
偽共享、快取行填充以及CPU快取機制
關於偽共享的一篇好文,轉載自:
1.認識CPU Cache
CPU Cache概述
隨著CPU的頻率不斷提升,而記憶體的訪問速度卻沒有質的突破,為了彌補訪問記憶體的速度慢,充分發揮CPU的計算資源,提高CPU整體吞吐量,在CPU與記憶體之間引入了一級Cache。隨著熱點資料體積越來越大,一級Cache L1已經不滿足發展的要求,引入了二級Cache L2,三級Cache L3。(注:若無特別說明,本文的Cache指CPU Cache,快取記憶體)CPU Cache在儲存器層次結構中的示意如下圖:
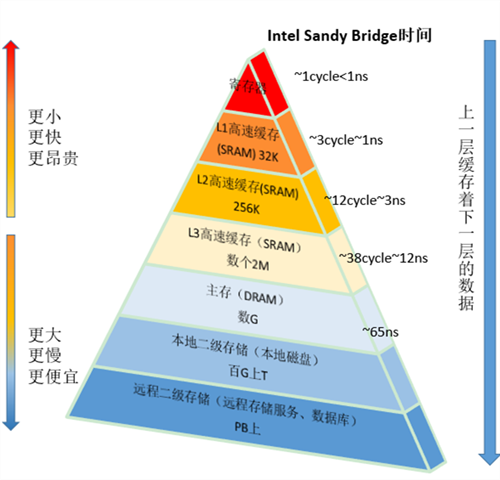
計算機早已進入多核時代,軟體也越來越多的支援多核執行。一個處理器對應一個物理插槽,多處理器間通過QPI匯流排相連。一個處理器包含多個核,一個處理器間的多核共享L3 Cache。一個核包含暫存器、L1 Cache、L2 Cache,下圖是Intel Sandy Bridge CPU架構,一個典型的NUMA多處理器結構:
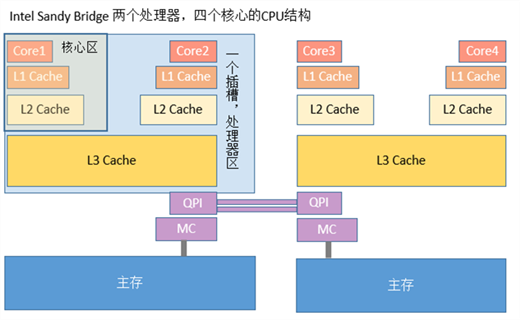
作為程式設計師,需要理解計算機儲存器層次結構,它對應用程式的效能有巨大的影響。如果需要的程式是在CPU暫存器中的,指令執行時1個週期內就能訪問到他們。如果在CPU Cache中,需要1~30個週期;如果在主存中,需要50~200個週期;在磁碟上,大概需要幾千萬個週期。充分利用它的結構和機制,可以有效的提高程式的效能。
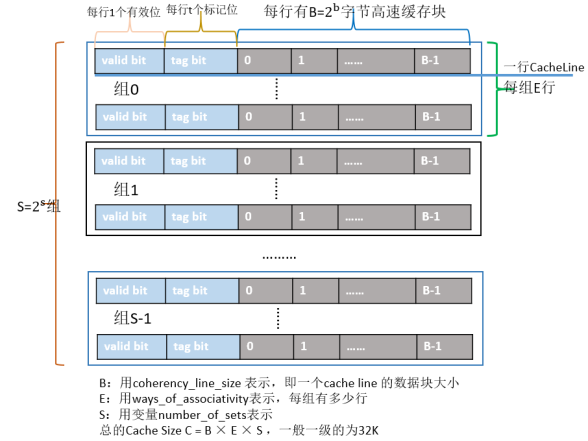
以我們常見的X86晶片為例,Cache的結構下圖所示:整個Cache被分為S個組,每個組是又由E行個最小的儲存單元——Cache Line所組成,而一個Cache Line中有B(B=64)個位元組用來儲存資料,即每個Cache Line能儲存64個位元組的資料,每個Cache Line又額外包含一個有效位(valid bit)、t個標記位(tag bit),其中valid bit用來表示該快取行是否有效;tag bit用來協助定址,唯一標識儲存在CacheLine中的塊;而Cache Line裡的64個位元組其實是對應記憶體地址中的資料拷貝。根據Cache的結構題,我們可以推算出每一級Cache的大小為B×E×S。
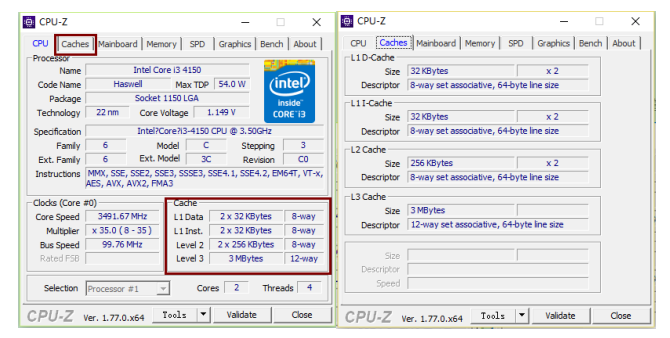
那麼如何檢視自己電腦CPU的Cache資訊呢?
