正則匹配的抓取貓眼電影排行Top100
阿新 • • 發佈:2019-02-16
本案例,我們利用requests庫和正則表示式來抓取貓眼電影TOP100的相關內容。
1.目標
提取貓眼電影Top100的電影名稱、時間、評分、圖片(下載),提取的站點URL為:http://maoyan.com/board/4,圖片將儲存到指定資料夾中。
2.準備工作
需要安裝requests包(安裝方式:在配好的環境中:pip install requests即可)
3.抓取分析
通過開啟網頁,找到網頁之間的規律,如圖:
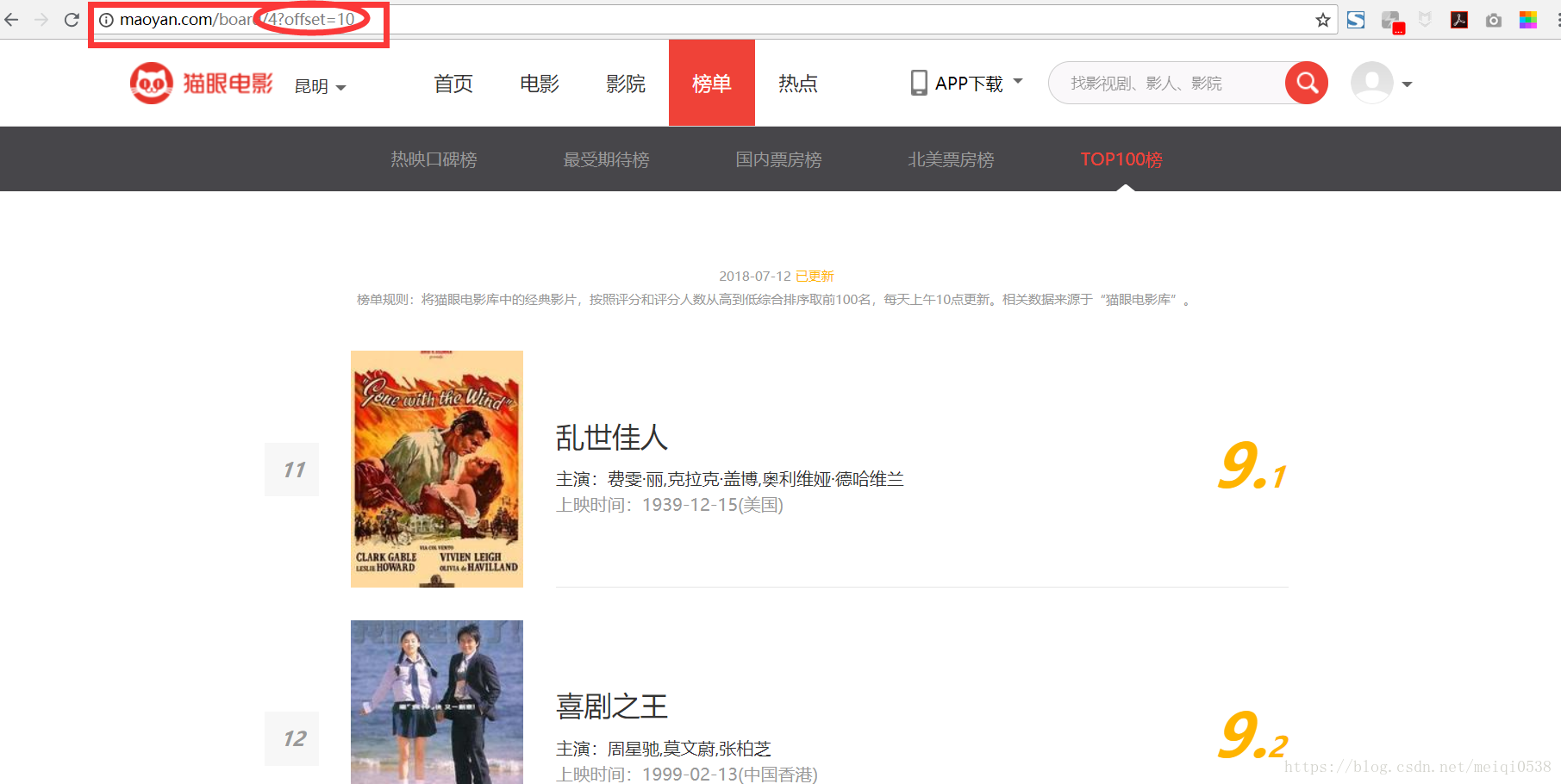
可以發現頁面的URL變成:http://maoyan.com/board/4?offset=10,比之前的URL多一個引數,offset=10,並且目前顯示的結果是:11~20名的電影,由此可以找到其他排名電影頁面的URL規律。
4. 正則提取分析
