
caffe原始碼 池化層
1、標題圖示池化層(前向傳播)
池化層其實和卷積層有點相似,有個類似卷積核的視窗按照固定的步長在移動,每個視窗做一定的操作,按照這個操作的型別可以分為兩種池化層:
輸入引數如下:
輸入: 1 * 3 * 4 * 4
池化核: 2 * 2
pad: 0
步長:2
輸出引數如下:
輸出:1 * 3 * 2 * 2
1.1、MAX (max pooling)在視窗中取最大值當做結果

1.2、AVG (average pooling)在視窗中取平均值當做結果

2、 池化層的反向傳播
按照前向傳播的分類,反向傳播也需要分成兩類
2.1、MAX (max pooling)
* 如果只看輸出矩陣中的一個點y,則有 y = max( x1 , x2, x3, ... );
* 所以對x求導後有(可以理解成分段函式的求導)

* 程式碼實現:

可見上圖,這個xn如果影響多個y,則會疊加起來
2.2、 AVG (average pooling)
* 如果只看輸出矩陣中的一個點y,則有 y = ( x1 , x2, x3, ... ,xn )/n;
* 所以對x求導後有
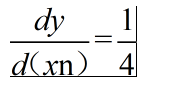
* 程式碼實現

可見上圖,這個xn如果影響多個y,則會疊加起來
相關推薦
caffe原始碼 池化層
1、標題圖示池化層(前向傳播) 池化層其實和卷積層有點相似,有個類似卷積核的視窗按照固定的步長在移動,每個視窗做一定的操作,按照這個操作的型別可以分為兩種池化層: 輸入引數如下: 輸入: 1 * 3 * 4 * 4 池化核: 2 * 2 pad: 0 步長:2 輸出引數如下
Caffe框架原始碼剖析(6)—池化層PoolingLayer
卷積層ConvolutionLayer正向傳導的目標層往往是池化層PoolingLayer。池化層通過降取樣來降低卷積層輸出的特徵向量,同時改善結果,不易出現過擬合。最常用的降取樣方法有均值取樣(取區域平均值作為降取樣值)、最大值取樣(取區域最大值作為降取樣值)和隨機
caffe源碼 池化層 反向傳播
C4D alt convert ec2 ted 操作 src 技術 space 圖示池化層(前向傳播) 池化層其實和卷積層有點相似,有個類似卷積核的窗口按照固定的步長在移動,每個窗口做一定的操作,按照這個操作的類型可以分為兩種池化層: 輸入參數如下: 輸入: 1 *
10、Caffe學習與應用 -訓練(卷積層引數、池化層引數、學習率、正則化)
10.2訓練 一、卷積層引數tricks 圖片輸入是2的冪次方,例如32、64、96、224等。 卷積核大小是3*3或者5*5。 輸入圖片上下左右需要用0來補充,即padding,且假如卷積核大小是5那麼padding就是2(圖片左右上下都補充2),卷積核大小是3pa
卷積層,池化層等,前向/反向傳播原理講解
簡單 代碼 構建 range expand 使用場景 神經網絡 右下角 body 今天閑來無事,考慮到以前都沒有好好研究過卷積層、池化層等等的前向/反向傳播的原理,所以今天就研究了一下,參考了一篇微信好文,講解如下: 參考鏈接:https://www.zybuluo.co
tensorflow中的卷積和池化層(一)
oat avg 滑動 shape 要求 網絡 vol 加速 ali 在官方tutorial的幫助下,我們已經使用了最簡單的CNN用於Mnist的問題,而其實在這個過程中,主要的問題在於如何設置CNN網絡,這和Caffe等框架的原理是一樣的,但是tf的設置似乎更加簡潔、方便,
理解CNN卷積層與池化層計算
CNN網絡 卷積層 池化層 深度學習 OpenCV 概述 深度學習中CNN網絡是核心,對CNN網絡來說卷積層與池化層的計算至關重要,不同的步長、填充方式、卷積核大小、池化層策略等都會對最終輸出模型與參數、計算復雜度產生重要影響,本文將從卷積層與池化層計算這些相關參數出發,演示一下不同步長、
全連接層(FC)與全局平均池化層(GAP)
出了 類別 節點 過擬合 技術 分類 思想 ID 連接 在卷積神經網絡的最後,往往會出現一兩層全連接層,全連接一般會把卷積輸出的二維特征圖轉化成一維的一個向量,全連接層的每一個節點都與上一層每個節點連接,是把前一層的輸出特征都綜合起來,所以該層的權值參數是最多的。例如在VG
