
JavaSE基礎之IO流
Java中把輸入/輸出(input/output)操作稱為流(Stream)。
流:即為起點到接收點有序的資料序列。
流的分類:
1.按照流的方向分為:
輸入流:只讀,只會從流中讀取資料;
輸出流:只寫,只會向流中寫入資料;
2.按照處理的資料分:
位元組流(InputStream/OutputStream):讀或寫的時候以位元組為單位;
字元流(Reader/Writer):讀或寫的時候以字元為單位;
一般情況下(排除特殊情況),一個漢字佔一個字元,一個字元佔兩個位元組,如果讀或寫的時候只讀或寫一個位元組的話,那麼就會出現亂碼。
3.按照功能分為:
低階流:直接從資料的源頭讀取資料或者直接把資料寫到目標位置的流,稱為低階流,也稱為節點流;
高階流:對一個已經存在的流的連線和封裝,稱為高階流,也稱為處理流;
先從位元組流中的FileInputStream和FileOutputStream說起:以下是兩者的模型


程式碼如下:
package com.Jevin.io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class ByteStreamTest {
public static void main(String[] args) {
//readFile1();
//readFile2();
//writeFile1();
writeFile2();
}
/**
* 用FileInputStream讀取檔案的內容,一個一個位元組的讀取(出現中文亂碼問題)
*/
public static void readFile1() {
FileInputStream fin = null;
try {
//檔案的完整路徑有三部分組成:路徑名稱+分隔符+檔名稱;
//如果指定檔案不存在,或者他是一個目錄,而不是一個常規檔案,抑或因為其他原因無法開啟進行讀取,則丟擲FileNotFoundException;
//注意:FileInputStream只能讀取並顯示純文字檔案的內容(也就是能用記事本開啟的檔案)
fin = new FileInputStream("d:\\aa.txt");
int i = 0;
//從檔案中讀取一個位元組以int值返回,當讀到檔案末尾沒有資料時返回-1;
while((i=fin.read()) != -1){
//byte->int->char
System.out.print((char)i);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
//流開啟之後,必須進行關閉
try {
if(fin != null){
fin.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 用FileInputStream讀取檔案的內容,一次讀取多個位元組的內容(有些中文沒有亂碼,有些亂碼;並且還多讀了一些內容)
*/
public static void readFile2() {
FileInputStream fin = null;
try {
fin = new FileInputStream("d:\\aa.txt");
int i = 0;
byte[] b = new byte[100];
//從檔案中讀取100個位元組,放大陣列中,i返回的是讀取到的位元組的數量,當讀到檔案末尾沒有資料時返回-1;
while((i=fin.read(b)) != -1){
//byte[] -> char[] -> String
String str = new String(b);
System.out.print(str);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
//流開啟之後,必須進行關閉
try {
if(fin != null){
fin.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 用FileOutputStream寫String到檔案
*/
public static void writeFile1(){
FileOutputStream fout = null;
try {
//當目標檔案不存在時,JVM會自動建立這個檔案,若已存在,則將內容寫到這個檔案中;
fout = new FileOutputStream("d:\\bb.txt",true); //true表示追加寫檔案
String str = "2.用FileOutputStream寫String到檔案";
//將String轉換為byte[]
byte[] b = str.getBytes();
fout.write(b);
System.out.println("檔案寫入完成");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
//流開啟之後,必須進行關閉
try {
if(fout != null){
fout.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 用FileOutputStream寫String到檔案,解決換行
*/
public static void writeFile2(){
FileOutputStream fout = null;
try {
//當目標檔案不存在時,JVM會自動建立這個檔案,若已存在,則將內容寫到這個檔案中;
fout = new FileOutputStream("d:\\bb.txt",true); //true表示追加寫檔案
for(int i=0;i<=10;i++){
//由於FileOutputStream不會處理換行,需要我們在String結尾加入\n
//記事本不能識別\n,能夠識別\r\n;
String str = i+".用FileOutputStream寫String到檔案\r\n";
//將String轉換為byte[]
byte[] b = str.getBytes();
fout.write(b);
}
System.out.println("檔案寫入完成");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
//流開啟之後,必須進行關閉
try {
