
演算法(二)之排序
排序演算法很多,常用的排序演算法有:氣泡排序、插入排序、選擇排序、歸併排序、快速排序、計數排序、基數排序、桶排序。
接下來一一介紹幾種排序的時間複雜度及優缺點。
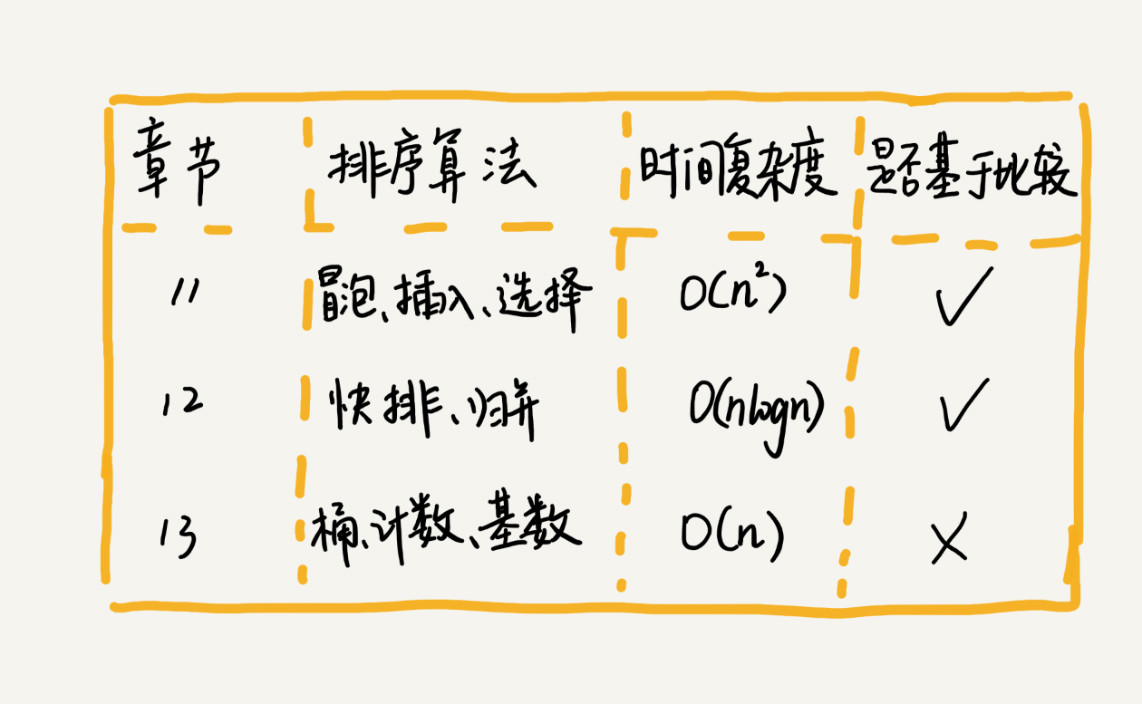
插入排序與氣泡排序的時間複雜度相同O(n^2),開發中我們更傾向插入排序,而不是氣泡排序
排序演算法執行效率:
1.最好、最壞、平均情況時間複雜度
- 時間複雜度的係數、常數 、低階
- 比較次數和交換(或移動)次數
排序演算法的記憶體消耗
排序演算法的穩定性
相關推薦
演算法(二)之排序
排序演算法很多,常用的排序演算法有:氣泡排序、插入排序、選擇排序、歸併排序、快速排序、計數排序、基數排序、桶排序。 接下來一一介紹幾種排序的時間複雜度及優缺點。 插入排序與氣泡排序的時間複雜度相同O(n^2),開發中我們更傾向插入排序,而不是氣泡排序 排序演算法執行效率: 1.最好、最壞、平均情況時間
js 中的 一些簡單演算法(二)之 雙層迴圈—氣泡排序
1、列印9*9乘法表 思路:腦補一下乘法表的格式,9*9就是有9列、9行組成。行和列都需要由迴圈控制。 document.write("<table border='1' cellspacing='0' cellpadding='0'>"); //最外面放一個
重學資料結構和演算法(二)之二叉樹、紅黑樹、遞迴樹、堆排序
[TOC] 最近學習了極客時間的《資料結構與演算法之美]》很有收穫,記錄總結一下。 歡迎學習老師的專欄:[資料結構與演算法之美](https://time.geekbang.org/column/intro/126) 程式碼地址:https://github.com/peiniwan/Arithmetic
從零開始學演算法(二)選擇排序
從零開始學演算法(二)選擇排序 選擇排序 演算法介紹 演算法原理 演算法簡單記憶說明 演算法複雜度和穩定性 程式碼實現 選擇排序 程式碼是Javascript語言寫的(幾乎是虛擬碼) 演算
java排序演算法(二)------插入排序
插入排序 直接插入排序基本思想: 每一步將一個待排序的記錄,插入到前面已經排好序的有序序列中去,直到插完所有元素為止。 public static void sort(int[] arr) { int i; int t; for (int j
java排序演算法(二)----選擇排序
選擇排序(Selection Sort) 選擇排序(Selection-sort)是一種簡單直觀的排序演算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然後,再從
java 實現 常見排序演算法(二) 插入排序
大家好,我是烤鴨: 今天分享一下基礎排序演算法之直接插入排序。 1. 直接插入排序: 原理:假設前面的數為有序數列,然後有序數列與無序數列的每個數比較,我們可
經典排序演算法(二)--桶排序Bucket Sort
補充說明三點 1,桶排序是穩定的 2,桶排序是常見排序裡最快的一種,比快排還要快…大多數情況下 3,桶排序非常快,但是同時也非常耗空間,基本上是最耗空間的一種排序演算法 我自己的理解哈,可能與網上說的有一些出入,大體都是同樣的原理 無序陣列有個要求,就是成員隸屬於固定(有限的)的區間,如範圍為[0-
排序演算法(二)——氣泡排序
氣泡排序演算法的運作如下: 比較相鄰的元素。如果第一個比第二個大,就交換他們兩個。 對每一對相鄰元素作同樣的工作,從開始第一對到結尾的最後一對。這步做完後,最後的元素會是最大的數。 針對所有的元素重複以上的步驟,除了最後一個。 持續每次對越來越少的元素重複上面的步驟,直到
