
ES調優經驗分享
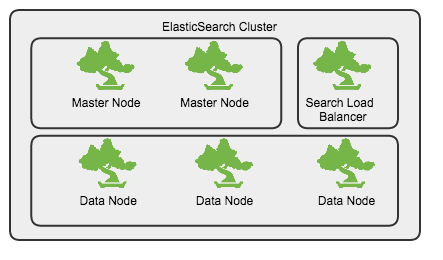
叢集規劃
- 獨立的master節點,不儲存資料, 數量不少於2
- 資料節點(Data Node)
- 查詢節點(Query Node),起到負載均衡的作用
Linux系統引數配置
檔案控制代碼
Linux中,每個程序預設開啟的最大檔案控制代碼數是1000,對於伺服器程序來說,顯然太小,通過修改/etc/security/limits.conf來增大開啟最大控制代碼數
* - nofile 65535虛擬記憶體設定
max_map_count定義了程序能擁有的最多記憶體區域
sysctl -w vm.max_map_count=262144修改/etc/elasticsearch/elasticsearch.yml
bootstrap.mlockall: true修改/etc/security/limits.conf, 在limits.conf中新增如下內容
* soft memlock unlimited
* hard memlock unlimitedmemlock 最大鎖定記憶體地址空間, 要使limits.conf檔案配置生效,必須要確保pam_limits.so檔案被加入到啟動檔案中。
確保/etc/pam.d/login檔案中有如下內容
session required /lib/security/pam_limits.so驗證是否生效
curl localhost:9200/_nodes/stats/process?pretty
磁碟快取相關引數
vm.dirty_background_ratio 這個引數指定了當檔案系統快取髒頁數量達到系統記憶體百分之多少時(如5%)就會觸發pdflush/flush/kdmflush等後臺回寫程序執行,將一定快取的髒頁非同步地刷入外存;
vm.dirty_ratio
-
該引數則指定了當檔案系統快取髒頁數量達到系統記憶體百分之多少時(如10%),系統不得不開始處理快取髒頁(因為此時髒頁數量已經比較多,為了避免資料丟失需要將一定髒頁刷入外存);在此過程中很多應用程序可能會因為系統轉而處理檔案IO而阻塞。
-
把該引數適當調小,原理通(1)類似。如果cached的髒資料所佔比例(這裡是佔MemTotal的比例)超過這個設定,系統會停止所有的應用層的IO寫操作,等待刷完資料後恢復IO。所以萬一觸發了系統的這個操作,對於使用者來說影響非常大的。
sysctl -w vm.dirty_ratio=10
sysctl -w vm.dirty_background_ratio=5swap調優
swap空間是一塊磁碟空間,作業系統使用這塊空間儲存從記憶體中換出的作業系統不常用page資料,這樣可以分配出更多的記憶體做page cache。這樣通常會提升系統的吞吐量和IO效能,但同樣會產生很多問題。頁面頻繁換入換出會產生IO讀寫、作業系統中斷,這些都很影響系統的效能。這個值越大作業系統就會更加積極的使用swap空間。
調節swappniess方法如下
sudo sh -c 'echo "0">/proc/sys/vm/swappiness'io sched
如果叢集中使用的是SSD磁碟,那麼可以將預設的io sched由cfq設定為noop
sudo sh -c 'echo "noop">/sys/block/sda/queue/scheduler'JVM引數設定
在/etc/sysconfig/elasticsearch中設定最大堆記憶體,該值不應超過32G
ES_HEAP_SIZE=32g
ES_JAVA_OPTS="-Xms32g"
MAX_LOCKED_MEMORY=unlimited
MAX_OPEN_FILES=65535indice引數調優
以建立demo_logs模板為例,說明可以調優的引數及其數值設定原因。
PUT _template/demo_logs
{
"order": 6,
"template": "demo-*",
"settings": {
"index.merge.policy.segments_per_tier": "25",
"index.mapping._source.compress": "true",
"index.mapping._all.enabled": "false",
"index.warmer.enabled": "false",
"index.merge.policy.min_merge_size": "10mb",
