
[論文理解]Region-Based Convolutional Networks for Accurate Object Detection and Segmentation
Region-Based Convolutional Networks for Accurate Object Detection and Segmentation
概括
這是一篇2016年的目標檢測的文章,也是一篇比較經典的目標檢測的文章。作者介紹到,現在表現最好的方法非常的複雜,而本文的方法,簡單又容易理解,並且不需要大量的訓練集。
文章的大致脈絡如圖。
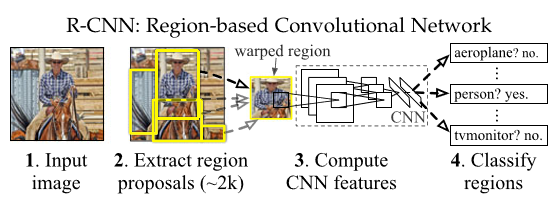
產生region proposal
文章提到了滑窗的方法,由於滑窗的方法缺點非常明顯,就是每次只能檢測一個aspect ratio,所以確定object的框的大小很難確定,而且很笨重。而文章中採用的是selective search演算法得到region proposal,這個演算法是作者對比了多種方法後採取的方法。在實驗的時候,作者描述可以用selective search得到大概2000個region proposal。
得到CNN features
這裡作者是採用了訓練好的網路來提取特徵。首先在大訓練集上使用使用CNN訓練一個用於識別的網路,然後拿這個網路進行微調。具體的做法是,將softmax之前的fc層的輸出變為要識別的類別數+1,1是背景,然後再在具體的訓練集上進行小資料訓練。最終要取的feature是每個region都丟進CNN,然後取softmax之前的fc層是輸出值作為feature,這裡要注意,輸入網路的region的長寬都必須warp到CNN需要的長寬才能進行輸入。
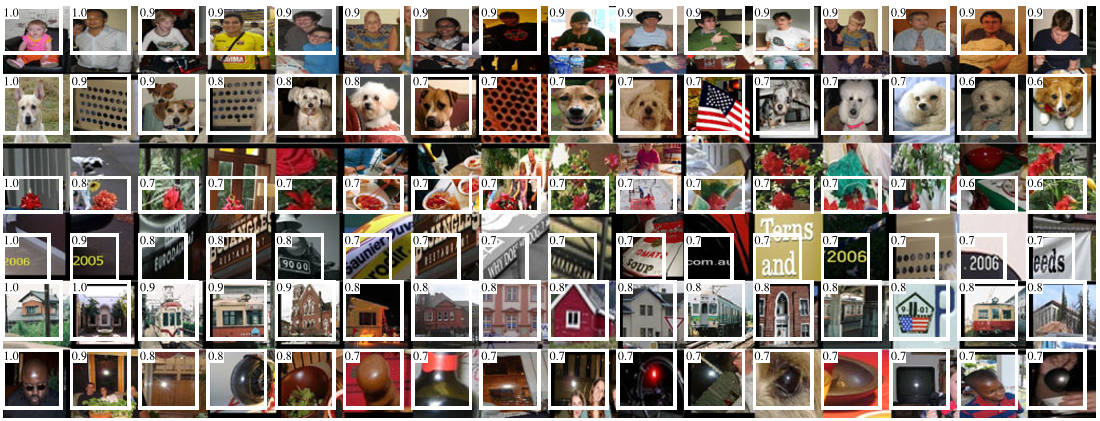
此外,作者還提到了 Visualizing Learned Features ,作者直接將某一層的特徵視作分類,直接執行activation,得到activation之後的值按照從大到小排序,選取最大的幾個,進行非最大抑制,顯示得分最高的幾個。作者稱為“speak for itself”,這種方法可以直接視覺化CNN中經過學習之後的內容。如作者可視化了TorontoNet的pool5 層,pool5的feature map是6✖6✖256=9216維的,而每個pool5層又代表原輸入影象227✖227pixel的195✖195 pixel的部分,因此可以用來檢查某一層是否學的正確。
下圖是CNN對COV2007訓練集進行微調後訓練的pool5的啟用後排名前16 的影象。這些層的選擇是為了展示網路學習代表性的樣本。
丟進SVM訓練
從上面我們得到了CNN提取的feature,我們要做的是把這些feature丟進SVM進行訓練,這裡有多少個類就有多少個分類器負責某一類別的分類。
Bounding-Box Regression
上面訓練完了,我們就知道那個region裡的東西屬於哪個類別,但是我們還需要用Bounding Box把這個類別的object給框起來,所以就需要Bounding-Box Regression.文章採用的是簡單的線性迴歸模型來預測Bounding Box.抱歉公式不會打。只能貼上論文原文。簡單來說就是給定x,y,w,h預測對應的ground truth的x,y,t,h。然後就得到了bounding box。


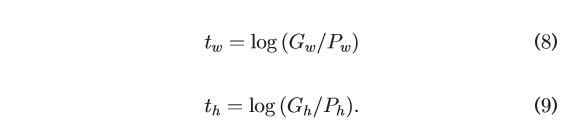
連結:論文原文