
Hadoop之執行模式
Hadoop執行模式包括:本地模式、偽分散式以及完全分散式模式。
一、本地執行模式
1、官方Grep案例
1)在hadoop-2.7.2目錄下建立一個 input 資料夾
[[email protected] hadoop-2.7.2]$ mkdir input
2)將hadoop的xml配置檔案複製到 input
[[email protected] hadoop-2.7.2]$ cp etc/hadoop/*.xml input
3)執行share 目錄下的MapReduce 程式
[[email protected]hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
4)檢視輸出結果
[[email protected] hadoop-2.7.2]$ cat output/*
2、官方WordCount 案例
1)在hadoop-2.7.2目錄下建立一個 wcinput 資料夾
[[email protected] hadoop-2.7.2]$ mkdir wcinput
2)在wcinput檔案家下建立一個 wc.input 檔案
[[email protected] hadoop-2.7.2]$ cd wcinput [[email protected] wcinput]$ touch wc.input
3)編輯 wc.input 檔案,輸入如下內容
hadoop yarn
hadoop mapreduce
tom
tom
4)回到hadoop目錄 /opt/module/hadoop-2.7.2
5)執行程式
[[email protected] hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
6)檢視結果
[[email protected] hadoop-2.7.2]$ cat wcoutput/part-r-00000 tom 2 hadoop 2 mapreduce 1 yarn 1
二、偽分散式執行模式
1、啟動HDFS並執行MapReduce程式
1、分析
1)配置叢集
2)啟動、測試叢集 增、刪、查
3)執行 WordCount 案例
2、執行步驟
1)配置叢集
a、配置:hadoop-env.sh
Linux系統中獲取JDK的安裝路徑
[[email protected] hadoop101 ~]# echo $JAVA_HOME /opt/module/jdk1.8.0_144
修改JAVA_HOME路徑:
export JAVA_HOME=/opt/module/jdk1.8.0_144
b、配置:core-site.xml
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop101:9000</value> </property> <!-- 指定Hadoop執行時產生檔案的儲存目錄 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property>
c、配置:hdfs-site.xml
<!-- 指定HDFS副本的數量 --> <property> <name>dfs.replication</name> <value>1</value> </property>
2)啟動叢集
a、格式化NameNode(第一次啟動時格式化,以後就不要總格式化)
[[email protected] hadoop-2.7.2]$ bin/hdfs namenode -format
b、啟動NameNode
[[email protected] hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
c、啟動DataNode
[[email protected] hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
3)檢視叢集
a、檢視是否啟動成功
[[email protected] hadoop-2.7.2]$ jps 13586 NameNode 13668 DataNode 13786 Jps
b、web端檢視HDFS檔案系統
http://hadoop101:50070/dfshealth.html#tab-overview
注意:如果不能檢視,看如下帖子處理:http://www.cnblogs.com/zlslch/p/6604189.html
c、檢視產生的Log日誌
當前目錄:/opt/module/hadoop-2.7.2/logs
[[email protected] logs]$ ls hadoop-atguigu-datanode-hadoop.atguigu.com.log hadoop-atguigu-datanode-hadoop.atguigu.com.out hadoop-atguigu-namenode-hadoop.atguigu.com.log hadoop-atguigu-namenode-hadoop.atguigu.com.out SecurityAuth-root.audit [[email protected] logs]# cat hadoop-atguigu-datanode-hadoop101.log
d、思考:為什麼不能一直格式化NameNode,格式化NameNode,要注意什麼?