"index.refresh_interval": "60s",
"index.number_of_shards": "7",
"index.translog.durability": "async",
"index.store.type": "mmapfs",
"index.merge.policy.floor_segment": "100mb",
"index.merge.scheduler.max_thread_count": "1",
"index.translog.translog.flush_threshold_size": "1g",
"index.merge.policy.merge_factor": "15",
"index.translog.translog.flush_threshold_period": "100m",
"index.translog.sync_interval": "5s",
"index.number_of_replicas": "1",
"index.indices.store.throttle.max_bytes_per_sec": "50mb",
"index.routing.allocation.total_shards_per_node": "2",
"index.translog.flush_threshold_ops": "1000000"
},
"mappings": {
"_default_": {
"dynamic_templates": [ { "string_template": { "mapping": { "index": "not_analyzed", "ignore_above": "10915", "type": "string" }, "match_mapping_type": "string" } }, { "level_fields": { "mapping": { "index": "no", "type": "string" }, "match": "Level*Exception*" } } ]
}
}
"aliases": {}
}replica數目
為了讓建立的es index在每臺datanode上均勻分佈,同一個datanode上同一個index的shard數目不應超過3個。
計算公式: (number_of_shard * (1+number_of_replicas)) < 3*number_of_datanodes
每臺機器上分配的shard數目
"index.routing.allocation.total_shards_per_node": "2",refresh時間間隔
預設的重新整理時間間隔是1s,對於寫入量很大的場景,這樣的配置會導致寫入吞吐量很低,適當提高重新整理間隔,可以提升寫入量,代價就是讓新寫入的資料在60s之後可以被搜尋,新資料可見的及時性有所下降。
"index.refresh_interval": "60s"translog
降低資料flush到磁碟的頻率。如果對資料丟失有一定的容忍,可以開啟async模式。
"index.translog.flush_threshold_ops": "1000000",
"index.translog.durability": "async",merge相關引數
"index.merge.policy.floor_segment": "100mb",
"index.merge.scheduler.max_thread_count": "1",
"index.merge.policy.min_merge_size": "10mb"mapping設定
對於不參與搜尋的欄位(fields), 將其index方法設定為no, 如果對分詞沒有需求,對參與搜尋的欄位,其index方法設定為not_analyzed
多使用dynamic_template
叢集引數調優
{
"persistent": {
"cluster": {
"routing": {
"allocation": {
"enable": "new_primaries",
"cluster_concurrent_rebalance": "8",
"allow_rebalance": "indices_primaries_active",
"node_concurrent_recoveries": "8"
}
}
},
"indices": {
"breaker": {
"fielddata": {
"limit": "30%"
},
