
[Spark]學習筆記
Spark是一個快速且通用的叢集計算框架
一、Spark的特點
1.Spark是快速的:
Spark擴充了流行的MapReduce計算框架
Spark是基於記憶體的計算
2.Spark是通用的:
Spark的涉及容納了其他分散式系統擁有的功能:批處理、迭代式計算、互動查詢和流處理等
其優勢是:降低了維護的成本
3.Spark是高度開放的:
Spark提供了Python、Java、Scala、SQL的API和豐富的內建庫
二、Spark的元件
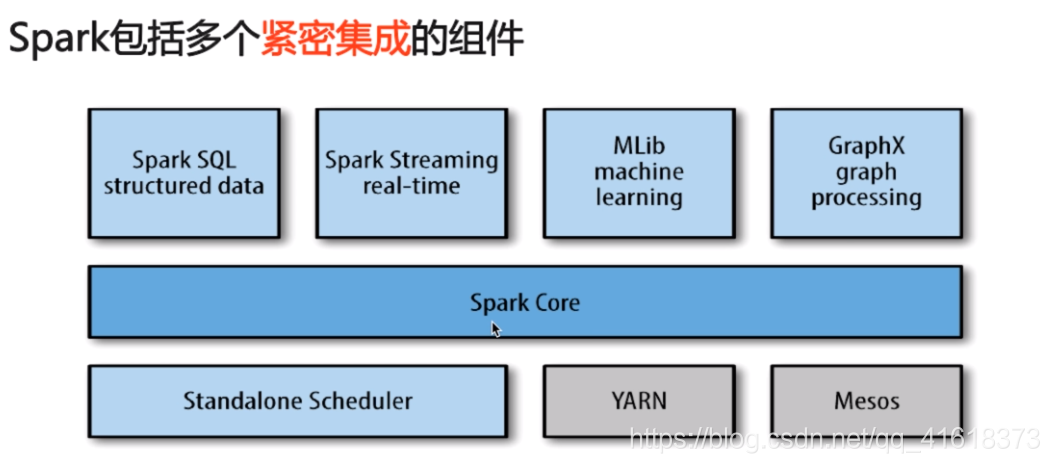
1.Spark core:
包含Spark的基本功能,包含任務排程,記憶體管理,容錯機制等
內部定義了RDDs
提供了很多APIs來建立和操作這些RDDs
應用場景:為其他元件提供底層服務
2.Spark SQL:
是Spark處理結構化資料的庫,就像Hive SQL,Mysql一樣
應用場景:企業中用來做報表的統計
3.Spark Streaming:
是實時資料流處理元件,類似Storm
Spark Streaming提供API來操作實時資料流
應用場景:企業中用來從kafka接受資料做實時統計
4.Mlib:–機器學習
5.Graphx:–處理圖
6.Cluster Managers:
就是叢集管理,Spark自帶一個叢集管理,是單獨排程器
常見的叢集內管理包括:Hadoop YARN,Apache Mesos
7.密集整合優點:
Spark底層優化了,基於Spark底層的元件,也得到了相應的優化
緊密整合,節省了各個元件組合使用時的部署,測試等時間
向Spark增加新的元件時,其他元件,可立刻享用新元件的功能
三、Spark與Hadoop的比較——應用場景的比較
1.Hadoop的應用場景:離線處理、對時效性要求不高
2.Spark的應用場景:時效性要求高的場景,機器學習等領域
3.比較:(中立的觀點)
這是一個生態系統,每個元件都有其作用,各善其職即可
Spark不具有HDFS的儲存功能,要藉助HDFS等持久化資料
大資料將會孕育除更多的新技術
四、通過命令列執行Spark——WordCount
1.啟動Spark:spark-shell --master local[2]
2.spark實現word count
1)讀取資料:var file=sc.textFile(“file:///home/hadoop/data/hello.txt”)
2)拆分每一行:var a=file.flatMap(line=>line.split(" "))
3)為每個單詞賦上1,用於計數:var b=a.map(word=>(word,1))
4)將相同單詞的計數加和:var c=b.reduceByKey(_ + _)
上述執行,可以通過下面這一條語句執行,得到相同的結果:
sc.textFile(“file:///home/hadoop/data/hello.txt”).flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_ + _).collect
五、通過idea寫好Spark程式,打包,在叢集上執行
1.在虛擬機器上使用Spark時,同樣需要配置ssh免密登陸,同hadoop的配置相同,每臺虛擬機器僅需要配置一次即可
2.寫好程式後,需要打成jar包,這裡介紹使用idea打jar包
file->project structure->artifacts->左上角加號->jar->選擇下面的那個->要打包的專案名->main class的名字->上面的選項是連依賴包一起打成jar包/下面的選擇是不包含依賴包->apply->ok
3.build->build artifacts->build
4.虛擬機器啊啟動master和worker:sbin目錄下執行:./start-all
5.把jar包copy到叢集上:idea上打好的jar包在output中
在C:\Users\PYN\IdeaProjects\scalatrain\out\artifacts\scalatrain_jar 下執行命令:scp scalatrain.jar [email protected]***.***.***.***:~/lib
6.提交,執行
在spark目錄下執行:
./bin/spark-submit --master local[2] --class com.scala.scala.com.spark.WordCount /home/hadoop/lib/scalatrain.jar