
CPU Cache與快取行
引言
先看下面這兩個迴圈遍歷哪個快?
int[][] array = new int[64 * 1024][1024];
// 橫向遍歷
for(int i = 0; i < 64 * 1024; i ++)
for(int j = 0; j < 1024; j ++)
array[i][j] ++;
// 縱向遍歷
for(int i = 0; i < 1024; i ++)
for(int j = 0; j < 64 * 1024; j ++)
array[j][i] ++;在CPU處理器引數為 2.3 GHz Intel Core i5 的Mac上的結果是:
橫向遍歷: 80ms
縱向遍歷: 2139ms
橫向遍歷的 CPU cache 命中率高,所以它比縱向遍歷約快這麼多倍!
Gallery of Processor Cache Effects 用 7 個原始碼示例生動的介紹 cache 原理,深入淺出!但是可能因作業系統的差異、編譯器是否優化,以及近些年 cache 效能的提升,有些樣例在 Mac 的效果與原文相差較大。
CPU Cache
CPU 訪問記憶體時,首先查詢 cache 是否已快取該資料。如果有,則返回資料,無需訪問記憶體;如果不存在,則需把資料從記憶體中載入 cache,最後返回給理器。在處理器看來,快取是一個透明部件,旨在提高處理器訪問記憶體的速率,所以從邏輯的角度而言,程式設計時無需關注它,但是從效能的角度而言,理解其原理和機制有助於寫出效能更好的程式。Cache 之所以有效,是因為程式對記憶體的訪問存在一種概率上的區域性特徵:
- Spatial Locality:對於剛被訪問的資料,其相鄰的資料在將來被訪問的概率高。
- Temporal Locality:對於剛被訪問的資料,其本身在將來被訪問的概率高。
比 mac OS 為例,可用 命令 sysctl -a 查詢 cache 資訊,單位是位元組Byte。
$ sysctl -a
hw.cachelinesize: 64
hw.l1icachesize: 32768
hw.l1dcachesize: 32768
hw.l2cachesize: 262144
hw.l3cachesize: 4194304
machdep.cpu.cache.L2_associativity: 4 - CacheLine size:64 Byte
- L1 Data Cache:32KB
- L1 Instruction Cache:32KB
- L2 Cache:256KB
- L3 Cache:4MB
Mac下也可以點選坐上角關於本機 -> 概覽 -> 系統報告來檢視硬體資訊:
下圖是計算機儲存的基本結構。L1、L2、L3分別表示一級快取、二級快取、三級快取。越靠近CPU的快取,速度越快,容量也越小。L1快取小但很快,並且緊靠著在使用它的CPU核心。分為指令快取和資料快取;L2大一些,也慢一些,並仍然只能被一個單獨的CPU核使用;L3更大、更慢,並且被單個插槽上的所有CPU核共享;最後是主存,由全部插槽上的所有CPU核共享。
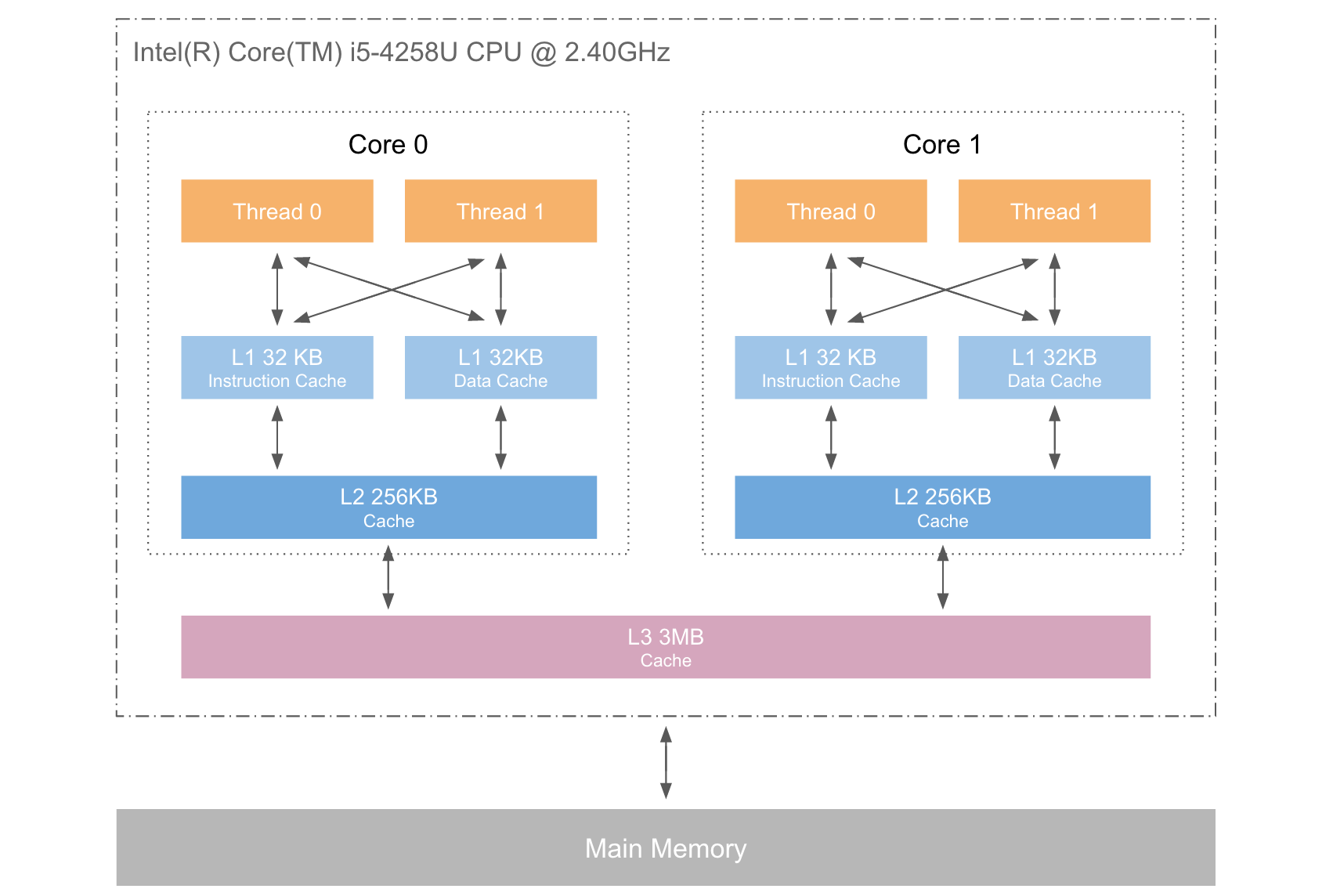
