
Hadoop之搭建完全分散式執行模式
一、過程分析
1、準備3臺客戶機(關閉防火牆、修改靜態ip、主機名稱)
2、安裝JDK
3、配置環境變數
4、安裝Hadoop
5、配置叢集
6、單點啟動
7、配置ssh免密登入
8、群起並測試叢集
二、編寫叢集分發指令碼 xsync
1、scp(secure copy)安全拷貝
1)scp定義
scp可以實現伺服器與伺服器之間的資料拷貝。
2)基本語法
scp -r 檔案 使用者名稱@主機:目標路徑/名稱
3)案例
a、在hadoop101上,將hadoop101中 /opt/module 目錄下的軟體拷貝到 hadoop102上。
[[email protected]101 /]$ scp -r /opt/module [email protected]:/opt/module
b、在hadoop103上,將hadoop101伺服器上的/opt/module 目錄下的軟體拷貝到 hadoop103上。
[[email protected]103 opt]$sudo scp -r [email protected]:/opt/module [email protected]:/opt/module
c、在hadoop103上操作hadoop101 中/opt/module 目錄下的軟體 拷貝到 hadoop104上。
[[email protected] opt]$ scp -r [email protected]:/opt/module [email protected]:/opt/module
注意:拷貝過來的/opt/module目錄,別忘了在hadoop102、hadoop103、hadoop104上修改所有檔案的所有者和所有者組。
sudo chown hadoop:hadoop -R /opt/module
d、分別將hadoop101 中/etc/profile 檔案拷貝到hadoop102、103、104、的/etc/profile上。
[[email protected]~]$ sudo scp /etc/profile [email protected]:/etc/profile
[[email protected] ~]$ sudo scp /etc/profile [email protected]:/etc/profile
[[email protected] ~]$ sudo scp /etc/profile [email protected]:/etc/profile
注意:拷貝完成後,需要source一下
2、rsync 遠端同步工具
rsync主要用於備份和映象,具有速度快、避免複製相同內容和支援符號連結的優點。
rsync 和 scp 區別:用 rsync 做檔案的複製要比 scp 的速度快,rsync 只對差異檔案做更新。scp是把所有檔案都複製過去。
1)語法
rsync -rvl 要拷貝的檔案路徑/名稱 目的使用者@主機:目的路徑/名稱
選項引數說明:
| 選項 | 功能 |
| -r | 遞迴 |
| -v | 顯示覆制過程 |
| -l | 拷貝符號連線 |
2)案例
a、把hadoop101 機器上的 /opt/software 目錄同步到 hadoop102 伺服器的 root使用者下的 /opt目錄
[[email protected] opt]$ rsync -rvl /opt/software/ [email protected]:/opt/software
3、xsync叢集分發指令碼
1)需求:迴圈複製檔案到所有節點的相同目錄下
2)分析
a、rsync命令原始拷貝:
rsync -rvl /opt/module [email protected]:/opt/
b、期望指令碼:
xsync 要同步的檔名稱
c、說明:在/home/hadoop/bin 這個目錄下存放的指令碼,hadoop使用者可以在系統任何地方直接執行。
3)指令碼實現
a、在/home/hadoop 目錄下建立bin 目錄,並在 bin目錄下建立xsync檔案,檔案內容如下:
[[email protected] ~]$ mkdir bin [[email protected] ~]$ cd bin/ [[email protected] bin]$ touch xsync [[email protected] bin]$ vi xsync
在該檔案中編寫如下程式碼:
#!/bin/bash #1 獲取輸入引數個數,如果沒有引數,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 獲取檔名稱 p1=$1 fname=`basename $p1` echo fname=$fname #3 獲取上級目錄到絕對路徑 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 獲取當前使用者名稱稱 user=`whoami` #5 迴圈 for((host=103; host<105; host++)); do echo ------------------- hadoop$host -------------- rsync -rvl $pdir/$fname [email protected]$host:$pdir done