"request": {
"limit": "30%"
}
},
"recovery": {
"concurrent_streams": "10",
"max_bytes_per_sec": "200mb"
}
}
},
"transient": {
"indices": {
"store": {
"throttle": {
"type": "merge",
"max_bytes_per_sec": "50mb"
}
},
"recovery": {
"concurrent_streams": "8"
}
},
"threadpool": {
"bulk": {
"type": "fixed"
"queue_size": "1000",
"size": "30"
},
"index": {
"type": "fixed",
"queue_size": "1200",
"size": "30"
}
},
"cluster": {
"routing": {
"allocation": {
"enable": "all",
"cluster_concurrent_rebalance": "8",
"node_concurrent_recoveries": "15"
}
}
}
}
}避免shard的頻繁rebalance,將allocation的型別設定為new_primaries, 將預設並行rebalance由2設定為更大的一些的值
避免每次更新mapping, 針對2.x以下的版本
"indices.cluster.send_refresh_mapping": false調整threadpool, size不要超過core數目,否則執行緒之間的context switching會消耗掉大量的cpu時間,導致load過高。 如果沒有把握,那就不要去調整。
定期清理cache
為避免fields data佔用大量的jvm記憶體,可以通過定期清理的方式來釋放快取的資料。釋放的內容包括field data, filter cache, query cache
curl -XPOST "localhost:9200/_cache/clear"
ES平衡分片
"cluster.routing.allocation.balance.shard":"0.45f",//定義分配在該節點的分片數的因子 閾值=因子*(當前節點的分片數-叢集的總分片數/節點數,即每個節點的平均分片數)
"cluster.routing.allocation.balance.index":"0.55f",//定義分配在該節點某個索引的分片數的因子,閾值=因子*(儲存當前節點的某個索引的分片數-索引的總分片數/節點數,即每個節點某個索引的平均分片數)
"cluster.routing.allocation.balance.threshold":"1.0f",//超出這個閾值就會重新分配分片
"cluster.routing.allocation.total_shards_per_node":-1,//單個節點的最大分片數
//Disk-based Shard Allocation
"cluster.routing.allocation.disk.threshold_enabled":true,//是否開啟基於硬碟的分發策略
"cluster.routing.allocation.disk.watermark.low":"85%",//不會分配分片到硬碟使用率高於這個值的節點
"cluster.routing.allocation.disk.watermark.high":"90%",//如果硬碟使用率高於這個值,則會重新分片該節點的分片到別的節點
"cluster.info.update.interval":"30s",//當前硬碟使用率的查詢頻率
"cluster.routing.allocation.disk.include_relocations":true,//計算硬碟使用率時,是否加上正在重新分配給其他節點的分片的大小
歸併執行緒配置
segment 歸併的過程,需要先讀取 segment,歸併計算,再寫一遍 segment,最後還要保證刷到磁碟。可以說,這是一個非常消耗磁碟 IO 和 CPU 的任務。所以,ES 提供了對歸併執行緒的限速機制,確保這個任務不會過分影響到其他任務。
在 5.0 之前,歸併執行緒的限速配置 indices.store.throttle.max_bytes_per_sec 是 20MB。對於寫入量較大,磁碟轉速較高,甚至使用 SSD 盤的伺服器來說,這個限速是明顯過低的。對於 Elastic Stack 應用,社群廣泛的建議是可以適當調大到 100MB或者更高。