[[email protected] hadoop-2.7.2]$ cd data/tmp/dfs/name/current/ [[email protected] current]$ cat VERSION clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837 [[email protected] hadoop-2.7.2]$ cd data/tmp/dfs/data/current/
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837
注意:格式化NameNode,會產生新的叢集id,導致NameNode和DataNode的叢集id不一致,叢集找不到以往資料。所以,格式化NameNode時,一定要先刪除data資料和log日誌,然後再格式化NameNode。
4)操作叢集
a、在HDFS檔案系統上建立一個 input 資料夾
[[email protected] hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /user/hadoop/input
b、將測試檔案內容上傳到檔案系統上
[[email protected] hadoop-2.7.2]$bin/hdfs dfs -put wcinput/wc.input /user/hadoop/input/
c、檢視上傳的檔案是否正確
[[email protected] hadoop-2.7.2]$ bin/hdfs dfs -ls /user/hadoop/input/ [[email protected] hadoop-2.7.2]$ bin/hdfs dfs -cat /user/hadoop/input/wc.input
d、執行MapReduce程式
[[email protected] hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/hadoop/input/ /user/hadoop/output
e、檢視輸出結果
命令列檢視:
[[email protected] hadoop-2.7.2]$ bin/hdfs dfs -cat /user/hadoop/output/*
瀏覽器檢視:

f、將測試檔案內容下載到本地
[[email protected] hadoop-2.7.2]$ hdfs dfs -get /user/hadoop/output/part-r-00000 ./wcoutput/
g、刪除輸出結果
[[email protected] hadoop-2.7.2]$ hdfs dfs -rm -r /user/hadoop/output
2、啟動YARN並執行MapReduce程式
1、分析
1)配置叢集在YARN上執行MR
2)啟動、測試叢集 增、刪、查
3)在YARN上執行WordCount案例
2、執行步驟
1)配置叢集
a、配置yarn-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
b、配置yarn-site.xml
<!-- Reducer獲取資料的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop101</value> </property>
c、配置:mapred-env.sh
配置一下 JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
