
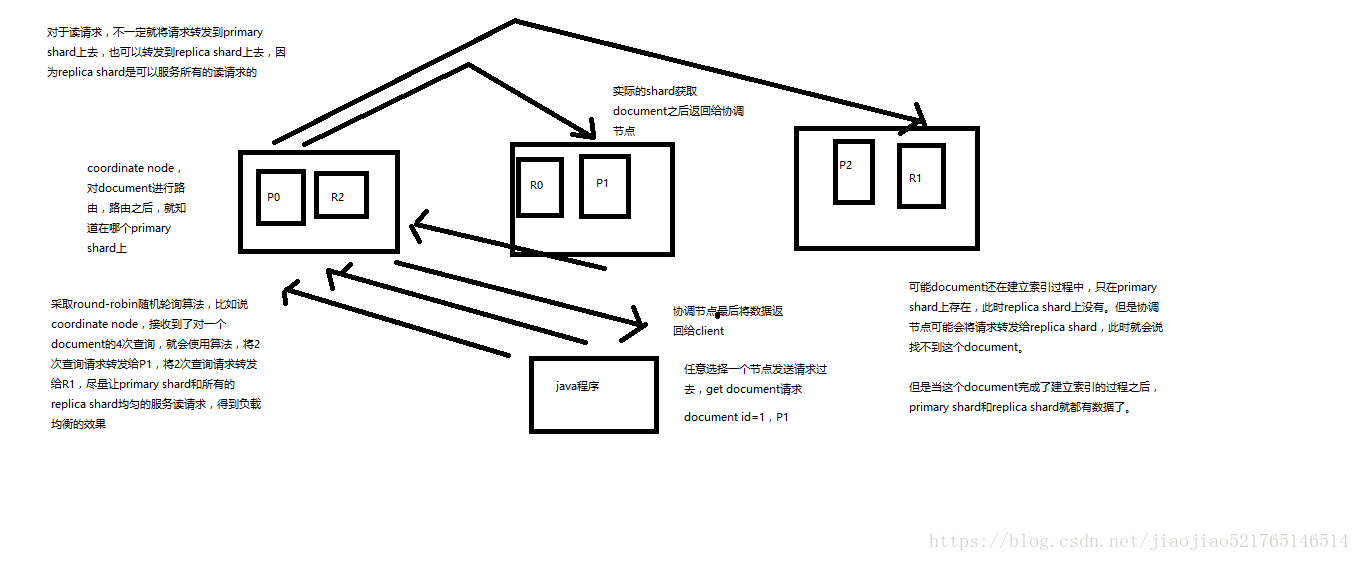
ES:document查詢內部原理揭祕
1、客戶端傳送請求到任意一個node,成為coordinate node
2、coordinate node對document進行路由,將請求轉發到對應的node,此時會使用round-robin隨機輪詢演算法,在primary shard以及其所有replica中隨機選擇一個,讓讀請求負載均衡
3、接收請求的node返回document給coordinate node
4、coordinate node返回document給客戶端
5、特殊情況:document如果還在建立索引過程中,可能只有primary shard有,任何一個replica shard都沒有,此時可能會導致無法讀取到document,但是document完成索引建立之後,primary shard和replica shard就都有了
相關推薦
ES:document查詢內部原理揭祕
1、客戶端傳送請求到任意一個node,成為coordinate node 2、coordinate node對document進行路由,將請求轉發到對應的node,此時會使用round-robin隨機輪詢演算法,在primary shard以及其所有replica中隨機選擇一個,讓讀請求負載
ElasticSearch最佳入門實踐(三十一)document查詢內部原理揭祕
1、客戶端傳送請求到任意一個node,成為coordinate node 對於讀請求,不一定所有的請求都發送的primary shard 上去,也可以轉發到replied shard 上去,因為replied shard 也是可以服務所有讀請求的 2、coordin
ES:document增刪改內部原理揭祕
1、路由演算法:shard = hash(routing) % number_of_primary_shards 這裡是引用決定一個document在哪個shard上,最重要的一個值就是routing值,預設是_id,也可以手動指定,相同的routing值,每次過來,從hash
ElasticSearch最佳入門實踐(二十九)document增刪改內部原理揭祕
步驟 (1)客戶端選擇一個node傳送請求過去,這個node就是coordinating node(協調節點) (2)coordinating node,對document進行路由,將請求轉發給對應的node(有primary shard) (3)實際的node上的prima
分布式文檔系統_document查詢內部原理
沒有 OS coord 負載均衡 請求 其他 pri 過程 nod 1、客戶端發送請求到任意一個node,成為coordinate node2、coordinate node對document進行路由,將請求轉發到對應的node,此時會使用round-robin隨機輪詢算法
Mybatis最入門---分頁查詢(內部原理篇)
public class DefaultParameterHandler implements ParameterHandler { private final TypeHandlerRegistry typeHandlerRegistry; private final MappedStateme
Oracle遞歸查詢的原理
turn mes span msu mit from ams evel ims 在Oracle 10g下。來到scott用戶下。分別以層次 1,2,3,4上的節點做實驗: 當start with是根節點(level=1),要查其子節點,connect
Hbase(五) hbase內部原理
當前 times filter 提高 恢復 數據 是否 最後一行 地址 一、系統架構 客戶端連接hbase依賴於zookeeper,hbase存儲依賴於hadoop client: 1、包含訪問 hbase 的接口, client 維護著一些 cache(
ES中查詢相關
api ast str article bsp htm category blog http elasticsearch中的API:http://www.cnblogs.com/yjf512/p/4862992.html elasticsearch查詢系列:http
