
Python庫一Numpy庫學習總結
阿新 • • 發佈:2018-11-03
Python庫一Numpy庫學習總結
- N維陣列ndarray
- Numpy資料儲存
- 隨機函式、統計函式、梯度函式
N維陣列物件ndarray
基本構成
ndarray是一個多維陣列物件,由兩部分構成:
- 實際的資料;
- 描述這些資料的元資料(資料維度、資料型別等);
ndarray陣列一般要求所有元素型別相同(同質),陣列下標從0開始。
注意:
- 在NumPy中維度(dimensions)叫做軸(axes),軸的個數叫做秩(rank);
- ndarray中的每個元素在記憶體中使用相同大小的塊。 ndarray中的每個元素是資料型別物件的物件(稱為 dtype);
- 從ndarray物件提取的任何元素(通過切片)由一個數組標量型別的 Python 物件表示;
- ndarray大部分建立的陣列預設都是浮點數(出了arange等函式),為什麼?因為大部分科學計算都是浮點數,很少只有整數的資料;
下圖顯示了ndarray,資料型別物件(dtype)和陣列標量型別之間的關係。
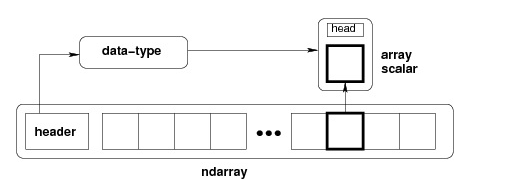
ndarray物件的屬性

程式碼演示:
import numpy as np
a = np.array([[0, 1, 2, 3, 4],
[9, 8, 7, 6, 5]])
print(a.ndim)
print(a.shape) 輸出:
2
(2, 5)
10
int64
8
ndarray的元素型別
- bool、
- intc、intp、int8、int16、int32、int64、
- uint8、uint16、uint32、uint64、
- float16、float32、float64
- complex64、complex128
| 資料型別 | 描述 |
|---|---|
| bool | 儲存為一個位元組的布林值(真或假) |
| int | 預設整數,相當於 C 的long,通常為int32或int64 |
| intc | 相當於 C 的int,通常為int32或int64 |
| intp | 用於索引的整數,與C語言中size_t一致,int32或int64 |
| int8 | 位元組長度的整數,取值:[‐128, 127] |
| int16 | 16位長度的整數,取值:[‐32768, 32767] |
| int32 | 32位長度的整數,取值:[‐231, 231‐1] |
| int64 | 64位長度的整數,取值:[‐263, 263‐1] |
| uint8 | 8位無符號整數,取值:[0, 255] |
| uint16 | 16位無符號整數,取值:[0, 65535] |
| uint32 | 32位無符號整數,取值:[0, 232‐1] |
| uint64 | 64位無符號整數,取值:[0, 264‐1] |
| float16 | 16位半精度浮點數:1位符號位,5位指數,10位尾數 |
| float32 | 32位半精度浮點數:1位符號位,8位指數,23位尾數 |
| float64 | 64位半精度浮點數:1位符號位,11位指數,52位尾數 |
| complex64 | 複數型別,實部和虛部都是32位浮點數 |
| complex | 複數型別,實部和虛部都是64位浮點數 |
ndarray也可以有非同質的物件
import numpy as np
# 非同質的 ndarray物件,無法有效發揮NumPy優勢,儘量避免使用
a = np.array([[0, 1, 2, 3, 4],
[9, 8, 7, 6]]) # 不是一個矩陣
print(a.ndim)
print(a.shape)
print(a.size) # 2
print(a.dtype) # object 非同質ndarray元素為物件型別
print(a.itemsize) # 每個元素的大小(位元組為單位)
輸出:
1
(2,)
2
object
8
建立ndarray陣列
建立的方式:
- 從Python中的列表、元組等型別建立ndarray陣列;
- 使用NumPy中函式建立ndarray陣列,如:arange, ones, zeros等;
- 從位元組流(raw bytes)中建立ndarray陣列;
- 從檔案中讀取特定格式,建立ndarray陣列;
下面看前兩種常見的建立方式:
① 從Python中的列表、元組等型別建立ndarray陣列:
基本格式如下:
x = np.array(list/tuple)
x = np.array(list/tuple, dtype=np.float32)
注意: 當np.array()不指定dtype時,NumPy將根據資料情況關聯一個dtype型別;
import numpy as np
# 使用列表建立ndarray物件
x = np.array([0, 1, 2, 3])
print(x)
# 使用元組建立ndarray物件
x = np.array((3, 2, 1, 0))
print(x)
# 使用列表和元組混合建立ndarray物件 --> 包含的個數相同即可
x = np.array([[1, 2], [3, 4], (0.1, 0.2)]) # 二維的
print(x)
輸出:
[0 1 2 3]
[3 2 1 0]
[[1. 2. ]
[3. 4. ]
[0.1 0.2]]
np.array函式的完整引數如下:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
| 引數 | 描述 |
|---|---|
| object | 任何暴露陣列介面方法的物件都會返回一個數組或任何(巢狀)序列(元組、列表等) |
| dtype | 陣列的所需資料型別,可選。 |
| copy | 可選,預設為true,物件是否被複制。 |
| order | C(按行)、F(按列)或A(任意,預設)。 |
| subok | 預設情況下,返回的陣列被強制為基類陣列。 如果為true,則返回子類。 |
| ndmin | 指定返回陣列的最小維數。 |
② 使用NumPy中函式建立ndarray陣列,如:arange, ones, zeros等