# curl -XPUT http://127.0.0.1:9200/_cluster/settings -d'
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}'
5.0 開始,ES 對此作了大幅度改進,使用了 Lucene 的 CMS(ConcurrentMergeScheduler) 的 auto throttle 機制,正常情況下已經不再需要手動配置 indices.store.throttle.max_bytes_per_sec 了。官方文件中都已經刪除了相關介紹,不過從原始碼中還是可以看到,這個值目前的預設設定是 10240 MB。
歸併執行緒的數目,ES 也是有所控制的。預設數目的計算公式是: Math.min(3, Runtime.getRuntime().availableProcessors() / 2)。即伺服器 CPU 核數的一半大於 3 時,啟動 3 個歸併執行緒;否則啟動跟 CPU 核數的一半相等的執行緒數。相信一般做 Elastic Stack 的伺服器 CPU 合數都會在 6 個以上。所以一般來說就是 3 個歸併執行緒。如果你確定自己磁碟效能跟不上,可以降低index.merge.scheduler.max_thread_count 配置,免得 IO 情況更加惡化。
歸併策略
歸併執行緒是按照一定的執行策略來挑選 segment 進行歸併的。主要有以下幾條:
- index.merge.policy.floor_segment 預設 2MB,小於這個大小的 segment,優先被歸併。
- index.merge.policy.max_merge_at_once 預設一次最多歸併 10 個 segment
- index.merge.policy.max_merge_at_once_explicit 預設 forcemerge 時一次最多歸併 30 個 segment。
- index.merge.policy.max_merged_segment 預設 5 GB,大於這個大小的 segment,不用參與歸併。forcemerge 除外。
根據這段策略,其實我們也可以從另一個角度考慮如何減少 segment 歸併的消耗以及提高響應的辦法:加大 flush 間隔,儘量讓每次新生成的 segment 本身大小就比較大。
forcemerge 介面
既然預設的最大 segment 大小是 5GB。那麼一個比較龐大的資料索引,就必然會有為數不少的 segment 永遠存在,這對檔案控制代碼,記憶體等資源都是極大的浪費。但是由於歸併任務太消耗資源,所以一般不太選擇加大 index.merge.policy.max_merged_segment 配置,而是在負載較低的時間段,通過 forcemerge 介面,強制歸併 segment。
# curl -XPOST http://127.0.0.1:9200/logstash-2015-06.10/_forcemerge?max_num_segments=1
由於 forcemerge 執行緒對資源的消耗比普通的歸併執行緒大得多,所以,絕對不建議對還在寫入資料的熱索引執行這個操作。這個問題對於 Elastic Stack 來說非常好辦,一般索引都是按天分割的。更合適的任務定義方式
其它
- marvel: 安裝marvel外掛,多觀察系統資源佔用情況,包括記憶體,cpu
- 日誌: 對es的執行日誌要經常檢視,檢查index配置是否合理,以及入庫資料是否存在異常
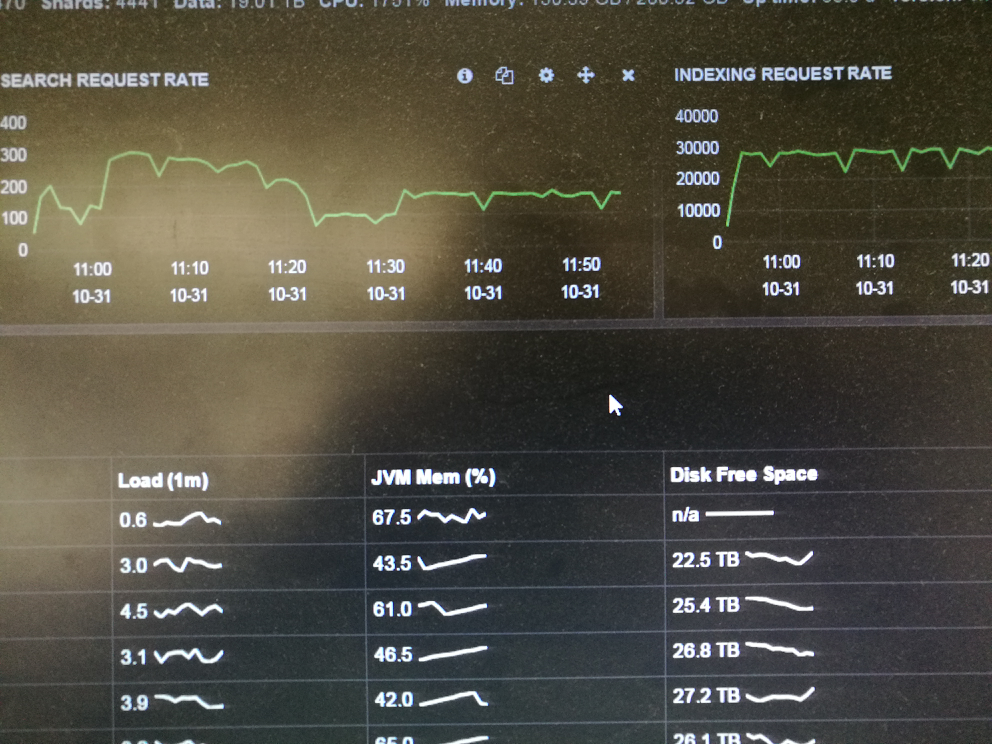
調優之後的執行效果
寫入量穩定在30K/s
【重新分配分片】
Elasticsearch通過reroute api重新分配分片
elasticsearch可以通過reroute api來手動進行索引分片的分配。
不過要想完全手動,必須先把cluster.routing.allocation.disable_allocation引數設定為true,禁止es進行自動索引分片分配,否則你從一節點把分片移到另外一個節點,那麼另外一個節點的一個分片又會移到那個節點。資料量很少的時候,可能影響不大,但是如果資料量很大,這個引數必須要設定,因為如果不設定,即便你不手動遷移分片,在我們重啟機群的時候,也會產生分片的遷移,導致大量資源被佔用,重啟變慢.
