00_抓取貓眼電影排行TOP100
阿新 • • 發佈:2018-11-04
前言:
學習python3爬蟲大概有一週的時間,熟悉了爬蟲的一些基本原理和基本庫的使用,本次就準備利用requests庫和正則表示式來抓取貓眼電影排行TOP100的相關內容。
1、本次目標:
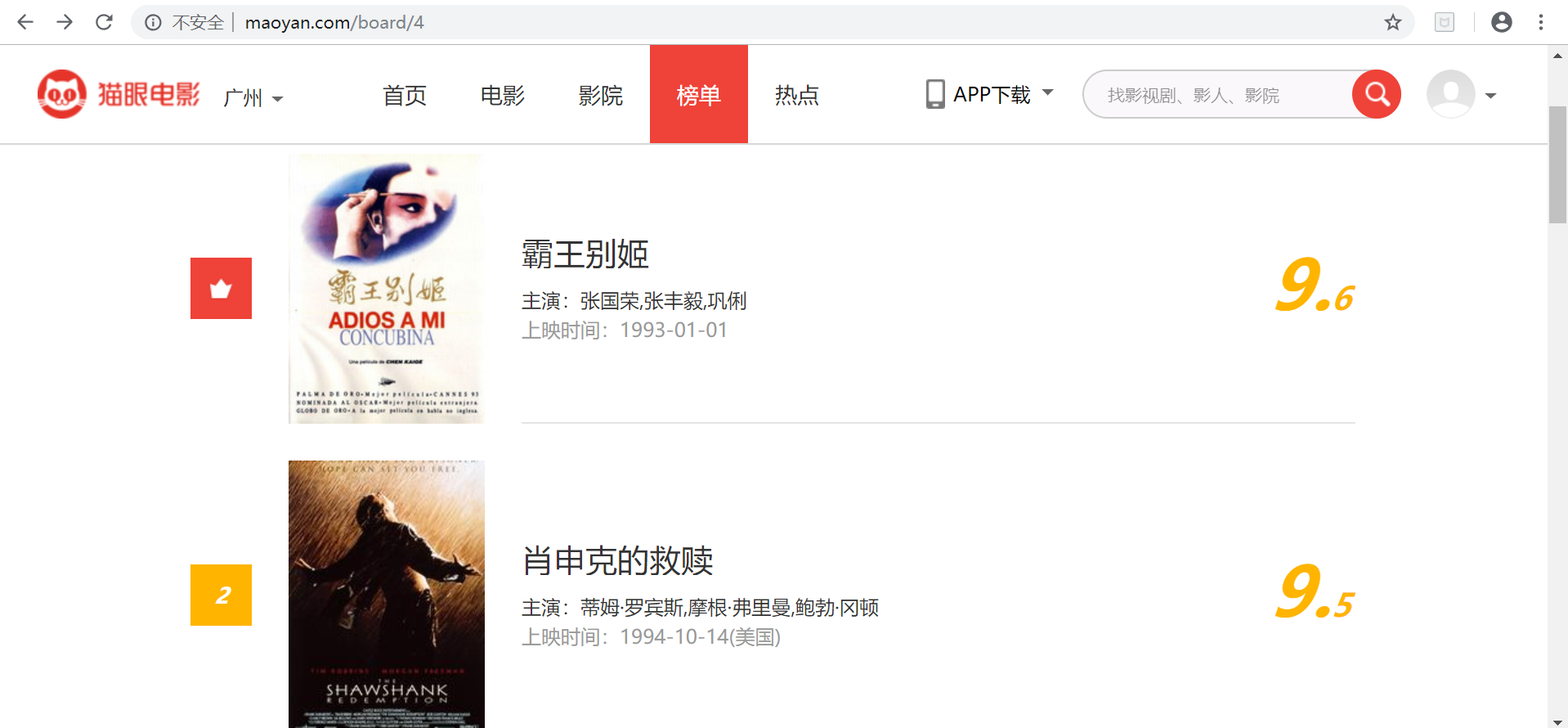
需要爬去出貓眼電影排行TOP100的電影相關資訊,包括:名稱、圖片、演員、時間、評分,排名。提取站點的URL為http://maoyan.com/board/4,提取的結果以文字形式儲存下來。
2、準備工作
只需要安裝好requests庫即可。
安裝方式有很多種,這裡只簡單的介紹一下通過pip這個包管理工具來安裝。
在命令列介面中輸入pip3 install requests即可完成安裝。(無論是windows、linux、還是mac,都可以使用該方式)
完成之後可以匯入requests模組進行測試:
>python Python 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:04:45) [MSC v.1900 32 bit (Intel)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import requests >>>
如果沒有錯誤提示,就證明已經成功安裝了。
3、抓取分析
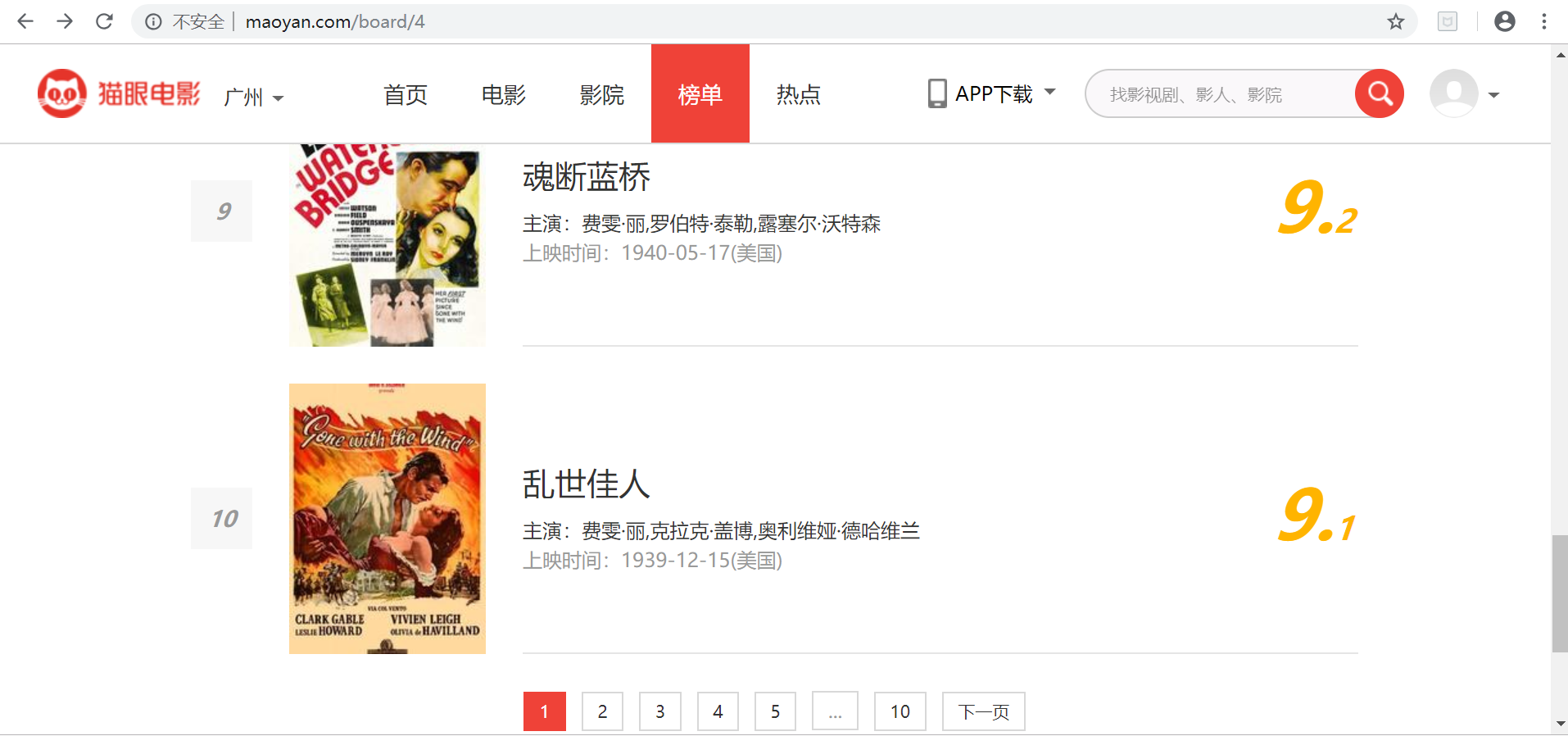
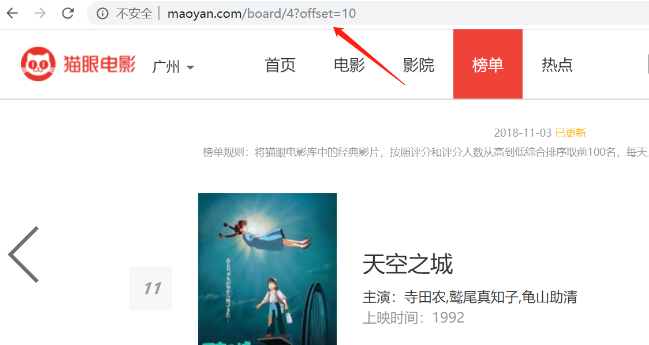
首先進入目標站點http://maoyan.com/board/4,可以看到有電影的排名、演員、時間、評分等資訊,翻到頁面底部可以發現,每個頁面有10部電影,點選下一頁可看到站點的URL變為了http://maoyan.com/board/4?offset=10,裡面是排名11-20的電影。也就是說要獲取TOP100的電影資訊,只需要請求offset=0,10,20...90的頁面,然後再利用正則表示式爬取每一頁所需要的電影資訊即可。