測試:
import numpy as np
# 使用arange來建立(類似python3中的range)
x = np.arange(10)
print(x)
print("*" * 20)
# 使用ones來建立
x = np.ones((3, 4))
print(x)
print("*" * 20)
# 三維的 -- ones的高階用法
x = np.ones((2, 3, 4))
print(x)
print("*" * 20)
# 根據zeros來建立
x = np.zeros((2, 3), dtype=np.int32)
print(x)
print("*" * 20)
# 根據full來建立
x = np.full((2, 3), 6)
print(x)
print("*" * 20)
# 根據eye來建立 建立一個正方形 對角線為1 其餘為0
x = np.eye(3)
print(x)
print("*" * 20)
輸出:
[0 1 2 3 4 5 6 7 8 9]
********************
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
********************
[[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]]
********************
[[0 0 0]
[0 0 0]]
********************
[[6 6 6]
[6 6 6]]
********************
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
********************
其他函式:

測試:
import numpy as np
a = np.linspace(1, 10, 4) # 在[1,10]中等間距的選4個數
print(a)
b = np.linspace(1, 10, 4, endpoint=False) # [1,10)之間
print(b)
c = np.concatenate((a, b)) # 將a,b合併
print(c)
輸出:
[ 1. 4. 7. 10.]
[1. 3.25 5.5 7.75]
[ 1. 4. 7. 10. 1. 3.25 5.5 7.75]
ndarray陣列的變化
兩種變化:
- 維度變化;

- 元素型別變化 : astype函式;
①維度變化: reshape和resize以及flatten的使用:
import numpy as np
a = np.ones((2, 3, 4), dtype=np.int32)
print(a)
print("-------使用reshape生成b------")
# reshape 不改變原來的陣列 建立一個新的ndarray
b = a.reshape((2, 12)) # 將[2,3,4] 變成[2,12] 注意都是24個元素
print(b)
print("--------原來的a沒有變化------")
# 輸出原來的
print(a)
print("--------使用resize改變a-------")
# resize改變原來的 ndarray
a.resize((2, 12))
print(a)
print("--------使用flatten對a降維生成一維c陣列------")
c = a.flatten()
print(c)
輸出:
[[[1 1 1 1]
[1 1 1 1]
[1 1 1 1]]
[[1 1 1 1]
[1 1 1 1]
[1 1 1 1]]]
-------使用reshape生成b------
[[1 1 1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1 1 1]]
--------原來的a沒有變化------
[[[1 1 1 1]
[1 1 1 1]
[1 1 1 1]]
[[1 1 1 1]
[1 1 1 1]
[1 1 1 1]]]
--------使用resize改變a-------
[[1 1 1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1 1 1]]
--------使用flatten對a降維生成一維c陣列------
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
②元素型別變化: astype函式,以及ndarray轉換成列表的tolist()方法:
import numpy as np
a = np.ones((2, 3), dtype=np.int)
print(a)
print("*" * 20)
# 注意astype生成的是一個拷貝的型別 沒有修改原來的陣列,即使新的型別和原來的型別一致
b = a.astype(np.float)
print(b)
print("-------使用tolist()方法從ndarray中生成列表list-------")
print(b.tolist()) # 注意生成的列表也是二維的
輸出:
[[1 1 1]
[1 1 1]]
********************
[[1. 1. 1.]
[1. 1. 1.]]
-------使用tolist()方法從ndarray中生成列表list-------
[[1.0, 1.0, 1.0], [1.0, 1.0, 1.0]]
ndarray陣列的運算
注意: 陣列與標量之間的運算作用於陣列的每一個元素。
常用的一元函式:

常用的二元函式:

例子:
import numpy as np
a = np.arange(12).reshape((2, 6))
print(a)
print("*" * 20)
b = np.square(a) # 平方
print(b)
print("*" * 20)
c = np.sqrt(a) # 平方根
print(c)
print("*" * 20)
print(np.maximum(a, b)) # 元素級的最大值 輸出a,b中較大的
print("*" * 20)
print(b > a) # 各個位置的比較
輸出:
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]]
********************
[[ 0 1 4 9 16 25]
[ 36 49 64 81 100 121]]
********************
[[0. 1. 1.41421356 1.73205081 2. 2.23606798]
[2.44948974 2.64575131 2.82842712 3. 3.16227766 3.31662479]]
********************
[[ 0 1 4 9 16 25]
[ 36 49 64 81 100 121]]
********************
[[False False True True True True]
[ True True True True True True]]
Numpy資料儲存
一維或二維資料儲存
儲存到csv檔案:
np.savetxt(fname, array, fmt='%.18e', delimiter=None)
相關引數使用說明:
- fname : 檔案、字串或產生器,可以是.gz或.bz2的壓縮檔案;
- array : 存入檔案的陣列;
- fmt : 寫入檔案的格式,例如:%d %.2f %.18e;
- delimiter : 分割字串,預設是任何空格;
例子:
import numpy as np
a = np.arange(80).reshape((4, 20))
np.savetxt("a.csv", a, fmt="%d", delimiter=",")
b = np.arange(80).reshape((4, 20))
np.savetxt("b.csv", b, fmt="%.1f", delimiter=",")
在同目錄下生成的a.csv和b.csv檔案內容如下:
a.csv:
0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19