當CPU執行運算的時候,它先去L1查詢所需的資料、再去L2、然後是L3,如果最後這些快取中都沒有,所需的資料就要去主記憶體拿。走得越遠,運算耗費的時間就越長。所以要儘量確保資料在L1快取中。
Martin和Mike的 QCon presentation 演講中給出了一些快取未命中的消耗資料,也就是從CPU訪問不同層級資料的時間概念:
| 從CPU到 | 大約需要的CPU時鐘週期 | 大約需要的時間 |
|---|---|---|
| 主存 | 約60-80ns | |
| QPI 匯流排傳輸(between sockets, not drawn) | 約20ns | |
| L3 cache | 約40-45 cycles | 約15ns |
| L2 cache | 約10 cycles | 約3ns |
| L1 cache | 約3-4 cycles | 約1ns |
| 暫存器 | 1 cycle |
可見CPU讀取主存中的資料會比從L1中讀取慢了近2個數量級。
我們在每隔 64 Byte (cache line size) 訪問 array 一次,訪問固定次數。隨著array的增大,看看能不能測試出 L1, L2 和 L3 cache size 的大小:
/**
* 每隔64Byte訪問陣列固定次數,看Array大小對耗時的影響
*/
public class Test {
public static void main(String[] args) {
for (int ARRAY_SIZE = 512; ARRAY_SIZE <= 128 * 1024 * 1024; ARRAY_SIZE <<= 1) {
int steps = 640 * 1024 * 1024; // Arbitrary number of steps
int length_mod = ARRAY_SIZE - 1;
char[] arr = new char[ARRAY_SIZE];
marked = System.currentTimeMillis();
for (int i = 0; i < steps; i += 64) {
arr[i & length_mod]++; // (i & length_mod) is equal to (i % length_mod)
}
long used = (System.currentTimeMillis() - marked);
System.out.println(formatSize(ARRAY_SIZE) + "\t" + used);
}
}
/**
* 把size單位轉化為KB, MB, GB
*/
public static String formatSize(long size) {
String hrSize = null;
double b = size;
double k = size/1024.0;
double m = ((size/1024.0)/1024.0);
double g = (((size/1024.0)/1024.0)/1024.0);
double t = ((((size/1024.0)/1024.0)/1024.0)/1024.0);
DecimalFormat dec = new DecimalFormat("0");