b、修改指令碼 xsync 具有執行許可權
[[email protected] bin]$ chmod 777 xsync
c、呼叫指令碼形式:xsync 檔名稱
[[email protected] bin]$ xsync /home/hadoop/bin
注意:如果將xsync 放到/home/hadoop/bin 目錄下仍然不能實現全域性使用,可以將xsync 移動到/usr/local/bin 目錄下。
三、叢集配置
1、叢集部署規劃
| hadoop102 | hadoop103 | hadoop104 | |
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN |
NodeManager | ResourceManager NodeManager |
NodeManager |
2、配置叢集
1)核心配置檔案
配置core-site.xml
[[email protected] hadoop]$ vi core-site.xml
在該檔案中編寫如下配置:
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:9000</value> </property> <!-- 指定Hadoop執行時產生檔案的儲存目錄 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property>
2)HDFS 配置檔案
配置 hadoop-env.sh
[[email protected] hadoop]$ vi hadoop-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_144
配置 hdfs-site.xml
[[email protected] hadoop]$ vi hdfs-site.xml
在該檔案中編寫如下配置:
<property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop輔助名稱節點主機配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:50090</value> </property>
3)YARN 配置檔案
配置 yarn-env.sh
[[email protected] hadoop]$ vi yarn-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_144
配置 yarn-site.xml
[[email protected] hadoop]$ vi yarn-site.xml
在該檔案中增加如下配置:
<!-- Reducer獲取資料的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property>
4)MapReduce 配置檔案
配置 mapred-env.sh
[[email protected] hadoop]$ vi mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置 mapred-site.xml
[[email protected] hadoop]$ cp mapred-site.xml.template mapred-site.xml [[email protected] hadoop]$ vi mapred-site.xml
在該檔案中增加如下配置
<!-- 指定MR執行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
3、在叢集上分發配置好的 Hadoop 配置檔案
[[email protected] hadoop]$ xsync /opt/module/hadoop-2.7.2/
4、檢視檔案分發情況
[[email protected] hadoop]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
四、叢集單點啟動
1、如果叢集是第一次啟動,需要格式化 NameNode
[[email protected] hadoop-2.7.2]$ hadoop namenode -format
2、在 hadoop102 上啟動 NameNode
[[email protected] hadoop-2.7.2]$ hadoop-daemon.sh start namenode [[email protected] hadoop-2.7.2]$ jps 3461 NameNode
3、在 hadoop102、hadoop103 以及 hadoop 104上分別啟動 DataNode
[[email protected] hadoop-2.7.2]$ hadoop-daemon.sh start datanode [[email protected] hadoop-2.7.2]$ jps 3461 NameNode 3608 Jps 3561 DataNode