在windows下檢視方式有多種方式,其中最直觀的是,通過安裝CPU-Z軟體,直接顯示Cache資訊,如下圖:
此外,Windows下還有兩種方法:
①Windows API呼叫GetLogicalProcessorInfo。
②通過命令列系統內部工具CoreInfo。
如果是Linux系統, 可以使用下面的命令檢視Cache資訊:
ls /sys/devices/system/cpu/cpu0/cache/index0
還有lscpu等命令也可以檢視相關資訊,如果是Mac系統,可以用sysctl machdep.cpu 命令檢視cpu資訊。
如果我們用Java程式設計,還可以通過CacheSize API方式來獲取Cache資訊, CacheSize是一個谷歌的小專案,java語言通過它可以進行訪問本機Cache的資訊。示例程式碼如下:
public static void main(String[] args) throws CacheNotFoundException {
CacheInfo info = CacheInfo.getInstance();
CacheLevelInfo l1Datainf = info.getCacheInformation(CacheLevel.L1, CacheType.DATA_CACHE);
System.out.println("第一級資料快取資訊:"+l1Datainf.toString());
CacheLevelInfo l1Instrinf = info.getCacheInformation(CacheLevel.L1, CacheType.INSTRUCTION_CACHE);
System.out.println("第一級指令快取資訊:"+l1Instrinf.toString());
}列印輸出結果如下:
第一級資料快取資訊:CacheLevelInfo [cacheLevel=L1, cacheType=DATA_CACHE, cacheSets=64, cacheCoherencyLineSize=64, cachePhysicalLinePartitions=1, cacheWaysOfAssociativity=8, isFullyAssociative=false, isSelfInitializing=true, totalSizeInBytes=32768]
第一級指令快取資訊:CacheLevelInfo [cacheLevel=L1, cacheType=INSTRUCTION_CACHE, cacheSets=64, cacheCoherencyLineSize=64, cachePhysicalLinePartitions=1, cacheWaysOfAssociativity=8, isFullyAssociative=false, isSelfInitializing=true, totalSizeInBytes=32768]還可以查詢L2、L3級快取的資訊,這裡不做示例。從列印的資訊和CPU-Z顯示的資訊可以看出,本機的Cache資訊是一致的,L1資料/指令快取大小都為:C=B×E×S=64×8×64=32768位元組=32KB。
Cache Line偽共享及解決方案
Cache Line偽共享分析
說偽共享前,先看看Cache Line 在java程式設計中使用的場景。如果CPU訪問的記憶體資料不在Cache中(一級、二級、三級),這就產生了Cache Line miss問題,此時CPU不得不發出新的載入指令,從記憶體中獲取資料。通過前面對Cache儲存層次的理解,我們知道一旦CPU要從記憶體中訪問資料就會產生一個較大的時延,程式效能顯著降低,所謂遠水救不了近火。為此我們不得不提高Cache命中率,也就是充分發揮區域性性原理。