if ( t>1 ) {
hrSize = dec.format(t).concat(" TB");
} else if ( g>1 ) {
hrSize = dec.format(g).concat(" GB");
} else if ( m>1 ) {
hrSize = dec.format(m).concat(" MB");
} else if ( k>1 ) {
hrSize = dec.format(k).concat(" KB");
} else {
hrSize = dec.format(b).concat(" Bytes");
}
return hrSize;
}
}執行的結果如下:
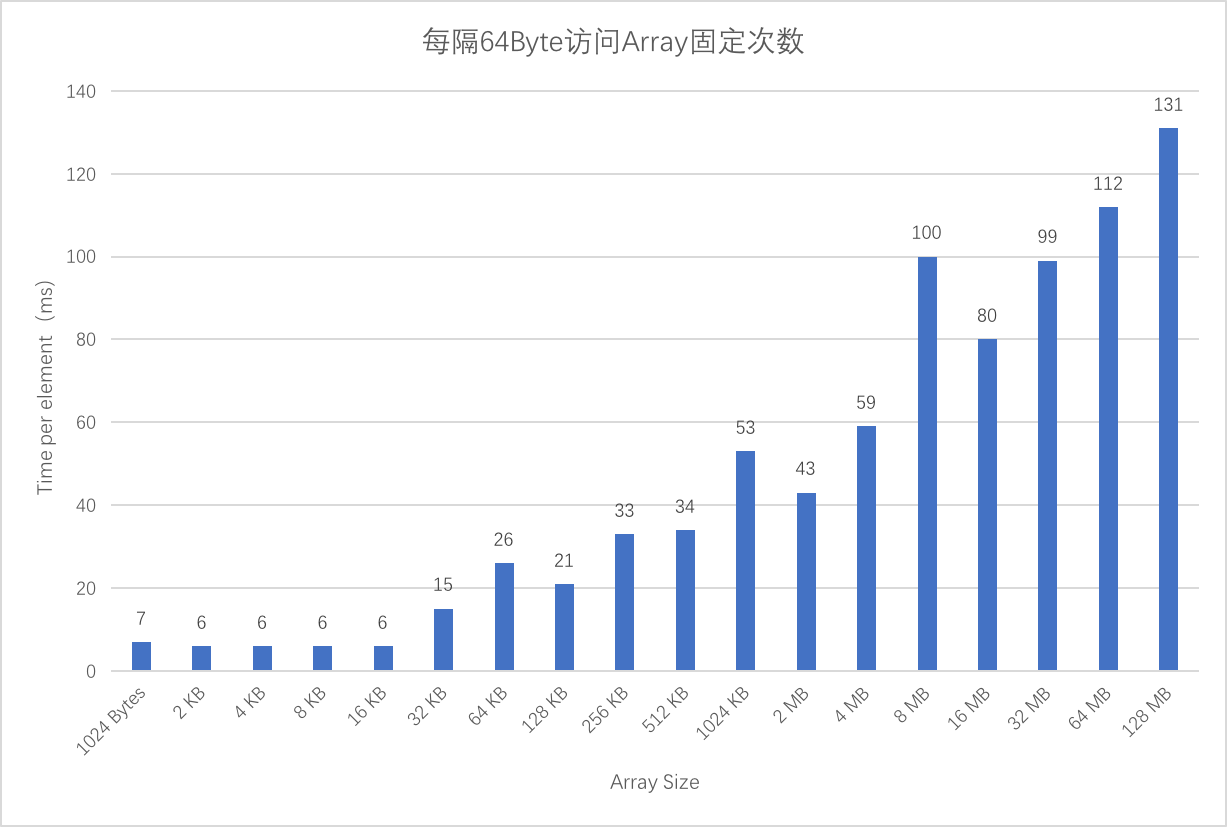
可以看到32KB,256KB,4MB之後耗時均有明顯上升。
快取行Cache Line
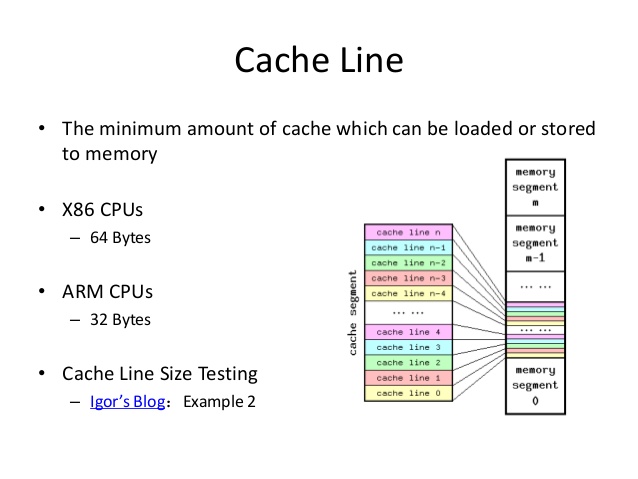
Cache是由很多個 Cache line 組成的。Cache line 是 cache 和 RAM 交換資料的最小單位,通常為 64 Byte。當 CPU 把記憶體的資料載入 cache 時,會把臨近的共 64 Byte 的資料一同放入同一個Cache line,因為空間區域性性:臨近的資料在將來被訪問的可能性大。
以大小為 32 KB,cache line 的大小為 64 Byte 的L1級快取為例,對於不同存放規則,其硬體設計也不同,下圖簡單表示一種設計:

偽共享False Sharing
當多執行緒修改互相獨立的變數時,如果這些變數共享同一個快取行,就會無意中影響彼此的效能,這就是偽共享。快取行上的寫競爭是執行在SMP系統中並行執行緒實現可伸縮性最重要的限制因素。有人將偽共享描述成無聲的效能殺手,因為從程式碼中很難看清楚是否會出現偽共享。
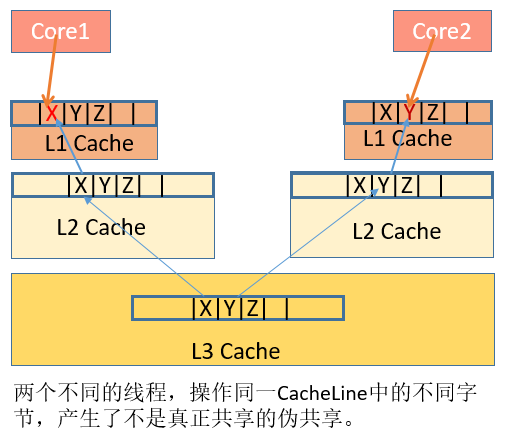
下面我們通過一段程式碼,看看偽共享對效能的影響。
public final class FalseSharingNo implements Runnable {
public final static long ITERATIONS = 500L * 1000L * 100L;
private int arrayIndex = 0;
private static ValuePadding[] longs;
public FalseSharingNo(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
for(int i = 1; i < 10; i++){
System.gc();
final long start = System.currentTimeMillis();
runTest(i);
System.out.println(i + " Threads, duration = " + (System.currentTimeMillis() - start));
}
}
private static void runTest(int NUM_THREADS) throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