一共有三種操作,分別為:移動(move),取消(cancel)和分配(allocate)。下面分別介紹這三種情況:
移動(move)
把分片從一節點移動到另一個節點。可以指定索引名和分片號。
取消(cancel)
取消分配一個分片。可以指定索引名和分片號。node引數可以指定在那個節點取消正在分配的分片。allow_primary引數支援取消分配主分片。
分配(allocate)
分配一個未分配的分片到指定節點。可以指定索引名和分片號。node引數指定分配到那個節點。allow_primary引數可以強制分配主分片,不過這樣可能導致資料丟失。我一般用來清空某個未分配分片的資料的時候才設定這個引數
叢集索引中可能由多個分片構成,並且每個分片可以擁有多個副本,將一個單獨的索引分為多個分片,可以處理不能在單一伺服器上執行的
大型索引.
由於每個分片有多個副本,通過副本分配到多個伺服器,可以提高查詢的負載能力.
為了進行分片和副本操作,需要確定將這些分片和副本放到叢集節點的哪個位置,需要確定把每個分片和副本分配到哪臺伺服器/節點上.
1.索引建立&指定節點引數:
$curl -XPOST 'http://localhost:9200/filebeate-ali-hk-fd-tss1'
$curl -XPUT 'http://localhost:9200/filebeat-ali-hk-fd-tss1/_settings' -d '{
"index.routing.allocation.include.zone":"ali-hk-ops-elk1"
}'
將索引指定存放在elk1的節點上
$curl -XPUT 'http://localhost:9200/filebeat-ali-hk-fd-tss1/settings' -d '{
"index.routing.allocation.include._ip":"ip_addr1,ip_addr2"
}'
根據ip地址指定索引的分配節點
2.排除索引分配的節點:
$curl -XPOST 'http://localhost:9200/filebeat-ali-hk-fd-tss2'
$curl -XPUT 'http://localhost:9200/filebeat-ali-hk-fd-tss2/_setting' -d '{
"index.routing.allocation.exclude.zone":"ali-hk-ops-elk2"
}'
$curl -XPUT 'http://localhost:9200/filebeat-ali-hk-fd-tss2/_setting' -d '{
"index.routing.allocation.exclude._ip":"ip_addr1,ip_addr2"
}'
根據ip地址排除索引分配的節點
3.每個節點上分片和副本數量的控制:
對一個索引指定每個節點上的最大分片數量:
$curl -XPUT 'http://localhost:9200/filebeat-ali-hk-fd-tss1/_settings' -d '{
"index.routing.allocation.total_shards_per_node":1
}'
如果配置不當,導致主分片無法分配的話,叢集就會處於red狀態.
4.手動移動分片和副本:
移動分片:
$curl -XPOST 'http://localhost:9200/_cluster/reroute' -d '{
"commands":[{
"move":{
"index":"filebeat-ali-hk-fd-tss1",
"shard":1,
"from_node":"ali-hk-ops-elk1",
"to_node":"ali-hk-ops-elk2"
}
}]
}'
取消分片:
$curl -XPOST 'http://localhost:9200/_cluster/reroute' -d '{
"commands":[{
"cancel":{
"index":"filebeat-ali-hk-fd-tss1",
"shard":1,
"node":"ali-hk-ops-elk1"
}
}]
}'
分配分片(用來分配未分配狀態的分片,會導致資料丟失):
$curl -XPOST 'http://localhost:9200/_cluster/reroute' -d '{
"commands":[{
"allocate":{
"index":"filebeat-ali-hk-fd-tss1",
"shard":1,
"node":"ali-hk-ops-elk1",
allow_primary" : true (允許該分片做主分片)
}
}]
}'
將某個未分配的索引手動分配到某個節點上.