區域性性包括時間區域性性、空間區域性性。時間區域性性:對於同一資料可能被多次使用,自第一次載入到Cache Line後,後面的訪問就可以多次從Cache Line中命中,從而提高讀取速度(而不是從下層快取讀取)。空間區域性性:一個Cache Line有64位元組塊,我們可以充分利用一次載入64位元組的空間,把程式後續會訪問的資料,一次性全部載入進來,從而提高Cache Line命中率(而不是重新去定址讀取)。
看個例子:記憶體地址是連續的陣列(利用空間區域性性),能一次被L1快取載入完成。
如下程式碼,長度為16的row和column陣列,在Cache Line 64位元組資料塊上記憶體地址是連續的,能被一次載入到Cache Line中,所以在訪問陣列時,Cache Line命中率高,效能發揮到極致。
public int run(int[] row, int[] column) {
int sum = 0;
for(int i = 0; i < 16; i++ ) {
sum += row[i] * column[i];
}
return sum;
}而上面例子中變數i則體現了時間區域性性,i作為計數器被頻繁操作,一直存放在暫存器中,每次從暫存器訪問,而不是從主存甚至磁碟訪問。雖然連續緊湊的記憶體分配帶來高效能,但並不代表它一直都能帶來高效能。如果把它放在多執行緒中將會發生什麼呢?如圖:
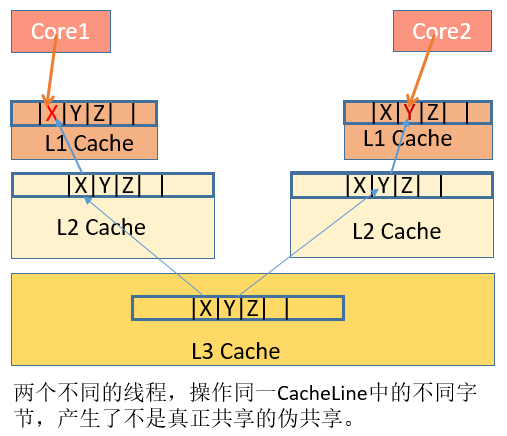
資料X、Y、Z被載入到同一Cache Line中,執行緒A在Core1修改X,執行緒B在Core2上修改Y。根據MESI大法,假設是Core1是第一個發起操作的CPU核,Core1上的L1 Cache Line由S(共享)狀態變成M(修改,髒資料)狀態,然後告知其他的CPU核,圖例則是Core2,引用同一地址的Cache Line已經無效了;當Core2發起寫操作時,首先導致Core1將X寫回主存,Cache Line狀態由M變為I(無效),而後才是Core2從主存重新讀取該地址內容,Cache Line狀態由I變成E(獨佔),最後進行修改Y操作, Cache Line從E變成M。可見多個執行緒操作在同一Cache Line上的不同資料,相互競爭同一Cache Line,導致執行緒彼此牽制影響,變成了序列程式,降低了併發性。此時我們則需要將共享在多執行緒間的資料進行隔離,使他們不在同一個Cache Line上,從而提升多執行緒的效能。
Cache Line偽共享處理方案
處理偽共享的兩種方式:
- 增大陣列元素的間隔使得不同執行緒存取的元素位於不同的cache line上。典型的空間換時間。(Linux cache機制與之相關)
- 在每個執行緒中建立全域性陣列各個元素的本地拷貝,然後結束後再寫回全域性陣列。
在Java類中,最優化的設計是考慮清楚哪些變數是不變的,哪些是經常變化的,哪些變化是完全相互獨立的,哪些屬性一起變化。舉個例子:
public class Data{
long modifyTime;
boolean flag;
long createTime;
char key;
int value;
}假如業務場景中,上述的類滿足以下幾個特點:
- 當value變數改變時,modifyTime肯定會改變
- createTime變數和key變數在建立後,就不會再變化。
- flag也經常會變化,不過與modifyTime和value變數毫無關聯。
當上面的物件需要由多個執行緒同時的訪問時,從Cache角度來說,就會有一些有趣的問題。當我們沒有加任何措施時,Data物件所有的變數極有可能被載入在L1快取的一行Cache Line中。在高併發訪問下,會出現這種問題:
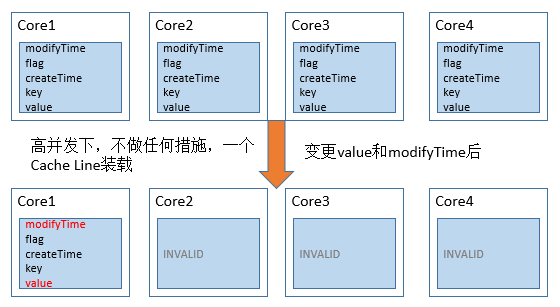