longs = new ValuePadding[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new ValuePadding();
}
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharingNo(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = 0L;
}
}
public final static class ValuePadding {
protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
protected long p9, p10, p11, p12, p13, p14;
protected long p15;
}
public final static class ValueNoPadding {
// protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
// protected long p9, p10, p11, p12, p13, p14, p15;
}
}在分別使用 ValuePadding 和 ValueNoPadding 兩種物件,讓多執行緒分別訪問陣列中相鄰的物件,試圖構建一個偽共享的場景。在有Padding填充的情況下,看看執行結果:
1 Threads, duration = 398
2 Threads, duration = 645
3 Threads, duration = 537
4 Threads, duration = 638
5 Threads, duration = 786
6 Threads, duration = 954
7 Threads, duration = 1133
8 Threads, duration = 1286
9 Threads, duration = 1432
把程式碼中 ValuePadding 都替換為 ValueNoPadding 後的結果:
1 Threads, duration = 404
2 Threads, duration = 1250
3 Threads, duration = 1283
4 Threads, duration = 1179
5 Threads, duration = 2510
6 Threads, duration = 2733
7 Threads, duration = 2451
8 Threads, duration = 2652
9 Threads, duration = 2189
Cache Line偽共享解決方案
處理偽共享的兩種方式:
- 位元組填充:增大元素的間隔,使得不同執行緒存取的元素位於不同的cache line上,典型的空間換時間。
- 在每個執行緒中建立對應元素的本地拷貝,結束後再寫回全域性陣列。
我們這裡只看第一種位元組填充。保證不同執行緒的變數存在於不同的 CacheLine 即可,這樣就不會出現偽共享問題。在程式碼層面如何實現圖中的位元組填充呢?
