
Rich feature hierarchies for accurate object detection and semantic segmentation(理解)
0 - 背景
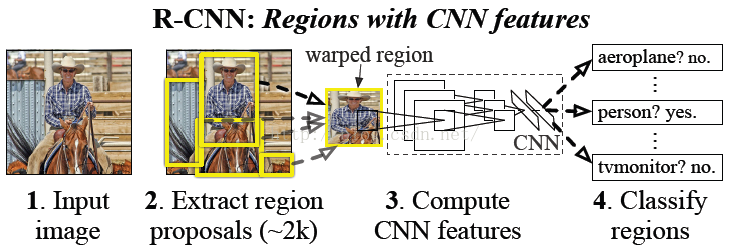
該論文是2014年CVPR的經典論文,其提出的模型稱為R-CNN(Regions with Convolutional Neural Network Features),曾經是物體檢測領域的state-of-art模型。
1 - 相關知識補充
1.1 - Selective Search
該演算法用來產生粗選的regions區域,在我的另一篇博文Selective Search for Object Recognition(理解)中進行詳細講解。
1.2 - 無監督預訓練&有監督預訓練
1.2.1 - 無監督預訓練(Unsupervised pre-traning)
棧式自編碼、DBM採用的都是無監督預訓練,預訓練階段樣本不需要人工標註資料。(詳細思路後續再進行補充)
1.2.2 - 有監督預訓練(Supervised pre-training)
有監督預訓練可以稱為遷移學習,通過在別的訓練集上訓練好網路之後將引數作為當前任務網路的初始化引數,相比直接採用隨機初始化等方法其精度有很大提高。
在該論文提出的時候,圖片分類的訓練資料相比物體檢測的資料多得多,因此通過用分類資料集預訓練網路而後再將引數用於目標檢測網路引數的初始化,是該論文的一個亮點。
1.3 - IOU
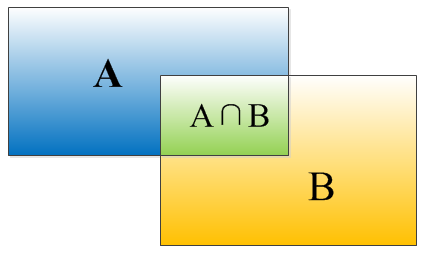
IOU是演算法給出的bounding box和真實box的匹配程度,其計算公式為$IOU=\frac{(A\cap B)}{(A\cup B)}$,等價於$IOU=\frac{S_I}{(S_A+S_B-S_I)}$
1.4 - 非極大值抑制
如下圖,在檢測一個目標時候演算法可能會給出一堆的bounding boax,這時候需要判斷哪些bounding box是沒用的,將它們丟掉。先假設有6個bounding box,根據分類器類別分類概率做排序,從小到大分別屬於目標概率為A、B、C、D、E、F。
- 從最大概率矩形框F開始,分別判斷A~E與F的重疊度IOU時候大於設定的閾值
- 假設B、D與F的重疊度超過閾值,那麼就丟掉B、D;並標記第一個bounding box F是我們保留下來的
- 從剩下的bounding box A、C、E中,選擇概率最大的E,然後判斷A、C與E的重疊度,重疊度大於閾值就扔掉,並標記E是我們保留下來的第二個bounding box
- 重複上述過程,找到所有被保留下來的bounding box

2 - 總體思路
首先輸入一張圖片,通過selective search定位出2000個物體檢測框,然後採用CNN提取每個候選框中圖片的特徵向量,特徵向量的維度為4096維,而後採用線性SVM對每個特徵向量進行分類。概括起來有如下三個步驟:
- 找出候選框
- 每一個候選框採用CNN提取特徵向量
- 利用線性SVM對特徵向量進行分類
2.1 - 各向異性&各向同性縮放
由於selective search生成出的候選框大小規模都不一樣,而傳統CNN要求輸入的影象尺度必須是固定的,因此需要採用各向異性或者各向同性縮放的方法來對影象大小進行縮放。
2.1.1 - 各向異性縮放
不管圖片的長寬比例,直接縮放成固定的$227 \times 227$,如下圖(D)所示,優點是簡單,缺點是很容易造成目標扭曲變形等等。