if(fout != null){
fout.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}然後將FileInputStream和FileOutputStream拼接起來,就組成了拷貝貼上的功能;

但是這樣直接使用低階流去讀和寫檔案顯然不是我們想要的,因為效率有點低,於是我們需要在低階流上接上一個高階流,像這樣:

下面有程式碼來實現上面的過程,也即是拷貝檔案的過程:
package com.Jevin.io;
import java.io.*;
/**
* 檔案拷貝器
*/
public class FileCoper {
private FileCoper(){
}
/**
* 拷貝檔案的操作
* @param srcFile 原始檔
* @param desPath 目標路徑
*/
public static void copyFile(String srcFile,String desPath){
//從原始檔的String中取出檔名稱,也就是從例如:"D:\\tools\\Navicat.rar"中取到"Navicat.rar";
String[] arr = srcFile.split("\\\\");
String fileName = arr[arr.length-1];
//組織目標檔案:路徑名稱+分隔符+檔名稱
String desFile = desPath+"\\"+fileName;
//宣告輸入流:
FileInputStream fin = null;
BufferedInputStream bin = null;
//宣告輸出流:
FileOutputStream fout = null; //低階輸出流
BufferedOutputStream bout = null; //高階輸出流
try {
//建立輸入流:
fin = new FileInputStream(srcFile);
bin = new BufferedInputStream(fin);
//建立輸出流:首先初始化低階流,然後初始化高階流
fout = new FileOutputStream(desFile);
bout = new BufferedOutputStream(fout);
int i=0;
byte[] b = new byte[1024*1024];
while((i=bin.read(b))!=-1){
bout.write(b,0,i);
}
/**
* 如果關閉低階流,那麼會導致小於8k的檔案滯留在bout的緩衝區,所以要重新整理快取區
* 拷貝過程中,只要檔案的大小大於8k,則無需重新整理快取
*/
//bout.flush();
//由於採用了正確的流的關閉方式,所以無論檔案大小,無需重新整理快取
System.out.println("檔案拷貝完成,"+srcFile+"拷貝到目標檔案"+desFile+"完成");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
//錯誤的關閉方式
//if(fin != null){
// try {
// fin.close();
// } catch (IOException e) {
// e.printStackTrace();
// }
//}
//if(fout != null){
// try {
// fout.close();
// } catch (IOException e) {
// e.printStackTrace();
// }
//}
//正確的關閉方式
//高階流在關閉的時候:1.會自動關閉低階流;2.會自動重新整理快取
try {
if(bin != null){
bin.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
//bout關閉的時候,會自動重新整理緩衝區
if(bout != null){
bout.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args){
String file = "D:\\tools\\aa.txt";
//String file = "D:\\tools\\Navicat.rar";
copyFile(file,"d:\\");
}
}但是上面的程式碼有點問題,問題出在取檔名和拼接目標檔案路徑上,採用了"\\"和"\\\\"這兩種分隔符,但是不同作業系統上的分隔符是不一樣的,這樣寫的話就寫死了,違背java的可移植性特點,所以我們採用java.io.File來解決這個問題:
package com.Jevin.io;
import java.io.*;
/**
* 檔案拷貝器
*/
public class FileCoper {
private FileCoper(){
}
/**
* 拷貝檔案的操作
* @param srcFile 原始檔
* @param desPath 目標路徑
*/
public static void copyFile(String srcFile,String desPath){
//從原始檔的String中取出檔名稱
//File file = new File(srcFile);
//copyFile(file,desPath);
//繼續簡化
copyFile(new File(srcFile),desPath);
}
/**
* 拷貝檔案的操作
* @param srcFile 原始檔
* @param desPath 目標路徑
*/
public static void copyFile(File srcFile,String desPath){
//從原始檔的String中取出檔名稱
String fileName = srcFile.getName();
//組織目標檔案:路徑名稱+分隔符+檔名稱
String desFile = desPath+File.separator+fileName;
//宣告輸入流:
FileInputStream fin = null;
BufferedInputStream bin = null;
//宣告輸出流:
FileOutputStream fout = null; //低階輸出流
BufferedOutputStream bout = null; //高階輸出流
try {
//建立輸入流:
fin = new FileInputStream(srcFile);
bin = new BufferedInputStream(fin);
//建立輸出流:首先初始化低階流,然後初始化高階流
fout = new FileOutputStream(desFile);
bout = new BufferedOutputStream(fout);
int i=0;
byte[] b = new byte[1024*1024];
while((i=bin.read(b))!=-1){
bout.write(b,0,i);
}
System.out.println("檔案拷貝完成,"+srcFile+"拷貝到目標檔案"+desFile+"完成");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
//正確的關閉方式
//高階流在關閉的時候:1.會自動關閉低階流;2.會自動重新整理快取
try {
if(bin != null){
bin.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
//bout關閉的時候,會自動重新整理緩衝區
if(bout != null){
bout.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args){
String file = "D:\\tools\\aa.txt";
//String file = "D:\\tools\\Navicat.rar";
copyFile(file,"d:\\");
}
}但是這裡還有一個問題,一個相對較大的檔案拷貝是需要時間的,如果在拷貝的這段時間內,程式突然停下來的,檔案看似拷貝下來了,但是這個檔案是不完整的,那麼該如何解決這個問題呢?下面程式碼演示:
package com.Jevin.io;
import java.io.*;
/**
* 檔案拷貝器
*/
public class FileCoper {
private FileCoper(){
}
/**
* 拷貝檔案的操作
* @param srcFile 原始檔
* @param desPath 目標路徑
*/
public static void copyFile(String srcFile,String desPath){
//從原始檔的String中取出檔名稱
//File file = new File(srcFile);
//copyFile(file,desPath);
//繼續簡化
copyFile(new File(srcFile),desPath);
}
/**
* 拷貝檔案的操作
* @param srcFile 原始檔
* @param desPath 目標路徑
*/
public static void copyFile(File srcFile,String desPath){
//從原始檔的String中取出檔名稱
String fileName = srcFile.getName();
//判斷目標路徑是否存在,如果不存在,就把他創造出來;
File dpath = new File(desPath);
if(!dpath.exists()){
dpath.mkdirs();
}
//組織目標檔案:路徑名稱+分隔符+檔名稱
String desFile = desPath+File.separator+fileName;
String tempFile = desFile + ".td"; //拷貝過程中的臨時檔名稱
//宣告輸入流:
FileInputStream fin = null;
BufferedInputStream bin = null;
//宣告輸出流:
FileOutputStream fout = null; //低階輸出流
BufferedOutputStream bout = null; //高階輸出流
try {
//建立輸入流:
fin = new FileInputStream(srcFile);
bin = new BufferedInputStream(fin);
//建立輸出流:首先初始化低階流,然後初始化高階流
fout = new FileOutputStream(tempFile);
bout = new BufferedOutputStream(fout);
int i=0;
byte[] b = new byte[1024*1024];
while((i=bin.read(b))!=-1){
bout.write(b,0,i);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
//正確的關閉方式
//高階流在關閉的時候:1.會自動關閉低階流;2.會自動重新整理快取
try {
if(bin != null){
bin.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
//bout關閉的時候,會自動重新整理緩衝區
if(bout != null){
bout.close();
}
} catch (IOException e) {
e.printStackTrace();
}
//當檔案拷貝完成之後,把臨時檔名稱改成目標檔名稱
//這裡注意:需要在流關閉的時候才可以重新命名,要不然流將執行緒鎖住,無法改名
File file1 = new File(desFile);
File file2 = new File(tempFile);
if(file2.renameTo(file1)){
System.out.println("檔案拷貝完成,"+srcFile+"拷貝到目標檔案"+desFile+"完成");
}else{
System.err.println("拷貝失敗");
}
}
}
public static void main(String[] args){
//String file = "D:\\tools\\aa.txt";
String file = "D:\\tools\\Navicat.rar";
copyFile(file,"d:\\abc");
}
}但是這裡還有一個問題,以上只是解決了拷貝一個檔案到任意指定的資料夾中,但是實際還有將任意資料夾(包括其中的檔案)拷貝到任意資料夾中,這個又該如何實現呢?一下程式碼演示:
package com.Jevin.io;
import java.io.*;
/**
* 檔案拷貝器
*/
public class FileCoper {
private FileCoper(){
}
/**
* 拷貝檔案的操作
* @param srcFile 原始檔
* @param desPath 目標路徑
*/
public static void copyFile(File srcFile,String desPath){
//從原始檔的String中取出檔名稱
String fileName = srcFile.getName();
//判斷目標路徑是否存在,如果不存在,就把他創造出來;
File dpath = new File(desPath);
if(!dpath.exists()){
dpath.mkdirs();
}
//組織目標檔案:路徑名稱+分隔符+檔名稱
String desFile = desPath+File.separator+fileName;
String tempFile = desFile + ".td"; //拷貝過程中的臨時檔名稱
//宣告輸入流:
FileInputStream fin = null;
BufferedInputStream bin = null;
//宣告輸出流:
FileOutputStream fout = null; //低階輸出流
BufferedOutputStream bout = null; //高階輸出流
try {
//建立輸入流:
fin = new FileInputStream(srcFile);
bin = new BufferedInputStream(fin);
//建立輸出流:首先初始化低階流,然後初始化高階流
fout = new FileOutputStream(tempFile);
bout = new BufferedOutputStream(fout);
int i=0;
byte[] b = new byte[1024*1024];
while((i=bin.read(b))!=-1){
bout.write(b,0,i);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
//正確的關閉方式
//高階流在關閉的時候:1.會自動關閉低階流;2.會自動重新整理快取
try {
if(bin != null){
bin.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
//bout關閉的時候,會自動重新整理緩衝區
if(bout != null){
bout.close();
}
} catch (IOException e) {
e.printStackTrace();
}
//當檔案拷貝完成之後,把臨時檔名稱改成目標檔名稱
//這裡注意:需要在流關閉的時候才可以重新命名,要不然流將執行緒鎖住,無法改名
File file1 = new File(desFile);
File file2 = new File(tempFile);
if(file2.renameTo(file1)){
System.out.println("檔案拷貝完成,"+srcFile+"拷貝到目標檔案"+desFile+"完成");
}else{
System.err.println("拷貝失敗");
}
}
}
/**
* 拷貝資料夾的功能
* @param srcPath 原資料夾
* @param desPath 目標路徑
*/
public static void copyDir(String srcPath,String desPath){
copyDir(new File(srcPath),desPath);
}
/**
* 拷貝資料夾的功能
* @param srcPath 原資料夾
* @param desPath 目標路徑
*/
public static void copyDir(File srcPath,String desPath){
//判斷srcPath是檔案還是資料夾:
if(srcPath.isFile()){
//是檔案,那麼呼叫之前拷貝檔案的方法:
copyFile(srcPath,desPath);
}else{
//是資料夾:
//從原檔案中獲取要拷貝的資料夾名稱,例如,我要拷貝jdk原始碼"D:\\file\\src",從中獲取src
String pathName = srcPath.getName();
//在目標路徑中建立要拷貝的目錄,例如在"d:\\"建立"src"目錄:
String dPath = desPath+File.separator+pathName; //"d:\\src"
File file = new File(dPath);
file.mkdirs();
//獲取原資料夾中所有子檔案(夾)
File[] files = srcPath.listFiles();
//遍歷存放子檔案的陣列,一個個的拷貝到目標路徑中,也就是dPath
for(File file1:files){
copyDir(file1,dPath); //遞迴呼叫
}
}
}
public static void main(String[] args){
//String file = "D:\\tools\\aa.txt";
//String file = "D:\\tools\\Navicat.rar";
//copyFile(file,"d:\\abc");
String file = "D:\\file\\src";
copyDir(file,"d:\\");
}
}這裡檔案或資料夾拷貝告一段落了,反觀之前的FileOutputStream這個低階流在實現寫的時候,有一些瑕疵,模型如下:

package com.Jevin.io;
import java.io.*;
public class ByteStreamTest {
public static void main(String[] args) {
writeFile3();
}
/**
* 在FileOutputStream上接一個高階流PrintStream輸出
*/
public static void writeFile3(){
FileOutputStream fout = null;
PrintStream ps = null;