Java6 中實現位元組填充
public class PaddingObject{
public volatile long value = 0L; // 實際資料
public long p1, p2, p3, p4, p5, p6; // 填充
}PaddingObject 類中需要儲存一個 long 型別的 value 值,如果多執行緒操作同一個 CacheLine 中的 PaddingObject 物件,便無法完全發揮出 CPU Cache 的優勢(想象一下你定義了一個 PaddingObject[] 陣列,陣列元素在記憶體中連續,卻由於偽共享導致無法使用 CPU Cache 帶來的沮喪)。
不知道你注意到沒有,實際資料 value + 用於填充的 p1~p6 總共只佔據了 7 * 8 = 56 個位元組,而 Cache Line 的大小應當是 64 位元組,這是有意而為之,在 Java 中,物件頭還佔據了 8 個位元組,所以一個 PaddingObject 物件可以恰好佔據一個 Cache Line。
Java7 中實現位元組填充
在 Java7 之後,一個 JVM 的優化給位元組填充造成了一些影響,上面的程式碼片段 public long p1, p2, p3, p4, p5, p6; 會被認為是無效程式碼被優化掉,有迴歸到了偽共享的窘境之中。
為了避免 JVM 的自動優化,需要使用繼承的方式來填充。
abstract class AbstractPaddingObject{
protected long p1, p2, p3, p4, p5, p6;// 填充
}
public class PaddingObject extends AbstractPaddingObject{
public volatile long value = 0L; // 實際資料
}Tips:實際上我在本地 mac 下測試過 jdk1.8 下的位元組填充,並不會出現無效程式碼的優化,個人猜測和 jdk 版本有關,不過為了保險起見,還是使用相對穩妥的方式去填充較為合適。
Java8 中實現位元組填充
//JDK 8中提供的註解
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD, ElementType.TYPE})
public @interface Contended {
/**
* The (optional) contention group tag.
* This tag is only meaningful for field level annotations.
*
* @return contention group tag.
*/
String value() default "";
}在 JDK 8 裡提供了一個新註解@Contended,可以用來減少false sharing的情況。JVM在計算物件佈局的時候就會自動把標註的欄位拿出來並且插入合適的大小padding。
因為這個功能暫時還是實驗性功能,暫時還沒到預設普及給使用者程式碼用的程度。要在使用者程式碼(非bootstrap class loader或extension class loader所載入的類)中使用@Contended註解的話,需要使用 -XX:-RestrictContended 引數。
比如在JDK 8的 ConcurrentHashMap 原始碼中,使用 @sun.misc.Contended對靜態內部類 CounterCell 進行了修飾。
/* ---------------- Counter support -------------- */
/**
* A padded cell for distributing counts. Adapted from LongAdder
* and Striped64. See their internal docs for explanation.
*/
@sun.misc.Contended
static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}Thread
Thread 執行緒類的原始碼中,使用 @sun.misc.Contended 對成員變數進行修飾。
// The following three initially uninitialized fields are exclusively
// managed by class java.util.concurrent.ThreadLocalRandom. These
// fields are used to build the high-performance PRNGs in the
// concurrent code, and we can not risk accidental false sharing.
// Hence, the fields are isolated with @Contended.
/** The current seed for a ThreadLocalRandom */
@sun.misc.Contended("tlr")
long threadLocalRandomSeed;
/** Probe hash value; nonzero if threadLocalRandomSeed initialized */
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
/** Secondary seed isolated from public ThreadLocalRandom sequence */
@sun.misc.Contended("tlr")
int threadLocalRandomSecondarySeed;RingBuffer
來源於一款優秀的開源框架 Disruptor 中的一個數據結構 RingBuffer。
abstract class RingBufferPad {
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields<E> extends RingBufferPad{}使用位元組填充和繼承的方式來避免偽共享。
面試題擴充套件
問:說說陣列和連結串列這兩種資料結構有什麼區別?
問:快速排序和堆排序兩種排序演算法各自的優缺點是什麼?
瞭解了 CPU Cache 和 Cache Line 之後想想可不可以有一些特殊的回答技巧呢?