[[email protected] hadoop-2.7.2]$ hadoop-daemon.sh start datanode [[email protected] hadoop-2.7.2]$ jps 3190 DataNode 3279 Jps
[[email protected] hadoop-2.7.2]$ hadoop-daemon.sh start datanode [[email protected] hadoop-2.7.2]$ jps 3237 Jps 3163 DataNode
4、思考:每次都一個一個節點啟動,如果節點數目增加到1000個 怎麼辦?
五、SSH 無密登入配置
1、無金鑰配置
1)免登入原理
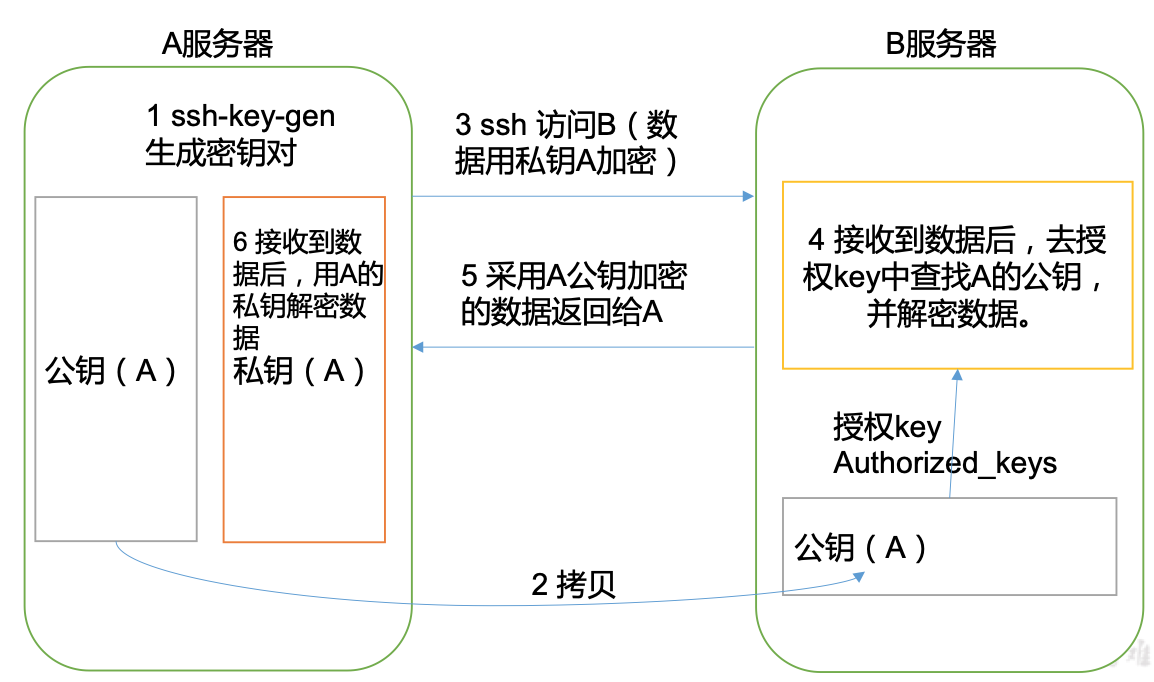
2)生成公鑰和私鑰
[[email protected] .ssh]$ ssh-keygen -t rsa
然後敲(三個回車),就會生成兩個檔案 id_rsa(私鑰)、id_rsa.pub(公鑰)
3)將公鑰拷貝到要免密登入的目標機器上
[[email protected] .ssh]$ ssh-copy-id hadoop102 [[email protected] .ssh]$ ssh-copy-id hadoop103 [[email protected] .ssh]$ ssh-copy-id hadoop104
注意:還需要在hadoop102 上採用 root賬號,配置一下無密登入到 hadoop102、hadoop103、hadoop104。
還需要在hadoop103 上採用 hadoop賬號,配置一下無密登入到hadoop102、hadoop103、hadoop104 伺服器上。
2、.ssh 資料夾下(~/.ssh)的檔案功能解釋
| known_hosts | 記錄ssh訪問過計算機的公鑰(public key) |
| id_rsa | 生成的私鑰 |
| id_rsa.pub | 生成的公鑰 |
| authorized_keys | 存放授權過的無密登入伺服器公鑰 |
六、群起叢集
1、配置 slaves
/opt/module/hadoop-2.7.2/etc/hadoop/slaves [[email protected] hadoop]$ vi slaves
在該檔案中增加如下內容:
hadoop102
hadoop103
hadoop104
注意:該檔案中新增的內容結尾不允許有空格,檔案中不允許有空行。
2、啟動叢集
1)如果叢集是第一次啟動,需要格式化 NameNode(注意格式化之前,一定要先停止上次啟動的所有 namenode 和 datanode 程序,然後再刪除 data 和 log 資料)
[[email protected] hadoop-2.7.2]$ bin/hdfs namenode -format
2)啟動 HDFS
[[email protected] hadoop-2.7.2]$ sbin/start-dfs.sh [[email protected] hadoop-2.7.2]$ jps 4166 NameNode 4482 Jps 4263 DataNode
[[email protected] hadoop-2.7.2]$ jps 3218 DataNode 3288 Jps [[email protected] hadoop-2.7.2]$ jps 3221 DataNode 3283 SecondaryNameNode 3364 Jps
3)啟動 YARN
[[email protected] hadoop-2.7.2]$ sbin/start-yarn.sh
注意:NameNode 和 ResourceManager 如果不是同一臺機器,不能在NameNode上啟動 YARN,應該在 ResourceManager 所在的機器上啟動 YARN。
4)web 端檢視 SecondaryNameNode
a、瀏覽器輸入:
b、檢視SecondaryNameNode,如圖
3、叢集基本測試
1)上傳檔案到叢集
上傳小檔案
[[email protected] hadoop-2.7.2]$ hdfs dfs -mkdir -p /user/atguigu/input [[email protected] hadoop-2.7.2]$ hdfs dfs -put wcinput/wc.input /user/atguigu/input
上傳大檔案
[[email protected] hadoop-2.7.2]$ bin/hadoop fs -put /opt/software/hadoop-2.7.2.tar.gz /user/atguigu/input
2)上傳檔案後檢視檔案存放在什麼位置
a、檢視HDFS檔案儲存路徑
[[email protected] subdir0]$ pwd /opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-938951106-192.168.10.107-1495462844069/current/finalized/subdir0/subdir0