如上圖所示,每次value變更時,根據MESI協議,物件其他CPU上相關的Cache Line全部被設定為失效。其他的處理器想要訪問未變化的資料(key 和 createTime)時,必須從記憶體中重新拉取資料,增大了資料訪問的開銷。
Padding 方式
正確的方式應該將該物件屬性分組,將一起變化的放在一組,與其他屬性無關的屬性放到一組,將不變的屬性放到一組。這樣當每次物件變化時,不會帶動所有的屬性重新載入快取,提升了讀取效率。在JDK1.8以前,我們一般是在屬性間增加長整型變數來分隔每一組屬性。被操作的每一組屬性佔的位元組數加上前後填充屬性所佔的位元組數,不小於一個cache line的位元組數就可以達到要求:
public class DataPadding{
long a1,a2,a3,a4,a5,a6,a7,a8;//防止與前一個物件產生偽共享
int value;
long modifyTime;
long b1,b2,b3,b4,b5,b6,b7,b8;//防止不相關變數偽共享;
boolean flag;
long c1,c2,c3,c4,c5,c6,c7,c8;//
long createTime;
char key;
long d1,d2,d3,d4,d5,d6,d7,d8;//防止與下一個物件產生偽共享
}通過填充變數,使不相關的變數分開
Contended註解方式
在JDK1.8中,新增了一種註解@sun.misc.Contended,來使各個變數在Cache line中分隔開。注意,jvm需要新增引數-XX:-RestrictContended才能開啟此功能
用時,可以在類前或屬性前加上此註釋:
// 類前加上代表整個類的每個變數都會在單獨的cache line中
@sun.misc.Contended
@SuppressWarnings("restriction")
public class ContendedData {
int value;
long modifyTime;
boolean flag;
long createTime;
char key;
}
或者這種:
// 屬性前加上時需要加上組標籤
@SuppressWarnings("restriction")
public class ContendedGroupData {
@sun.misc.Contended("group1")
int value;
@sun.misc.Contended("group1")
long modifyTime;
@sun.misc.Contended("group2")
boolean flag;
@sun.misc.Contended("group3")
long createTime;
@sun.misc.Contended("group3")
char key;
}採取上述措施圖示:
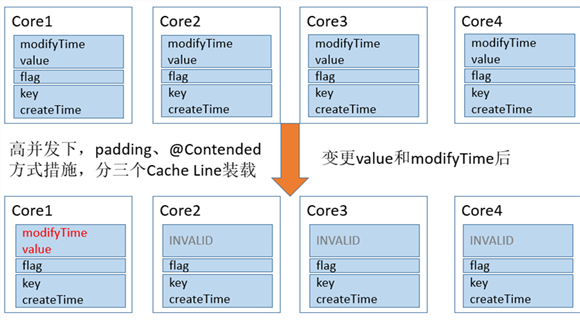
JDK1.8 ConcurrentHashMap的處理
java.util.concurrent.ConcurrentHashMap在這個如雷貫耳的Map中,有一個很基本的操作問題,在併發條件下進行++操作。因為++這個操作並不是原子的,而且在連續的Atomic中,很容易產生偽共享(false sharing)。所以在其內部有專門的資料結構來儲存long型的資料:
(openjdk\jdk\src\share\classes\java\util\concurrent\ConcurrentHashMap.java line:2506):
/* ---------------- Counter support -------------- */
/**
* A padded cell for distributing counts. Adapted from LongAdder
* and Striped64. See their internal docs for explanation.