$curl -XPOST 'http://localhost:9200/_cluster/reroute' -d '{
"commands":[
{
"move":{
"index":"filebeat-ali-hk-fd-tss1",
"shard":1,
"from_node":"ali-hk-ops-elk1",
"to_node":"ali-hk-ops-elk2"
}
},
{
"cancel":{
"index":"filebeat-ali-hk-fd-tss1",
"shard":1,
"node":"ali-hk-ops-elk1"
}
},
{
"allocate":{
"index":"filebeat-ali-hk-fd-tss1",
"shard":1,
"node":"ali-hk-ops-elk1"
}
}]
}'
5.關於unassigned shards的問題解決:
1)出現大量的unassigned shards
2)叢集的狀態為:red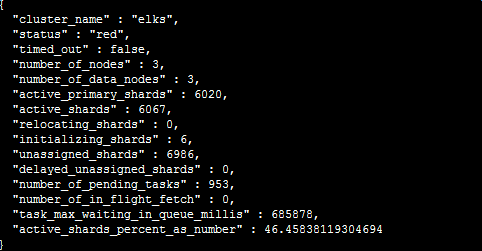
叢集狀態:red-->存在不可用的主分片
A:fix unassigned shards:
檢視所有分片的狀態:
$curl -XGET 'http://localhost:9200/_cat/shards'
查詢所有unassigned的分片:
$curl -XGET 'http://localhost:9200/_cat/shards' | grep UNASSIGNED
B:查詢得到master節點的唯一標識:
$curl -XGET 'http://localhost:9200/_nodes/process?pretty=true'
C:執行route對unassigned的索引進行手動分片:
for index in $(curl -XGET 'http://localhost:9200/_cat/shards' | grep UNASSIGNED |awk '{print 1}'|sort |uniq):do for shards in1}'|sort |uniq):do for shards in(curl -XGET 'http://localhost:9200/_cat/shards' | grep UNASSIGNED | grep index | awk '{printindex | awk '{print2}'|sort|uniq):do
curl XPOST 'http://localhost:9200/_cluster/reroute'-d '{
"commands":[
{
"allocate":{
"index":index,"shards":index,"shards":shards,
"node":"ali-k-ops-elk1",
"allow_primary":"true"
}
}
]
}'
=============================================================
叢集升級操作
#1、 關閉自動分片
PUT _cluster/settings
{
"persistent": {
"cluster": {
"routing": {
"rebalance": {
"enable": "none"
},
"allocation": {
"enable": "none"
}
}
}
}
}
#2、 備份老配置cp elasticsearch.yml elasticsearch.yml_20181017 然後在每個節點增加如下配置到elasticsearch.yml,去除歷史相同配置
#3、 更新後的節點依次重啟操作:確保前一個節點啟動正常,並且狀態正常後再重啟下一個節點
通過es_head外掛關閉索引,停止ES叢集
# 重啟整個叢集:順序是先啟master組(所有的master重啟完成後要停止叢集的shard自動均衡),再啟hot組節點,最後啟stale組節點
relo、init、unassign這3項都變成0
#4、 叢集正常後,開啟自動分片
PUT _cluster/settings
{
"persistent": {
"cluster": {
"routing": {
"rebalance": {
"enable": "all"
},
"allocation": {
"enable": "all"
}
}
}
}
}
# memory_lock
bootstrap.memory_lock: true
# cache
indices.cache.cleanup_interval: 5m
indices.memory.index_buffer_size: 20%
indices.queries.cache.count: 100000
indices.queries.cache.size: 10%
indices.requests.cache.size: 10%
indices.requests.cache.expire: 5m
indices.store.throttle.type: none
# search
search.highlight.term_vector_multi_value: false
# thread_pool
thread_pool.bulk.size: 20
thread_pool.search.size: 25
thread_pool.bulk.queue_size: 1024
thread_pool.force_merge.size: 4
# fielddata
indices.fielddata.cache.size: 40%
磁碟效能測試:
1、先熟悉兩個特殊的裝置:
(1)/dev/null:回收站、無底洞。
(2)/dev/zero:產生字元。
2、測試磁碟寫能力
time dd if=/dev/zero of=/cy/testw.dbf bs=4k count=10000
real 0m36.669s
寫速度為:4*10000/1024/36.669=M/s。
rm -f /cy/testw.dbf
3、測試磁碟讀能力
time dd if=/dev/sdb of=/dev/null bs=4k
4、測試同時讀寫能力
time dd if=/dev/sdb of=/cy/testrw.dbf bs=4k
rm -f /cy/testrw.dbf
系統引數調優:
sysctl -w vm.dirty_ratio=20
sysctl -w vm.dirty_background_ratio=10