JVM 內部原理
sig 計算 jvm tar java lan 操作 本地 follow 1、JVM的組成: JVM 由類加載器子系統、運行時數據區、執行引擎以及本地方法接口組成。 2、JVM的運行原理: JVM是java的核心和基礎,在java編譯器和os平臺之間的虛擬處理器。它是一種
Storm集群上的開發 ,Storm的內部原理,storm提交任務的過程 (八)
啟動 監控 task 技術 自己 storm集群 src images nbsp storm提交任務的過程: 1.客戶端通過storm提交topology 2.nimbus主節點創建本地topology任務目錄。tmp 3.nimbus監控zookeeper心跳,計算工作量
java泛型 泛型的內部原理:類型擦除以及類型擦除帶來的問題
st2 往裏面 避免 我們 lar 屬於 util get 驚奇 一、Java泛型的實現方法:類型擦除 前面已經說了,Java的泛型是偽泛型。為什麽說Java的泛型是偽泛型呢?因為,在編譯期間,所有的泛型信息都會被擦除掉。正確理解泛型概念的首要前提是理解類型擦出(type
ES Document API之多文檔API
tran ids gpo 結束 clust 即使 tle 返回 設置 多文檔API 多獲取API Get API #獲取一個類型的多個文檔,有多種API寫法,如下:#1curl -XGET ‘localhost:9200/_mget?pretty‘ -H ‘Conte
Android內核三大核心功能之一AMS內部原理
tasks tro com one 分析 itl dac chmod 重要 上面類是AmS的全稱,另外兩大核心功能是WindowManagerService.java和View.java AmS提供的主要功能: 統一調度各應用程序 內存管理 進程管理 AmS中定
Spark2.1內部原理剖析與源碼閱讀、程序設計與企業級應用案例
封裝 以及 url string 計算機網絡 內部原理 企業級 目標 sql 1、本文目標以及其它說明: 本文或者本次系列主要是弄清楚spark.2.2.0版本中,spark core 包下rpc通信情況。從源代碼上面看到,底層通信是用的netty,因為本系
Spark SQL / Catalyst 內部原理 與 RBO
apach extends extract park solution 速度 taf 數據存儲 nor 原創文章,轉載請務必將下面這段話置於文章開頭處。 本文轉發自技術世界,原文鏈接 http://www.jasongj.com/spark/rbo/ 本文所述內容均基
自定義RPC的完整實現---深入理解rpc內部原理
channel struct seek raise services utf-8 proto encode res 倘若不使用RPC遠端調用的情況下,代碼如下: local.py # coding:utf-8 # 本地調用除法運算的形式 class InvalidOper
HashMap 內部原理
HashMap 內部實現 通過名字便可知道的是,HashMap 的原理就是雜湊。HashMap內部維護一個 Buckets 陣列,每個 Bucket 封裝為一個 Entry<K, V> 鍵值對形式的連結串列結構,這個 Buckets 陣列也稱為表。表的索引是 金鑰K 的雜
泛型的內部原理:型別擦除以及型別擦除帶來的問題
轉載https://www.cnblogs.com/xll1025/p/6489088.html 1泛型擦除 1使用泛型的時候加上的型別引數,會在編譯器在編譯的時候去掉。這個過程就稱為型別擦除。 2原始型別名稱:刪去型別引數後的泛型型別名 3擦除型別變數後,並替換為限定型別(型別引數
ES:document的全量替換、強制建立以及圖解lazy delete機制
1、document的全量替換 (1)語法與建立文件是一樣的,如果document id不存在,那麼就是建立;如果document id已經存在,那麼就是全量替換操作,替換document的json串內容 PUT /test_index/test_type/4 { "test_fie