*/
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}我們看到該類中,是通過@sun.misc.Contended達到防止false sharing的目的
JDK1.8 Thread 的處理
java.lang.Thread在java中,生成隨機數是和執行緒有著關聯。而且在很多情況下,多執行緒下產生隨機數的操作是很常見的,JDK為了確保產生隨機數的操作不會產生false sharing ,把產生隨機數的三個相關值設為獨佔cache line。
(openjdk\jdk\src\share\classes\java\lang\Thread.java line:2023)
// The following three initially uninitialized fields are exclusively
// managed by class java.util.concurrent.ThreadLocalRandom. These
// fields are used to build the high-performance PRNGs in the
// concurrent code, and we can not risk accidental false sharing.
// Hence, the fields are isolated with @Contended.
/** The current seed for a ThreadLocalRandom */
@sun.misc.Contended("tlr")
long threadLocalRandomSeed;
/** Probe hash value; nonzero if threadLocalRandomSeed initialized */
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
/** Secondary seed isolated from public ThreadLocalRandom sequence */
@sun.misc.Contended("tlr")
int threadLocalRandomSecondarySeed;Java中對Cache line經典設計
Disruptor框架
認識Disruptor
LMAX是在英國註冊並受到FCA監管的外匯黃金交易所。也是歐洲第一家也是唯一一家採用多邊交易設施Multilateral Trading Facility(MTF)擁有交易所牌照和經紀商牌照的歐洲頂級金融公司。LMAX的零售金融交易平臺,是建立在JVM平臺上,核心是一個業務邏輯處理器,它能夠在一個執行緒裡每秒處理6百萬訂單。業務邏輯處理器的核心就是Disruptor(注,本文Disruptor基於當前最新3.3.6版本),這是一個Java實現的併發元件,能夠在無鎖的情況下實現網路的Queue併發操作,它確保任何資料只由一個執行緒擁有以進行寫訪問,從而消除寫爭用的設計, 這種設計被稱作“破壞者”,也是這樣命名這個框架的。
Disruptor是一個執行緒內通訊框架,用於執行緒裡共享資料。與LinkedBlockingQueue類似,提供了一個高速的生產者消費者模型,廣泛用於批量IO讀寫,在硬碟讀寫相關的程式中應用的十分廣泛,Apache旗下的HBase、Hive、Storm等框架都有在使用Disruptor。LMAX 建立Disruptor作為可靠訊息架構的一部分,並將它設計成一種在不同元件中共享資料非常快的方法。Disruptor執行大致流程入下圖:
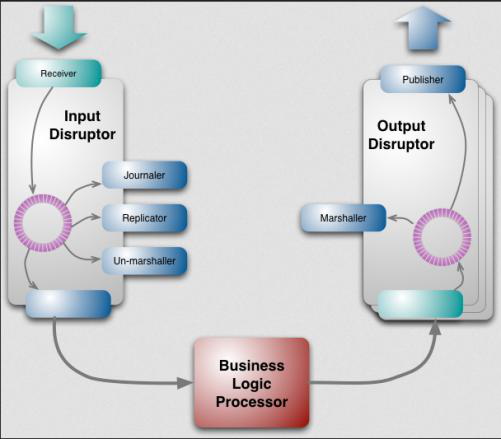
圖中左側(Input Disruptor部分)可以看作多生產者單消費者模式。外部多個執行緒作為多生產者併發請求業務邏輯處理器(Business Logic Processor),這些請求的資訊經過Receiver存放在粉紅色的圓環中,業務處理器則作為消費者從圓環中取得資料進行處理。右側(Output Disruptor部分)則可看作單生產者多消費者模式。業務邏輯處理器作為單生產者,釋出資料到粉紅色圓環中,Publisher作為多個消費者接受業務邏輯處理器的結果。這裡兩處地方的資料共享都是通過那個粉紅色的圓環,它就是Disruptor的核心設計RingBuffer。
Disruptor特點
- 無鎖機制。
- 沒有CAS操作,避免了記憶體屏障指令的耗時。
- 避開了Cache line偽共享的問題,也是Disruptor部分主要關注的主題。
Disruptor對偽共享的處理
RingBuffer類
RingBuffer類(即上節中粉紅色的圓環)的類關係圖如下:
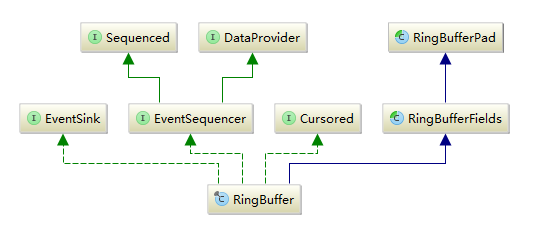
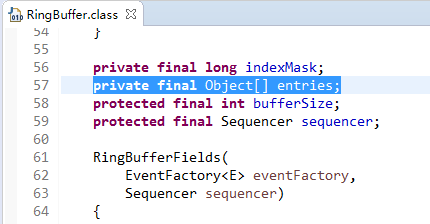
通過原始碼分析,RingBuffer的父類,RingBufferFields採用陣列來實現存放執行緒間的共享資料。下圖,第57行,entries陣列。
前面分析過陣列比連結串列、樹更具有快取友好性,此處不做細表。不使用LinkedBlockingQueue佇列,是基於無鎖機制的考慮。詳細分析可參考,併發程式設計網的翻譯。這裡我們主要分析RingBuffer的繼承關係中的填充,解決快取偽共享問題。如下圖:
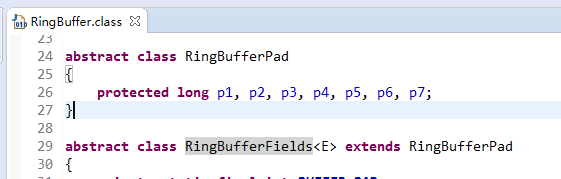
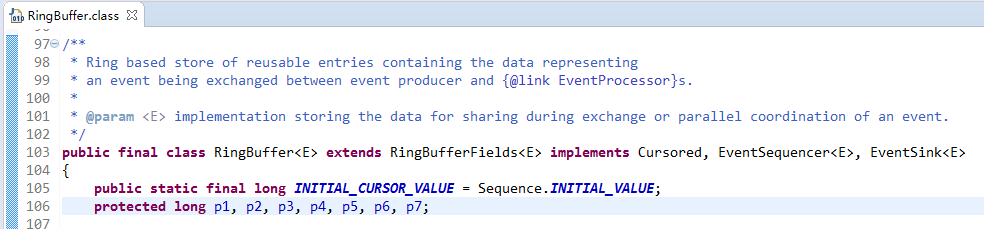
依據JVM物件繼承關係中父類屬性與子類屬性,記憶體地址連續排列布局,RingBufferPad的protected long p1,p2,p3,p4,p5,p6,p7;作為快取前置填充,RingBuffer中的protected long p1,p2,p3,p4,p5,p6,p7;作為快取後置填充。這樣任意執行緒訪問RingBuffer時,RingBuffer放在父類RingBufferFields的屬性,都是獨佔一行Cache line不會產生偽共享問題。如圖,RingBuffer的操作欄位在RingBufferFields中,使用rbf標識:
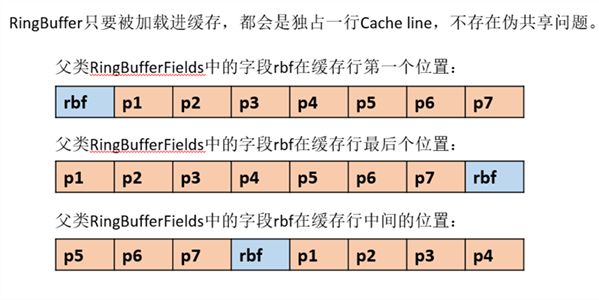
按照一行快取64位元組計算,前後填充56位元組(7個long),中間大於等於8位元組的內容都能獨佔一行Cache line,此處rbf是大於8位元組的。
Sequence類
Sequence類用來跟蹤RingBuffer和事件處理器的增長步數,支援多個併發操作包括CAS指令和寫指令。同時使用了Padding方式來實現,如下為其類結構圖及Padding的類。
Sequence裡在volatile long value前後放置了7個long padding,來解決偽共享的問題。示意如圖,此處Value等於8位元組:
也許讀者應該會認為這裡的圖示比上面RingBuffer的圖示更好理解,這裡的操作屬性只有一個value,兩個圖相互結合就更能理解了。
Sequencer的實現
在RingBuffer建構函式裡面存在一個Sequencer介面,用來遍歷資料,在生產者和消費者之間傳遞資料。Sequencer有兩個實現類,單生產者模式的實現SingleProducerSequencer與多生產者模式的實現MultiProducerSequencer。它們的類結構如圖:
單生產者是在Cache line中使用padding方式實現,原始碼如下:
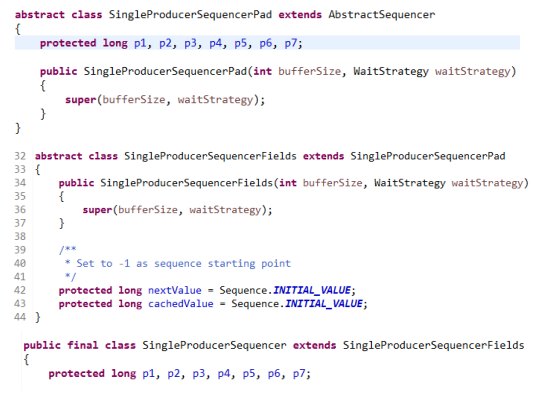
多生產者則是使用 sun.misc.Unsafe來實現的。如下圖:
總結與使用示例
可見padding方式在Disruptor中是處理偽共享常見的方式,JDK1.8的@Contended很好的解決了這個問題,不知道Disruptor後面的版本是否會考慮使用它。
Disruptor使用示例程式碼參考地址。
參考資料:

相關推薦
偽共享、快取行填充以及CPU快取機制
關於偽共享的一篇好文,轉載自: 1.認識CPU Cache CPU Cache概述 隨著CPU的頻率不斷提升,而記憶體的訪問速度卻沒有質的突破,為了彌補訪問記憶體的速度慢,充分發揮CPU的計算資源,提高CPU整體吞吐量,在CPU與記憶體之間引入了一級Cach
快取行、cpu偽共享和快取行填充
由於在看disruptor時瞭解到快取行,以及快取行填充的問題,所以各處瞭解記在這裡 一、快取行 CPU 為了更快的執行程式碼。於是當從記憶體中讀取資料時,並不是只讀自己想要的部分。而是讀取足夠的位元組來填入快取記憶體行。根據不同的 CPU ,快取記憶體
偽共享問題-java快取行填充
原理:解決偽共享的辦法是使用快取行填充,使一個物件佔用的記憶體大小剛好為64bytes或它的整數倍,這樣就保證了一個快取行裡不會有多個物件。 JDK1.8 @Contended 執行時,必須加上虛擬機器引數-XX:-RestrictContended,@Cont
剖析Disruptor:為什麼會這麼快?(二)神奇的快取行填充
作者:Trisha 譯者:方騰飛 校對:丁一 我們經常提到一個短語Mechanical Sympathy,這個短語也是Martin部落格的標題(譯註:Martin Thompson),Mechanical Sympathy講的是底層硬體是如何運作的,以及與其協作而非相悖的程式設計方式。 我
disruptor --神奇的快取行填充1
CPU是你機器的心臟,最終由它來執行所有運算和程式。主記憶體(RAM)是你的資料(包括程式碼行)存放的地方。本文將忽略硬體驅動和網路之類的東西,因為Disruptor的目標是儘可能多的在記憶體中執行。 CPU和主記憶體之間有好幾層快取,因為即使直接訪問主記憶體
併發程式設計---填充快取行消除偽共享
快取行最常見的是64位元組。 需要獨佔的屬性的左填充7個位元組,右填充7個位元組。 由於JAVA7中會優化掉無用欄位。 所以要採用繼承的方式繞過優化。 class LhsPadding{ protected long p1,p2,p3,p4,p5,p6,p7; } class V
從快取行出發理解volatile變數、偽共享False sharing、disruptor
volatile關鍵字 當變數被某個執行緒A修改值之後,其它執行緒比如B若讀取此變數的話,立刻可以看到原來執行緒A修改後的值 注:普通變數與volatile變數的區別是volatile的特殊規則保證了新值能立即同步到主記憶體,以及每次使用前可以立即從記憶體重新整理,
cpu快取偽共享
/** * @描述 * @引數 $ * @返回值 $ * @建立人 [email protected] * @建立時間 $ * @修改人和其它資訊 */ public class FadeShare implements Runnable{
Linux 進程、線程運行在指定CPU核上
linux 進程 深圳 pre clas work http 文檔 blog bsp /******************************************************************************** *
CPU Cache與快取行
引言 先看下面這兩個迴圈遍歷哪個快? int[][] array = new int[64 * 1024][1024]; // 橫向遍歷 for(int i = 0; i < 64 * 1024; i ++) for(int j = 0; j < 10
基於JVM原理、JMM模型和CPU快取模型深入理解Java併發程式設計
許多以Java多執行緒開發為主題的技術書籍,都會把對Java虛擬機器和Java記憶體模型的講解,作為講授Java併發程式設計開發的主要內容,有的還深入到計算機系統的記憶體、CPU、快取等予以說明。實際上,在實際的Java開發工作中,僅僅瞭解併發程式設計的建立、啟動、管理和通訊等基本知識還是不夠的。一
