
關於ANSI,unicode與utf-8的區別
關於ANSI,unicode與utf-8的區別
為使計算機支援更多語言,通常使用 0x80~0xFFFF 範圍的 2 個 位元組來表示 1 個字元。比如:漢字 '中' 在 ANSI編碼
中文作業系統中,使用 [0xD6,0xD0] 這兩個位元組儲存。
不同的國家和地區制定了不同的標準,由此產生了
GB2312、GBK、GB18030、Big5、Shift_JIS
等各自的編碼標準。這些使用多個位元組來代表一個字元的各種漢字延伸編碼方式,稱為 ANSI 編碼。在簡體中文Windows作業系統中,ANSI 編碼代表 GBK 編碼;在繁體中文Windows作業系統中,ANSI編碼代表Big5;在日文Windows作業系統中,ANSI 編碼代表 Shift_JIS 編碼。
ANSI編碼
中文作業系統中,使用 [0xD6,0xD0] 這兩個位元組儲存。
不同的國家和地區制定了不同的標準,由此產生了
GB2312、GBK、GB18030、Big5、Shift_JIS
等各自的編碼標準。這些使用多個位元組來代表一個字元的各種漢字延伸編碼方式,稱為 ANSI 編碼。在簡體中文Windows作業系統中,ANSI 編碼代表 GBK 編碼;在繁體中文Windows作業系統中,ANSI編碼代表Big5;在日文Windows作業系統中,ANSI 編碼代表 Shift_JIS 編碼。非常好的一篇文章,值得一看,特轉之
關於編碼ansi、GB2312、unicode與utf-8的區別
先做一個小小的試驗:
在一個資料夾裡,把一個txt文字(文本里包含“今天的天氣非常好”這句話)分別另存為ansi、unicode、utf-8這三種編碼的txt檔案。然後,在該資料夾上點選右鍵,選擇“搜尋(E)…”。

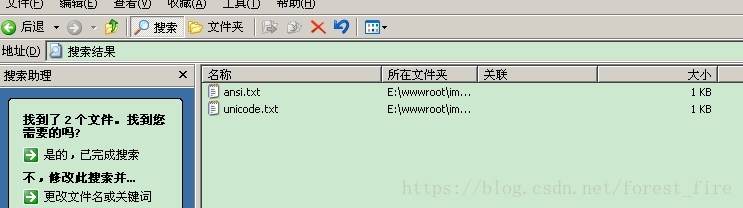
搜尋“天氣”二字,可以搜尋出ansi和unicode這兩種編碼的txt檔案,搜尋不出utf-8編碼的檔案。
原因:
1.中文作業系統預設ansi編碼,生成的txt檔案預設為ansi編碼,所以,可以搜尋出來。
2.unicode是國際通用編碼,所以,可以搜尋出來。
3.utf-8編碼是unicode編碼在網路之間(主要是網頁)傳輸時的一種“變通”和“橋樑”編碼。utf-8在網路之間傳輸時可以節約資料量。所以,使用作業系統無法搜尋出txt文字。
按照utf-8創始人的願望:
端(unicode)——傳輸(utf-8)——端(unicode)
但是,後來,許多網站開發者在開發網頁時直接使用utf-8編碼。
端(utf-8)——傳輸(utf-8)——端(utf-8)
所以,在瀏覽器上看到的編碼是:unicode(utf-8)。正因為在瀏覽器上這麼並列地列出unicode(utf-8),造成許多網友(甚至不少程式設計師)誤認為unicode=utf-8。其實,按照utf-8創始人的原意,在開發網頁時使用utf-8編碼是錯誤的做法,並且,早期的瀏覽器也不支援解析utf-8編碼。但是,眾人的力量是巨大的,微軟不得不“趨炎附勢”,在瀏覽器上支援解析utf-8編碼。
問題是:utf-8編碼影響了網站開發者,或者說,網站開發者“擴充套件”了utf-8編碼的使用範圍。但是,網站開發者仍然無法影響各類文件的開發者,所以,word文件和一些國際通用的文件仍然使用unicode編碼而不使用utf-8編碼。
比如:“嚴”的Unicode碼是4E25,UTF-8編碼是E4B8A5,兩者是不一樣的。
在中文和日文作業系統裡生成的(txt和xml)檔案的編碼雖然都是ansi,但是,在簡體中文系統下,ansi 編碼代表 GB2312 編碼,在日文作業系統下,ansi 編碼代表 JIS 編碼。不同 ansi 編碼之間互不相容,當資訊在國際間交流時,無法將屬於兩種語言的文字,儲存在同一段 ansi 編碼的文字中。
結論:國際文件(txt和xml)使用unicode編碼是正宗做法;作業系統和瀏覽器都能夠“理解”unicode編碼。瀏覽器“迫於壓力”才“理解”utf-8編碼。但是,作業系統有時只認unicode編碼。
Unicode與Unicode big endian的區別:你吃雞蛋時先吃小頭還是先吃大頭?Unicode與Unicode big endian的區別就是在編碼時小頭優先與大頭優先的區別。“隨波逐流”使用Unicode就OK了