try {
fout = new FileOutputStream("d:\\dd.txt",true);
ps = new PrintStream(fout);
for(int i=0;i<1000;i++){
String str = i+"在FileOutputStream上接一個高階流PrintStream輸出";
//為了方便操作,ps.println(str)/ps.close()暫時不需要處理異常;
ps.println(str);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}finally{
if(ps != null){
ps.close();
}
}
}
}================================================================================================
以上講的都是位元組流,從這裡我們開始講講字元流的使用。
首先是使用字元流去讀取檔案中的資料,模型如下:
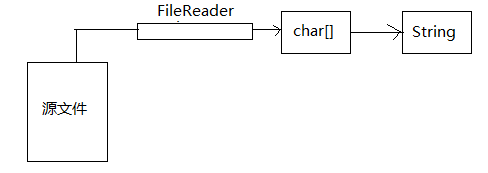
以下是程式碼演示:
package com.Jevin.io;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class CharacterStreamTest {
public static void main(String[] args){
//readFile1();
readFile2();
}
/**
* 用FileReader讀取檔案的內容,一個一個字元的讀取
*/
public static void readFile1(){
FileReader fr = null;
try {
fr = new FileReader("d:\\aa.txt");
int i = 0;
//讀取一個字元,當做int返回,直到檔案末尾沒有字元時返回-1;
while((i=fr.read()) != -1){
//char -> int -> char
System.out.print((char)i);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(fr != null){
fr.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 用FileReader讀取檔案的內容,一次讀取多個字元的資料
*/
public static void readFile2(){
FileReader fr = null;
try {
fr = new FileReader("d:\\aa.txt");
int i = 0;
char[] c = new char[1024];
//讀取多個字元,儲存到陣列中,i是讀取到的字元的數量
while((i=fr.read(c)) != -1){
//char[] -> String
String str = new String(c,0,i);
System.out.print(str);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(fr != null){
fr.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}但是這樣用低階流去讀取檔案是字元陣列,然後還要手動轉換為字串,這樣在讀取大檔案時效率不高,這時我沒需要在低階流上接一個高階流,利用高階流的快取一行一行的讀取資料,效率大大提高,一下模型演示:

下面是程式碼演示:
package com.Jevin.io;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class CharacterStreamTest {
public static void main(String[] args) {
readFile3();
}
/**
* 用FileReader和BufferReader讀取檔案中的內容
*/
public static void readFile3() {
FileReader fr = null;
BufferedReader br = null;
try {
fr = new FileReader("d:\\aa.txt");
br = new BufferedReader(fr);
String str = null;
while ((str = br.readLine()) != null) {
System.out.println(str);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}這裡簡單的位元組流和字元流就介紹到這裡,接下來介紹一個有意思的流:RandomAccessFile,它可以從檔案的任意位置讀,也可以從檔案的任意位置寫。寫個功能有什麼用呢?換言之:可以將一個大檔案切割成多個小檔案分別讀寫。
模型如下所示:

程式碼如下所示:
package com.Jevin.io.demo;
import java.io.File;
/**
* 檔案拷貝包工頭
*/
public class FileCopyContractor {
private File srcFile; //原始檔
private String desFile; //目標檔案
private String tempFile; //拷貝過程中的臨時檔案
private int splitCount; //檔案切分的份數
public FileCopyContractor(){}
public FileCopyContractor(File srcFile, String desPath, int splitCount) {
super();
this.srcFile = srcFile;
this.splitCount = splitCount;
//組織目標檔案:
String fileName = srcFile.getName();
this.desFile = desPath + File.separator + fileName;
this.tempFile = desFile + ".td";
}