Linux伺服器記憶體、CPU、檔案系統、磁碟IO效能以及網路連通性shell巡檢
shell自動巡檢伺服器基礎配置 每個專案都要部署在伺服器上,那麼伺服器的安全效能和一些基本情況是我們需要了解的,比如伺服器CPU、記憶體、檔案系統、磁碟IO、還有一些網路連通性
高併發、低延遲之C#玩轉CPU快取記憶體(附示例)
寫在前面 好久沒有寫部落格了,一直在不斷地探索響應式DDD,又get到了很多新知識,解惑了很多老問題,最近讀了Martin Fowler大師一篇非常精彩的部落格The LMAX Architecture,裡面有一個術語Mechanical Sympathy,姑且翻譯成軟硬體協同程式設計(Hardware an
Python獲取一段文章中字母出現頻率前5的字母以及個數(去除空格、換行符等,只算字母)
import time,re from collections import Counter text = 'A friend of mine named Paul received an automobile from his brother as Christmas present.
SpringBoot+Redis+Nginx實現負載均衡以及Session快取共享
1.環境資訊 nginx-1.11.10 redis-latest包(redis windows版本) springboot1.5.1.RELEASE 3.nginx和redis解壓縮即可,並正常啟動 4.springboot整合Redis以及springboot,需要在POM檔案中增加依賴
24、你一般是如何應對快取雪崩以及穿透問題的?
1、面試題 瞭解什麼是redis的雪崩和穿透?redis崩潰之後會怎麼樣?系統該如何應對這種情況?如何處理redis的穿透? 2、面試官心裡分析 其實這是問到快取必問的,因為快取雪崩和穿透,那是快取最大的兩個問題,要麼不出現,一旦出現就是致命性的問題。所以面試官一定會問你。 3、面試
程序、執行緒以及CPU排程
一、程序概念 程序是執行中的程式,形成所有計算的基礎。更完整的解釋是一個具有獨立功能的程式關於某個資料集合的一次執行活動。它可以申請和擁有系統資源,是一個動態的概念,是一個活動的實體。它不只是程式的程
百度開源分散式id生成器uid-generator原始碼剖析 偽共享(false sharing),併發程式設計無聲的效能殺手 一個Java物件到底佔用多大記憶體? 寫Java也得了解CPU--偽共享
百度uid-generator原始碼 https://github.com/baidu/uid-generator snowflake演算法 uid-generator是基於Twitter開源的snowflake演算法實現的。 snowflake將long的64位分為了3部分,時間戳、
百度uid-generator原始碼 偽共享(false sharing),併發程式設計無聲的效能殺手 一個Java物件到底佔用多大記憶體? 寫Java也得了解CPU--偽共享
https://github.com/baidu/uid-generator snowflake演算法 uid-generator是基於Twitter開源的snowflake演算法實現的。 snowflake將long的64位分為了3部分,時間戳、工作機器id和序列號,位數分配如下。
JAVAWEB開發之Hibernate詳解(二)——Hibernate的持久化類狀態與轉換、以及一級快取詳解、關聯關係的對映(一對多、多對多、級聯)
package cn.test.hibernate3.demo2; import org.hibernate.Session; import org.hibernate.Transaction; import org.junit.Test; import cn.test.hibernate3.demo2.