於貪婪地選擇了最有行為對應的後續狀態的價值,因而價值迭代其實等效於策略迭代中每迭代一次價值函式就更新一次策略的過程。需要注意的是,在純粹的價值迭代尋找最優策略的過程中,迭代過程中產生的狀態價值函式不對應任何策略。迭代過程中價值函式更新的公式為: 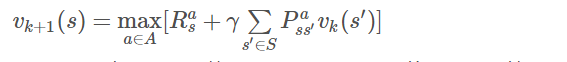
其中,k表示迭代次數。公式中可以看出,價值迭代雖然不需要策略參與,但仍然需要知道狀態之間的轉移概率,也就是需要知道模型。
5.Summary of DP Algorithms
迭代法策略評估屬於預測問題,它使用貝爾曼期望方程來進行求解。策略迭代和價值迭代則屬於控制問題,其中前者使用貝爾曼期望方程進行一定次數的價值迭代更新,隨後在產生的價值函式基礎上採取貪婪選擇的策略改善方法形成新的策略,如此交替迭代不斷的優化策略;價值迭代則不依賴任何策略,它使用貝爾曼最優方程直接對價值函式進行迭代更新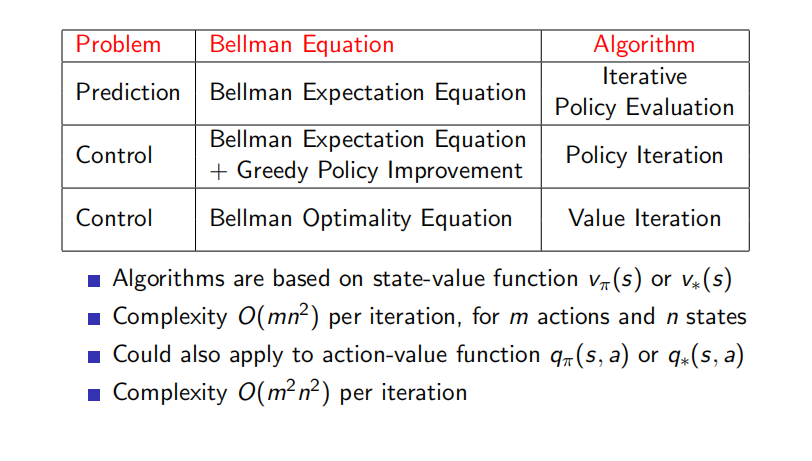
6.Expansion Of Dynamic Programming
首先介紹非同步動態規劃,前面我們介紹的方法都是用的同步動態規劃,也就是說,所有的狀態一起進行backup,而非同步動態規劃則是將所有states獨立進行backup,並且是以任意順序。非同步動態規劃可以減少計算量,不過如果想要收斂,則需要滿足一個條件:所有狀態都需要能夠持續被選擇,或者說,在任一時刻,任何狀態都有可能被選中。非同步動態規劃主要有三個簡單的idea:
1)In-place dynamic programming;
2)Prioritised sweeping;
3)Real-time dynamic programming.


對於DP而言,它的推演是整個樹狀散開的,我們稱這種方法為Full-Width Backup方法。在這種方法中,對於每一次backup來說,所有的後繼狀態和動作都要被考慮在內,並且需要已知MDP的轉移矩陣與獎勵函式,因此DP將面臨維數災難問題。所以我們就有了Sample Backup,這種方法將在後面進行介紹,其主要思想是利用樣本進行backup,優點有a)Model-free;b)避免了維數災難問題;c)backup的代價與狀態數n無關。如下圖所示:
最後介紹一種DP的擴充套件,叫做近似動態規劃:
