
sql優化(三)--索引設計的原則
阿新 • • 發佈:2018-11-03
---
title: 不懂SQL優化?那你就OUT了(三)
-- 索引(二)
-- 索引的設計原則
date: 2018-11-03
categories: 資料庫優化
---


上一遍部落格我們主要介紹了什麼是索引,為什麼要使用索引,索引的好處和如何建立索引,這一篇我們將討論一下應該如何合理的建立索引。
增加索引有如此多的優點,為什麼不對錶中的每一個列建立一個索引呢?這種想法固然有其合理性,然而也有其片面性。
雖然,索引有許多優點, 但是,為表中的每一個列都增加索引,是非常不明智的。
這是因為,增加索引也有許多不利的方面。
索引有哪些“副作用”?
1. 建立索引和維護索引要耗費時間,這種時間隨著資料量的增加而增加。
2. 索引需要佔物理空間,除了資料表佔資料空間之外,每一個索引還要佔一定的物理空間,
3. 當對錶中的資料進行增加、刪除和修改的時候,索引也要動態的維護,這樣就降低了資料的維護速度。
應該在這些列上建立索引
1.在經常需要搜尋的列上,可以加快搜索的速度;
2.在作為主鍵的列上.
3.在經常用在連線的列上,這些列主要是一些外來鍵,可以加快連線的速度;
4.在經常需要根據範圍進行搜尋的列上建立索引,因為索引已經排序,其指定的範圍是連續的;
5.在經常需要order by,group by,distinct 列上建立索引,這樣查詢可以利用索引的排序,加快排序查詢時間; 6.在經常使用在WHERE子句中的列上面建立索引,加快條件的判斷速度。 不應該建立索引的列具有下列特點
1.對於那些在查詢中很少使用的列不應該建立索引。
原因:
既然這些列很少使用到,因此有索引或無索引,並不能提高查詢速度。相反,由於增加了索引,反而降低了系統的維護速度和增大了空間需求。
2. 對於那些只有很少資料值的列也不應該增加索引
原因:
由於這些列的取值很少, 例如:學生表的性別列,在查詢的結果中,結果集的資料行佔了表中資料行的很大比例,即需要在表中搜索的資料行的比例很大。增加索引,並不能明顯加快檢索速度。
3.對於那些定義為text, blob資料型別的列不應該增加索引。
原因:
這些列的資料量要麼相當大,要麼取值很少。
4.當修改效能遠遠大於檢索效能時,不應該建立索引。
原因:
修改效能和檢索效能是互相矛盾的。當增加索引時,會提高檢索效能,但是會降低修改效能。當減少索引時,會提高修改效能,降低檢索效能。因此當修改效能遠遠大於檢索效能時不應該建立索引。
5.單表資料太少,不適合建索引 案列(程式碼)
示例程式碼:(無索引的表)
CREATE TABLE t_customer_one(
customerId INT PRIMARY KEY AUTO_INCREMENT, -- 編號 customerName VARCHAR(20), -- 姓名 customerAge INT, -- 年齡 customerGender CHAR(3), -- 性別 customerPhone VARCHAR(29), -- 聯絡方式 customerEmail VARCHAR(30), -- 電子郵件 province VARCHAR(20), -- 所在省份 city VARCHAR(30), -- 所在城市 address VARCHAR(200) -- 詳細地址 ); 新增的資料:
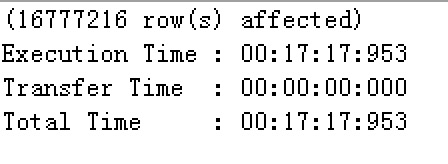
共 16777216 條資料
INSERT INTO t_customer_one(customerName,customerAge,customerGender,customerPhone,customerEmail,province,city,address) VALUES('張三',18,'女','15767678798','[email protected]','四川','成都','武侯區科華北路88號'); INSERT INTO t_customer_one(customerName,customerAge,customerGender,customerPhone,customerEmail,province,city,address) VALUES('李四',24,'男','18767689798','[email protected]','廣東','廣州','白雲區天明路188號'); INSERT INTO t_customer_one(customerName,customerAge,customerGender,customerPhone,customerEmail,province,city,address) VALUES('王五',23,'女','17167675698','[email protected]' , '四川','成都','武侯區科華北路85號'); INSERT INTO t_customer_one(customerName,customerAge,customerGender,customerPhone,customerEmail,province,city,address) VALUES('趙六',26,'男','13767659697','[email protected]', '廣東','廣州','白雲區天明路180號'); INSERT INTO t_customer_one(customerName,customerAge,customerGender,customerPhone,customerEmail,province,city,address) SELECT customerName,customerAge,customerGender,customerPhone,customerEmail,province,city,address FROM t_customer_one; 新增資料需要時間: 大約 8 分鐘左右
示例程式碼:(帶索引的表)
CREATE TABLE t_customer_two(
customerId INT PRIMARY KEY AUTO_INCREMENT, -- 編號
customerName VARCHAR(20), -- 姓名
customerAge INT, -- 年齡
customerGender CHAR(3), -- 性別 customerPhone VARCHAR(29), -- 聯絡方式 customerEmail VARCHAR(30), -- 電子郵件 province VARCHAR(20), -- 所在省份 city VARCHAR(30), -- 所在城市 address VARCHAR(200) -- 詳細地址 ) 為表2新增索引
-- 單列索引
ALTER TABLE t_customer_two ADD INDEX idx_name(customerName); ALTER TABLE t_customer_two ADD INDEX idx_age (customerAge); ALTER TABLE t_customer_two ADD INDEX idx_phone(customerPhone); -- 多列索引(聯合索引) CREATE INDEX idx_province_city_address ON t_customer_two(province,city,address); 新增資料(從表1複製資料):
INSERT INTO t_customer_two(customerName,customerAge,customerGender,customerPhone,customerEmail,province,city,address)
SELECT customerName,customerAge,customerGender,customerPhone,customerEmail,province,city,address FROM t_customer_one; 新增資料需要時間:大約 18分鐘

測試
單列索引
案例
*** 查詢年齡在18歲--23歲的客戶的總人數**
無索引:
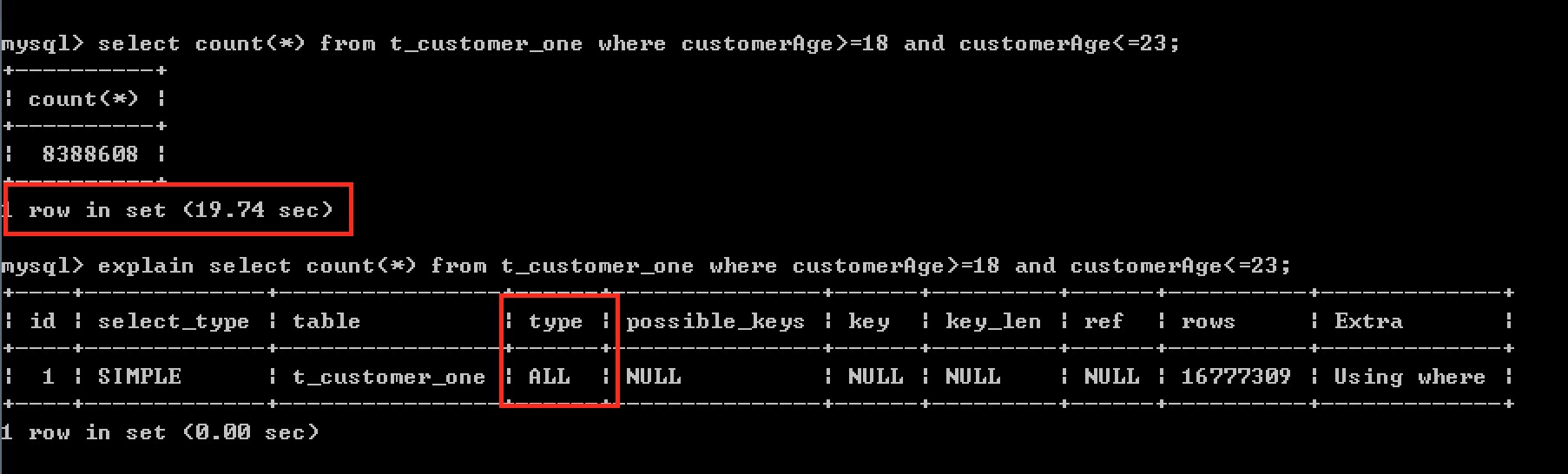

查詢所用時間:19.75 秒
檢視之執行計劃: type=all 進行全表掃描
有索引:
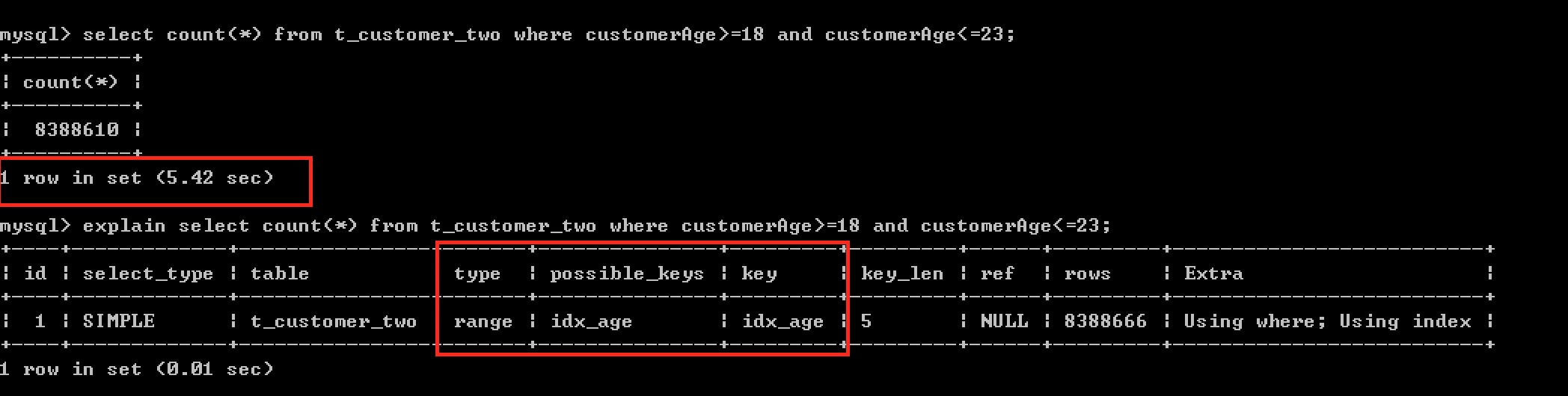

查詢所用時間:5.42 秒
檢視之執行計劃: type=range,並使用了索引idx_age.
說明:應該在在經常需要根據範圍進行搜尋的列上建立索引
多列索引
如果有一個頁面中有一個搜尋部分 會根據輸入的 省份,城市,詳細地址來搜尋客戶的詳細記錄
那麼這個時候到底給那一個列加索引比較好?
此時就可以使用多列索引
如果使用多列索引,where條件中欄位的順序非常重要,需要滿足最左字首列
最左字首: 查詢條件中的所有欄位需要從最左邊列起按順序出現在多列索引中,
查詢條件的欄位數要 小於,等於多列索引的欄位數,
中間欄位不能存在範圍查詢的欄位 (如<,like等),這樣的sql語句可以使用該多列索引。
什麼意思?
例如:
select * from t_customer_two Where province=‘xxx’ and city=‘xxxxx’ and address=‘XXX’ -- (多列索引有效) select * from t_customer_two Where province=‘xxx’ and city=‘XXX’ -- (多列索引有效) select * from t_customer_two Where province=‘xxx’ -- (多列索引有效) select * from t_customer_two Where city=‘xxxxx’ and address=‘XXX’ -- (多列索引無效,無最左邊的province列) select * from t_customer_two Where and address=‘XXX’ -- (多列索引無效) 使用了索引:
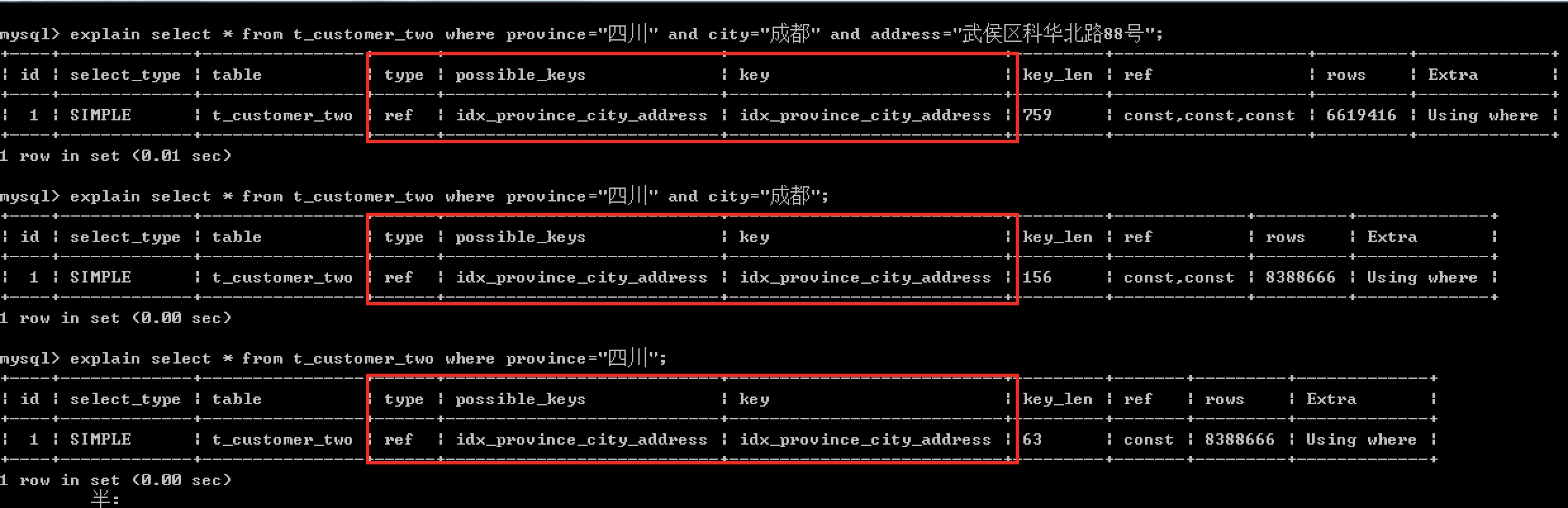

未使用索引:


mysql多列索引適合的場景
1. 匹配全值,對索引中的所有列都指定具體的值(例如: province=‘xxx’ and city=‘xxx’ and address=‘xxx’)
2. 匹配最左字首(例如: province=‘xxx’, 使用索引中的第一列)
3. 匹配部分最左字首(例如: province=‘xxx’ and city=‘xxx’) 4. 匹配第一列範圍查詢(可用like a%,但不能使用 like %b 或則 like %b%) 在以下幾種情況下,mysql在查詢中即使有索引也不會去使用
1. 在多列索引,查詢條件中用的不是最左邊的列,那麼此時是不會使用索引。
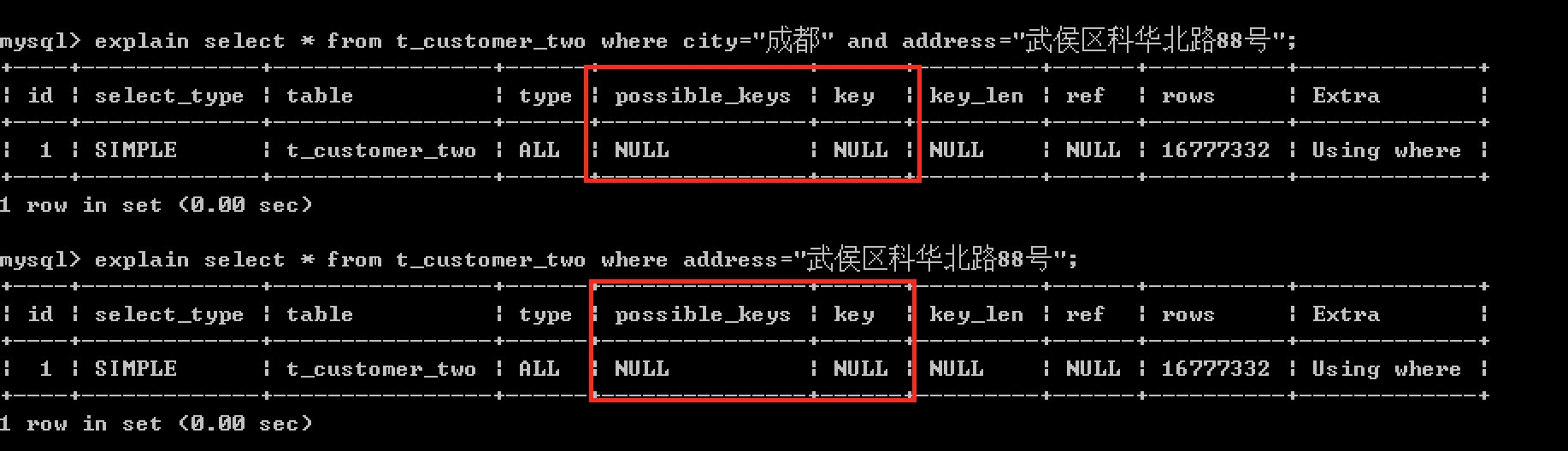
2. like查詢時 % 出現在第一位也不會使用索引。


3. 條件中有 or 也不會使用索引。


4. 如果 mysql 估計使用全表掃描比使用索引快,它也不會使用索引。