d、配置:(對mapred-site.xml.template重新命名為)mapred-site.xml
[[email protected] hadoop]$ mv mapred-site.xml.template mapred-site.xml [[email protected] hadoop]$ vi mapred-site.xml <!-- 指定MR執行在YARN上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
2)啟動叢集
a、啟動前必須保證NameNode和DataNode已經啟動
b、啟動ResourceManager
[[email protected] hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
c、啟動NodeManager
[[email protected] hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
3)叢集操作
a、yarn的瀏覽器頁面檢視:

b、刪除檔案系統上的output資料夾
[[email protected] hadoop-2.7.2]$ bin/hdfs dfs -rm -R /user/atguigu/output
c、執行MapReduce程式
[[email protected] hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/hadoop/input /user/hadoop/output
d、檢視執行結果:
[[email protected] hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/output/*
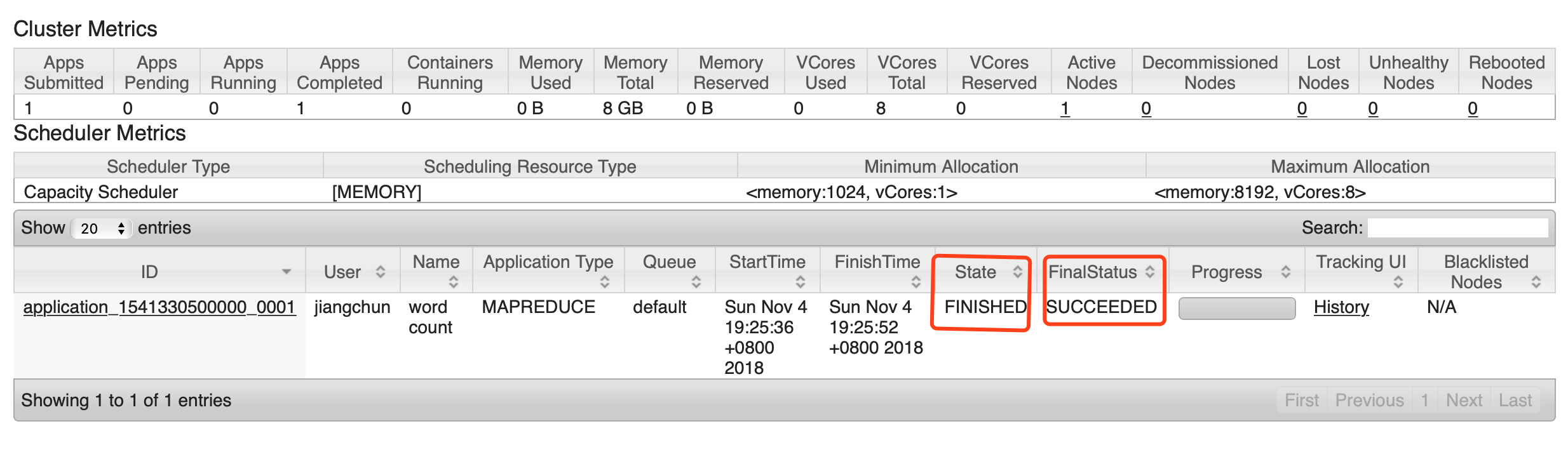
3、配置歷史伺服器
為了檢視程式的歷史執行情況,需要配置一下歷史伺服器,具體配置步驟如下:
1)配置mapred-site.xml
在該檔案裡面增加如下配置:
<!-- 歷史伺服器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop101:10020</value> </property>
<!-- 歷史伺服器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop101:19888</value> </property>
2)啟動歷史伺服器
[[email protected] hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
3)檢視歷史伺服器是否啟動
[[email protected] hadoop-2.7.2]$ jps
4)檢視JobHistory
http://hadoop101:19888/jobhistory
4、配置日誌的聚集
日誌聚集概念:應用執行完成以後,將程式執行日誌資訊上傳到HDFS系統上。
日誌聚集功能好處:可以方便地檢視到程式執行詳情,方便開發除錯。
注意:開啟日誌聚集功能,需要重新啟動 NodeManager、ResourceManager 和 HistoryManager。
步驟如下:
1)配置 yarn-site.xml
在該檔案裡面增加如下配置:
<!-- 日誌聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日誌保留時間設定7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
2)關閉 NodeManager、ResourceManager 和 HistoryManager
[[email protected] hadoop-2.7.2]$ sbin/yarn-daemon.sh stop resourcemanager
[[email protected] hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
[[email protected] hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh stop historyserver
3)啟動NodeManager、ResourceManager 和 HistoryManager
[[email protected] hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager [[email protected] hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager [[email protected] hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
4)刪除HDFS 上已經存在的輸出檔案
[[email protected] hadoop-2.7.2]$ bin/hdfs dfs -rm -R /user/atguigu/output
5)執行 WordCount 程式
[[email protected] hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input /user/atguigu/output
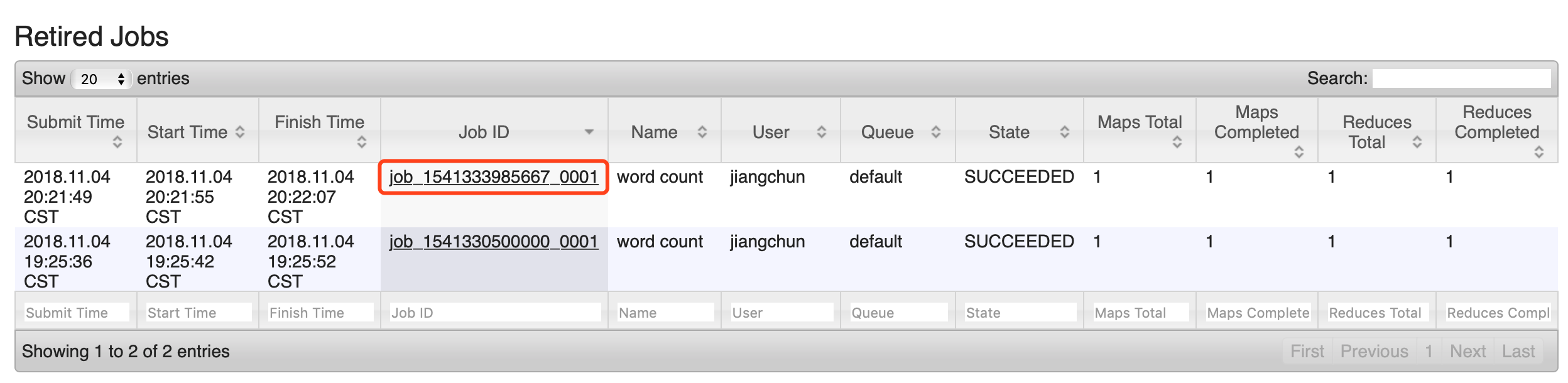
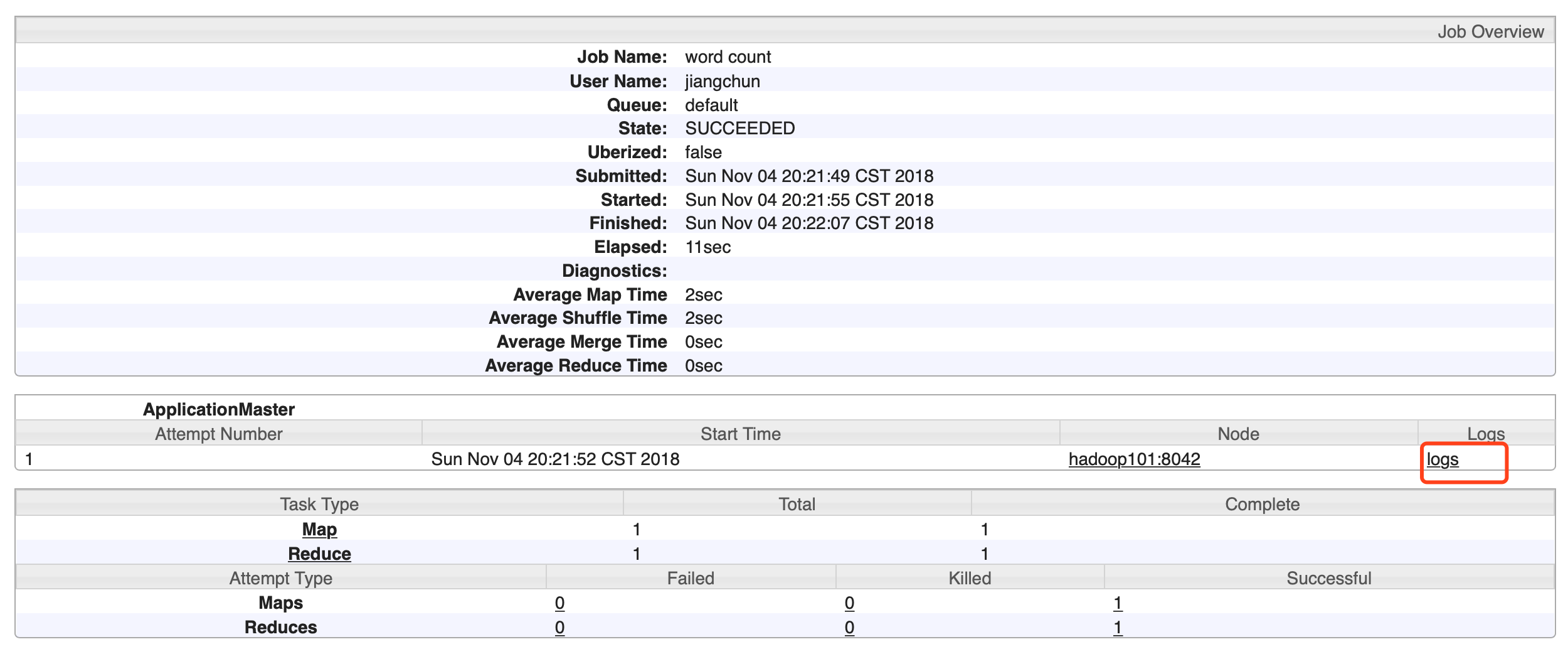
6)檢視日誌,如圖
http://hadoop101:19888/jobhistory

5、配置檔案說明
Hadoop配置檔案分兩類:預設配置檔案和自定義配置檔案,只有使用者想修改某一預設配置值時,才需要修改自定義配置檔案,更改相應屬性值。
1)預設配置檔案:
| 要獲取的預設檔案 | 檔案存放在hadoop的jar包中的位置 |
| core-default.xml | hadoop-common-2.7.2.jar/core-default.xml |
| hdfs-default.xml | hadoop-hdfs-2.7.2.jar/hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-2.7.2.jar/yarn-default.xml |
| mapred-default.xml | hadoop-mapreduce-client-core-2.7.2.jar/mapred-default.xml |
2)自定義配置檔案:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四個配置檔案存放在 $HADOOP_HOME/etc/hadoop 這個路徑上,使用者可以根據專案需求重新進行修改配置。