b、檢視HDFS在磁碟儲存檔案內容
[[email protected] subdir0]$ cat blk_1073741825 hadoop yarn hadoop mapreduce jiangchun jiangchun
3)拼接
-rw-rw-r--. 1 hadoop hadoop 134217728 5月 23 16:01 blk_1073741836 -rw-rw-r--. 1 hadoop hadoop 1048583 5月 23 16:01 blk_1073741836_1012.meta -rw-rw-r--. 1 hadoop hadoop 63439959 5月 23 16:01 blk_1073741837 -rw-rw-r--. 1 hadoop hadoop 495635 5月 23 16:01 blk_1073741837_1013.meta [[email protected] subdir0]$ cat blk_1073741836>>tmp.file [[email protected] subdir0]$ cat blk_1073741837>>tmp.file [[email protected] subdir0]$ tar -zxvf tmp.file
4)下載
[[email protected] hadoop-2.7.2]$ bin/hadoop fs -get /user/atguigu/input/hadoop-2.7.2.tar.gz ./
七、叢集啟動/停止方式總結
1、各個服務元件逐一啟動/停止
1)分別啟動/停止 HDFS 元件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
2)啟動/停止 YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
2、各個模組分開啟動/停止 (前提是配置ssh)
1)整體啟動/停止 HDFS
start-dfs.sh / stop-dfs.sh
2)整體啟動/停止 YARN
start-yarn.sh / stop-yarn.sh
八、叢集時間同步
時間同步的方式:找一個機器作為時間伺服器,所有的機器與這臺叢集時間進行定時的同步,比如:每隔十分鐘,同步一次時間。

具體步驟:
1、時間伺服器配置(必須root使用者)
1)檢查 ntp 是否安裝
[[email protected] 桌面]# rpm -qa|grep ntp ntp-4.2.6p5-10.el6.centos.x86_64 fontpackages-filesystem-1.41-1.1.el6.noarch ntpdate-4.2.6p5-10.el6.centos.x86_64
2)修改 ntp 配置檔案
[[email protected] 桌面]# vi /etc/ntp.conf
修改內容如下:
a、修改1(授權 192.168.1.0-192.168.1.255 網段上的所有機器可以從這臺機器上查詢和同步時間)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap 為 restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b、修改2(叢集在區域網中,不使用其他網際網路上的時間)
server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst 為
#server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst
c、新增3(當該節點丟失網路連線,依然可以採用本地時間作為時間伺服器為叢集中的其他節點提供時間同步)
server 127.127.1.0 fudge 127.127.1.0 stratum 10
3)修改 /etc/sysconfig/ntpd 檔案
[[email protected] 桌面]# vim /etc/sysconfig/ntpd
增加如下內容(讓硬體時間與系統時間一起同步)
SYNC_HWCLOCK=yes
4)重啟 ntpd 服務
[[email protected] 桌面]# service ntpd status
ntpd 已停
[[email protected] 桌面]# service ntpd start
正在啟動 ntpd: [確定]
5)設定 ntpd 服務開機啟動
[[email protected] 桌面]# chkconfig ntpd on
2、其他機器配置(必須root使用者)
1)在其他機器配置 10 分鐘與時間伺服器同步一次
[[email protected]桌面]# crontab -e
編寫定時任務如下:
*/10 * * * * /usr/sbin/ntpdate hadoop102
2)修改任意機器時間
[[email protected]桌面]# date -s "2017-9-11 11:11:11"
3)十分鐘後檢視機器是否與時間伺服器同步
[[email protected]桌面]# date 說明:測試的時候可以將10分鐘調整為1分鐘,節省時間