public FileCopyContractor(String srcFile, String desPath, int splitCount) {
this(new File(srcFile),desPath,splitCount);
}
/**
* 包工頭開始工作:
*/
public void start(){
//獲取原檔案的大小:
long fileSize = srcFile.length();
System.out.println("檔案的大小是:"+fileSize);
//根據切分的份數和原始檔的大小,計算每個工人的平均工作量
long perWorkerSize = fileSize/this.splitCount;
//計算第一個工人的開始位置和結束位置:
long startPost = 0L;
long endPost = perWorkerSize;
//包工頭建立多個工人:
for(int i=0;i<this.splitCount;i++){
//建立工人物件:
FileCopyWorker fileCopyWorker = new FileCopyWorker("工人-"+i,srcFile,tempFile,startPost,endPost);
//工人開始工作:
fileCopyWorker.work();
//包工頭計算下一個工人的開始位置和結束位置:
startPost = endPost;
endPost = startPost + perWorkerSize;
//如果是最後一個工人,則做到最後;
if(i == this.splitCount-2){
endPost = fileSize;
}
}
//所有工人完成工作之後,把臨時檔名稱改成目標檔名稱:
File file1 = new File(this.tempFile);
File file2 = new File(this.desFile);
if(file1.renameTo(file2)){
System.out.println(this.srcFile + "拷貝到"+this.desFile+"完成");
}else{
System.out.println("重新命名檔案失敗");
}
}
}package com.Jevin.io.demo;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
/**
* 檔案拷貝工人
*/
public class FileCopyWorker {
private String name; //工人名稱
private File srcFile; //原始檔
private String desFile; //目標檔案
private long startPost; //開始位置
private long endPost; //結束位置
private long copyedPost; //已經拷貝的位置
public FileCopyWorker(String name, File srcFile, String desFile, long startPost, long endPost) {
super();
this.name = name;
this.srcFile = srcFile;
this.desFile = desFile;
this.startPost = startPost;
this.endPost = endPost;
this.copyedPost = this.startPost; //初始化拷貝位置即為初始位置
System.out.println(name+"[開始位置是:"+this.startPost+",結束位置是:"+this.endPost+"]");
}
/**
* 工人開始工作
*/
public void work(){
RandomAccessFile rin = null; //讀資料流
RandomAccessFile rout = null; //寫資料流
try {
rin = new RandomAccessFile(this.srcFile,"r");
rout = new RandomAccessFile(this.desFile,"rw");
//定位讀寫的位置:
rin.seek(this.startPost); //開始讀的位置
rout.seek(this.startPost); //開始寫的位置
byte[] b = new byte[1024*1024];
int i = 0;
//當已經拷貝的位置小於結束位置,並且未拷貝到檔案結尾,就一直迴圈拷貝下去:
while((this.copyedPost < this.endPost) && (i=rin.read(b)) != -1){
if((this.copyedPost + i) > this.endPost){
i = (int) (this.endPost - this.copyedPost);
}
rout.write(b,0,i);
this.copyedPost += i;
System.out.println(name+"正在工作,已經拷貝的位置是:"+this.copyedPost+",結束位置是:"+this.endPost);
}
System.out.println(name+"結束工作,已經拷貝的位置是:"+this.copyedPost+",結束位置是:"+this.endPost);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(rin != null){
rin.close();
}
if(rout != null){
rout.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}package com.Jevin.io.demo;
public class MainTest {
public static void main(String[] args){
String file = "D:\\tools\\Navicat.rar";
FileCopyContractor fileCopyContractor = new FileCopyContractor(file,"d:\\",15);
fileCopyContractor.start();
}
}“流”暫時就到這裡吧,又補充的再繼續吧!