2.1.2 - 各向同性縮放
- 方法一:直接在原始圖片中,把bounding box的邊界擴充套件成需要的固定尺度,然後再進行裁剪,如果已經延伸到原始圖片邊界外,採用bounding box中的畫素顏色均值進行填充,如下圖(B)所示
- 方法二:先把bounding box裁剪出來,然後用固定的背景顏色填充成所需的固定大小尺度(背景顏色也是採用bounding box的畫素顏色均值),如下圖(C)所示

論文中還提出了padding處理,上圖1、3行採用了padding=0,而2、4行採用了padding=16。經過試驗,作者發現採用各向異性縮放、padding=16的精度最高(這裡作者提出,影象扭曲的影響並沒有我們直觀感覺到的那麼大)。
2.2 - 正負樣本標註
上述產生的bounding box不可能剛剛好和人工標註的box完全匹配,因此我們需要對這些bounding box打上標籤,方便下一步CNN訓練使用。標註根據如下規則:
- 如果該bounding box與真實box的IOU大於0.5,則為正樣本,打上對應物體類別的標籤
- 否則為負樣本,將其歸為背景的類別
3 - 訓練
3.1 - CNN網路架構
提取特徵的CNN結構有兩個可選方案:Alexnet和VGG 16,經過測試Alexnet精度為58.5%,VGG 16精度為66%,但VGG 16的計算量大約是Alexnet的7倍。
3.2 - CNN有監督預訓練
目標檢測的資料集較小,採用隨機初始化引數則目前的訓練量遠遠不夠,因此先用ImageNet的分類資料集訓練CNN,而後將模型結構微調成適應檢測任務,直接採用分類模型引數,再做fine-tuning訓練。(採用隨機梯度下降優化方法,學習率大小為0.001)。
3.3 - fine-tuning階段
採用selective search生成的候選框,將其處理到指定大小尺度,對上面有監督預訓練後的CNN模型進行fine-tuning訓練。假設要檢測的物體類別有N類,則需要將預訓練的CNN模型最後一層替換成N+1個輸出的神經元(額外加1表示背景),這一層採用隨機初始化方法,其他網路層引數不變,再採用SGD(隨機梯度下降)訓練就可以了。(注:SGD學習率選擇為0.001,batch size為128,其中32個正樣本+86個負樣本)。
3.3 - 關於CNN的思考
疑問1:如果直接採用Alexnet作為特徵提取器而不做fine-tuning訓練是否可以?
論文中也對該想法進行了實驗,實驗結果表明直接採用網路中$p_5$的輸出作為特徵提取結果的精度跟$f_6$和$f_7$差不多,反而$f_6$提取到的特徵還比$f_7$的精度略高。可以總結出一個規則,如果不針對特定任務進行fine-tuning,而是把CNN作為特徵提取器,卷積層所學到的特徵其實是基礎的泛化的特徵,而後續的全連線層更多的學習到是特定任務的表示。
疑問2:CNN的輸出可以通過一個softmax層直接達成分類目的,為何還需要通過SVM進行分類?
通過上述正負樣本標註過程可以知道,訓練集中正樣本遠比負樣本少,並且只要IOU大於0.5便標註為正樣本(條件寬鬆),而CNN的效果跟訓練資料的大小有一定關係,所以少量的標註資料對於CNN來說還是不夠,而SVM更適用於少量樣本,因此SVM的效果會比softmax好,所以作者採用了額外的SVM分類器。(注:通過實驗發現,當IOU的閾值採用0.3的時候效果最好,採用0.0的時候下降了4個百分點,採用0.5的時候下降了5個百分點)