在瀏覽器端的開發者模式下的Network監聽元件下檢視原始碼,如圖:
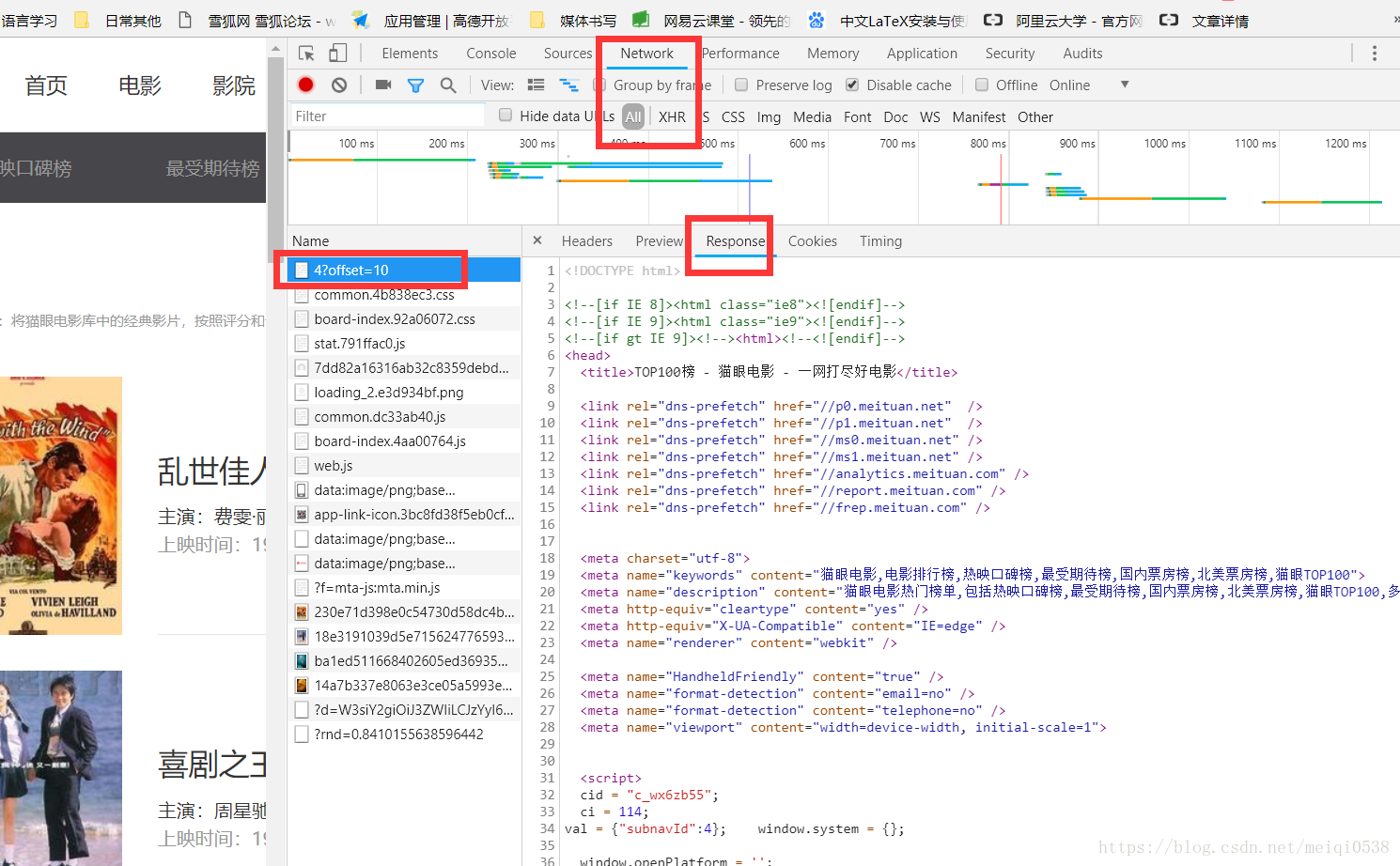
而每個電影的內容都在一個dd標籤下:

正則表示式書寫:
<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i 需要說明的是:以上的每個括號表示的就是要獲取的內容。
5.寫入檔案
在獲取提取的結果後,我們將資料寫到一個txt文件中,這裡資料是使用json格式的內容書寫的。
6.下載圖片
涉及到語言、圖片、視訊的時候,我們可以使用:with open("",'rb')的形式書寫。儲存。
7.程式碼詳解
#爬蟲庫
import requests
#json資料格式庫
import json
#requests異常
from requests.exceptions import RequestException
#正則表示式 8.執行結果