
資料提取-Xpath
阿新 • • 發佈:2018-11-04
1. 介紹
之前BeautifulSoup的用法,這已經是很強大的庫了,不過還有一些比較流行的解析庫,例如lxml,使用的是Xpath語法,同樣是效率比較高的解析方法,如果對BeautifulSoup使用不太習慣,可以嘗試下Xpath
官網:http://lxml.de/index.html
w3c:http://www.w3school.com.cn/xpath/index.asp
2. 安裝
pip install lxml
3.Xpath的語法
3.1選取節點
3.1.1 常用的路徑表示式

3.1.2.萬用字元
XPath萬用字元可用來
選取位置的XML元素

3.1.3 選取若干路徑
通過在路徑表示式中使用“|”運算子,可以選取若干個路徑

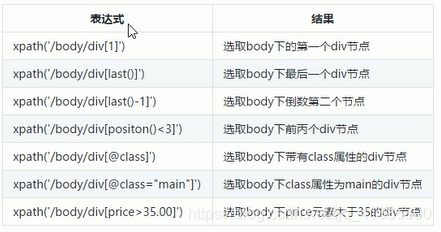
3.1.4 謂語
謂語被切在方括號內,用來查詢某個特定的節點或包含某個指定的值的節點
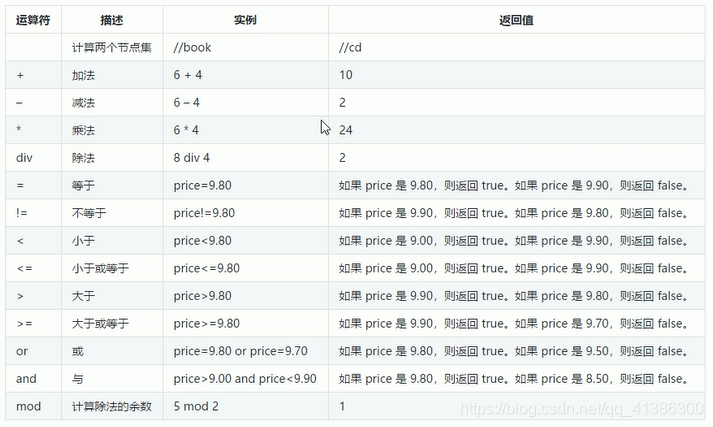
3.1.5 XPath運算子
3.2 使用
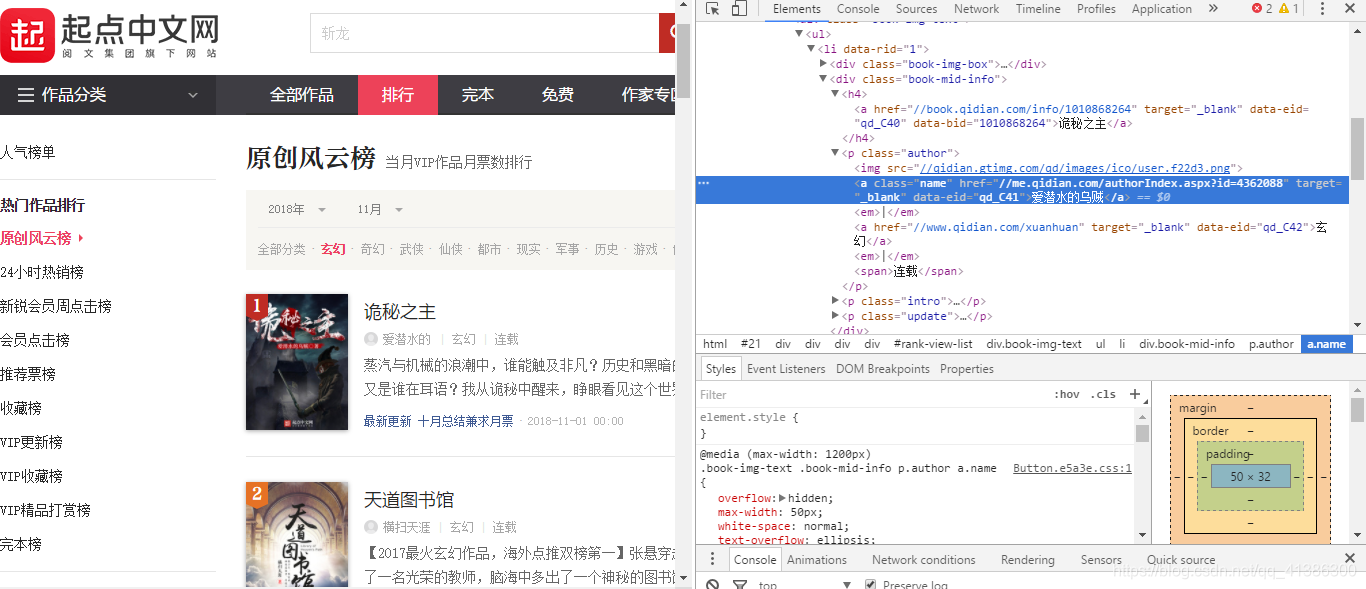
小例子:
爬取介面
程式碼:
from lxml import etree
from random import choice
import requests
user_agents=[
"User-Agent:Mozilla/5.0(Windows;U;WindowsNT6.1;en-us)AppleWebKit/534.50(KHTML,likeGecko)Version/5.1Safari/534.50"