TensorFlow 池化層
www tar float 深度 value pytho version str pan 在 TensorFlow 中使用池化層 在下面的練習中,你需要設定池化層的大小,strides,以及相應的 padding。你可以參考 tf.nn.max_pool()。Padding
【TensorFlow】池化層max_pool中兩種paddding操作
max_pool()中padding引數有兩種模式valid和same模式。 Tensorflow的padding和卷積層一樣也有padding操作,兩種不同的操作輸出的結果有區別: 函式原型max_pool(value, ksize, strides, padding
【深度學習】基於im2col的展開Python實現卷積層和池化層
一、回顧 上一篇 我們介紹了,卷積神經網的卷積計算和池化計算,計算過程中視窗一直在移動,那麼我們如何準確的取到視窗內的元素,並進行正確的計算呢? 另外,以上我們只考慮的單個輸入資料,如果是批量資料呢? 首先,我們先來看看批量資料,是如何計算的 二、批處理 在神經網路的
【深度學習】卷積神經網路的卷積層和池化層計算
一、簡介 \quad\quad 卷積神經網路(Convolutional neural network, CNN),
【讀書1】【2017】MATLAB與深度學習——池化層(1)
由於它是一個二維的運算操作,文字解釋可能會導致更多的混淆,因此讓我們來舉一個例子。 As it is a two-dimensional operation, andan explanation in text may lead to more confusion, let’s go t
《TensorFlow:實戰Google深度學習框架》——6.3 卷積神經網路常用結構(池化層)
池化層在兩個卷積層之間,可以有效的縮小矩陣的尺寸(也可以減小矩陣深度,但實踐中一般不會這樣使用),co。池從而減少最後全連線層中的引數。 池化層既可以加快計算速度也可以防止過度擬合問題的作用。 池化層也是通過一個類似過濾器結構完成的,計算方式有兩種: 最大池化層:採用最
池化層 pool
池化層 pool 池化層,可以降低資料體的空間尺寸,這樣的話就能減少網路中引數的數量,使得計算資源耗費變少,也能有效控制過擬合。 最常見的形式是池化層使用尺寸 2
cnn系列文章 --池化層和簡單卷積網路示例
出去吃了個飯,突然感覺好沒胃口,好落寞。。。。 哎,繼續吧 一句歌詞繼續中: 《霜雪千年》 苔綠青石板街 斑駁了流水般歲月 小酌三盞兩杯 理不清纏繞的情結 典型的卷積神經網路 convolution (Conv) 卷積
【深度學習筆記】關於卷積層、池化層、全連線層簡單的比較
卷積層 池化層 全連線層 功能 提取特徵 壓縮特徵圖,提取主要特徵 將學到的“分散式特徵表示”對映到樣本標記空間 操作 可看這個的動態圖,可惜是二維的。對於三維資料比如RGB影象(3通道),卷積核的深度必須
caffe原始碼解析:層(layer)的註冊與管理
caffe中所有的layer都是類的結構,它們的構造相關的函式都註冊在一個全域性變數g_registry_ 中。 首先這個變數的型別 CreatorRegistry是一個map定義, public: typedef shared_ptr<Layer<Dt
2個(隱藏層+池化層)+全連結層及儲存暫停後可繼續訓練,64個輸入,2個輸出
#!/usr/bin/env pythonimport tensorflow as tfinput_num = 64output_num = 2def create_file(path,output_num): #write = tf.python_io.TFRecordWriter('train.tf
對CNN中pooling層(池化層)的理解
自己在學習CNN過程中,查詢網上一些資料,對pooling層有了一些理解,記錄下來,也供大家參考: pooling層(池化層)的輸入一般來源於上一個卷積層,主要有以下幾個作用: 1.保留主要的特徵,同時減少下一層的引數和計算量,防止過擬合 2. 保持某種不變性,包括translation