排序演算法(二)雞尾酒排序演算法(雙向冒泡)
1、我們知道,在氣泡排序演算法中,每一次冒泡的過程就是一次求最值的過程,也就是說一次冒泡只能確定一個數的位置。所以氣泡排序需要冒泡n-1次(n為待排序資料的個數),現在我們可以這樣想:如果一次冒泡的
排序演算法(二)——選擇排序及改進
選擇排序 基本思想 氣泡排序中有一個缺點,比如,我們比較第一個數a1與第二個數a2的時候,只要a1比a2大就會交換位置,但是我們並不能確定a2是最小的元素,假如後面還有比它更小的,該元素還會與a2
排序演算法之(二)選擇排序
原理: 每一次從待排序的資料元素中選出最小(或最大)的一個元素,存放在序列的起始位置,然後,再從剩餘未排序元素中繼續尋找最小(大)元素,然後放到已排序序列的末尾。以此類推,直到全部待排序的資料元素排完。 選擇排序是不穩定的排序方法。 思路: n個數進行n-1次排序 每一次排
演算法學習之排序演算法(二)(直接插入排序法)
1、插入法排序原理 直接插入排序(Insertion Sort)的基本思想是:每次將一個待排序的記錄,按其關鍵字大小插入到前面已經排好序的子序列中的適當位置,直到全部記錄插入完成為止。 設陣列為a[0…n-1]。 1. 初始時,a[0]自成1
Logistic迴歸之梯度上升優化演算法(二)
Logistic迴歸之梯度上升優化演算法(二) 有了上一篇的知識儲備,這一篇部落格我們就開始Python3實戰 1、資料準備 資料集:資料集下載 資料集內容比較簡單,我們可以簡單理解為第一列X,第二列Y,第三列是分類標籤。根據標籤的不同,對這些資料點進行分類。
計算機網路實驗(二)之Wireshark抓包分析獲取URL列表(去重、排序、統計)
實驗要求 本試驗要求基於第一次實驗中訪問某官網主頁時所抓取到的資料包,用Python 3語言、Jupyter Notebook和Pyshark編寫程式碼進行協議分析所需的開發環境,編寫程式碼,以輸出的方式列出首頁以及其所包含的所有資源(至少包含如下型別
資料結構與演算法(二)-線性表之單鏈表順序儲存和鏈式儲存
前言:前面已經介紹過資料結構和演算法的基本概念,下面就開始總結一下資料結構中邏輯結構下的分支——線性結構線性表 一、簡介 1、線性表定義 線性表(List):由零個或多個數據元素組成的有限序列; 這裡有需要注意的幾個關鍵地方: 1.首先他是一個序列,也就是說元素之間是有個先來後到的。
一些常見的排序演算法(二)
一、堆排序 如果還不瞭解滿二叉樹、完全二叉樹和最大堆(或大頂堆)的話,可以先了解一下。因為大頂堆要求根節點的元素大於其孩子,這樣得到大頂堆的堆頂的元素肯定是 序列中的最大值。清楚這些,就很容易理解堆排序了:先構造大頂堆,將大頂堆中堆頂元素與序列中末尾元素交換。這樣序列尾部的發生交換的元素是排列過的,剩下的
演算法(二):氣泡排序
氣泡排序(Bubble Sort),是一種電腦科學領域的較簡單的排序演算法。 它重複的走訪過要排列的數列,一次比較兩個元素,如果他們的順序錯誤就把他們交換過來,走訪數列的工作是重複的進行直到沒有有再需要交換,也就是說該數列已經排序完成。 這個演算法的名字由來是因為越大的元素會
排序演算法(二)
4、希爾排序 原理:希爾排序是直接插入排序的增強,希爾排序是將整個序列分成若干個組,然後進行分組插入排序,分組的增量gap從大到小,最終必須為1,當增量為1時,也就是插入排序(gap一般是gap = gap/2不斷縮小到1或者gap = (gap/3+1),逐步
我的軟考之路(六)——資料結構與演算法(4)之八大排序
排序是程式設計的基礎,在程式中會經常使用,好的排序方法可以幫助你提高程式執行的效率,所以學好排序,打好基礎,對於程式的優化會手到擒來。無論你的技術多麼強,如果沒有基礎也強不到哪去。