
實時計算 Flink效能調優
自動配置調優
實時計算 Flink新增自動調優功能autoconf。能夠在流作業以及上下游效能達到穩定的前提下,根據您作業的歷史執行狀況,重新分配各運算元資源和併發數,達到優化作業的目的。更多詳細說明請您參閱自動配置調優。
首次智慧調優
- 建立一個作業。如何建立作業請參看快速入門。
-
上線作業。選擇智慧推薦配置,指定使用CU數為系統預設,不填即可。點選下一步。

-
資料檢查,預估消耗CU數。
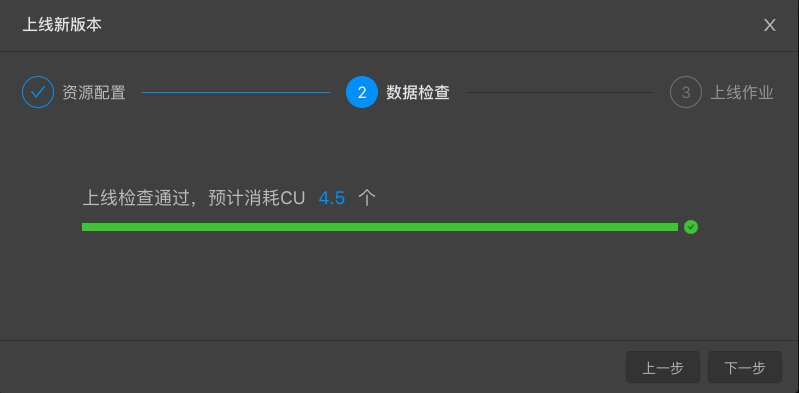
-
在運維介面啟動作業,根據實際業務需要指定讀取資料時間。
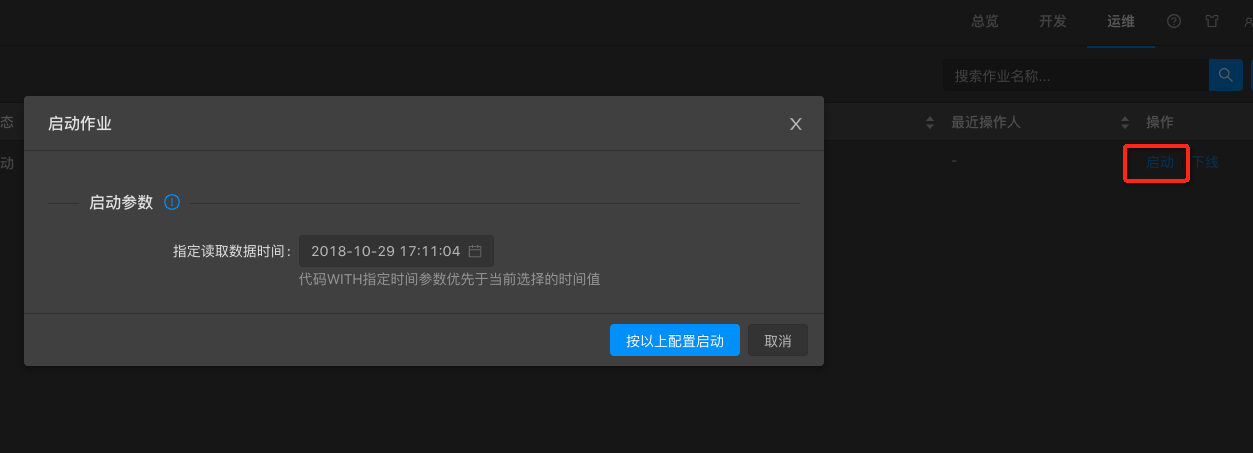
說明:實時計算作業啟動時候需要您指定啟動時間。實際上就是從源頭資料儲存的指定時間點開始讀取資料。指定讀取資料時間需要在作業啟動之前。例如,設定啟動時間為1小時之前。
-
待作業穩定執行10分鐘後,且以下狀態符合要求,即可開始下一次效能調優。
- 執行資訊拓撲圖中IN_Q不為100%。
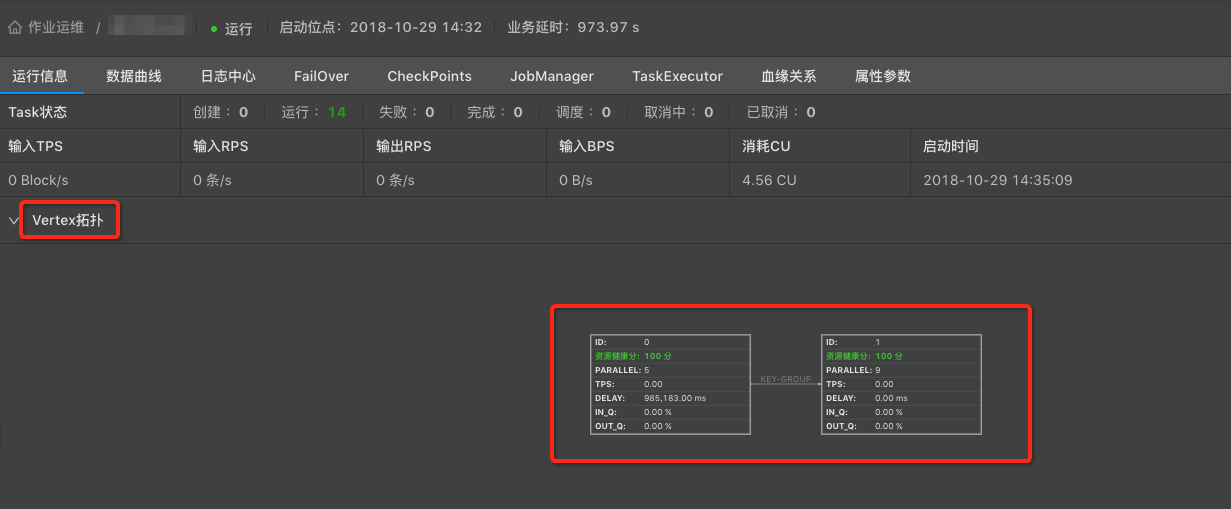
- 資料輸入RPS符合預期。

- 執行資訊拓撲圖中IN_Q不為100%。
非首次效能調優
-
停止>下線作業。

-
重新上線作業。選擇智慧推薦配置,指定使用CU數為系統預設,不填即可。點選下一步。
-
資料檢查,再次預估消耗CU數。
-
在運維介面啟動作業,待作業穩定執行十分鐘後,即可再一次效能調優。
說明:
- 自動配置調優一般需要3到5次才能達到理想的調優效果。請完成首次效能調優後,重複非首次效能調優過程多次。
- 每次調優前,請確保足夠的作業執行時長,建議10分鐘以上。
- 指定CU數(參考值) = 實際消耗CU數*目標RPS/當前RPS。
- 實際消耗CU數:上一次作業執行時實際消耗CU
- 目標RPS:輸入流資料的實際RPS(或QPS)
- 當前RPS:上一次作業執行時實際的輸入RPS
手動配置調優
手動配置調優可以分以下三個型別。
- 資源調優
- 作業引數調優
- 上下游引數調優
資源調優
資源調優即是對作業中的Operator的併發數(parallelism)、CPU(core)、堆記憶體(heap_memory)等引數進行調優。
分析定位資源調優節點
定位效能瓶頸節點
效能瓶頸節點為Vertex拓撲圖最下游中引數IN_Q值為100%的一個或者多個節點。如下圖,7號節點為效能瓶頸節點。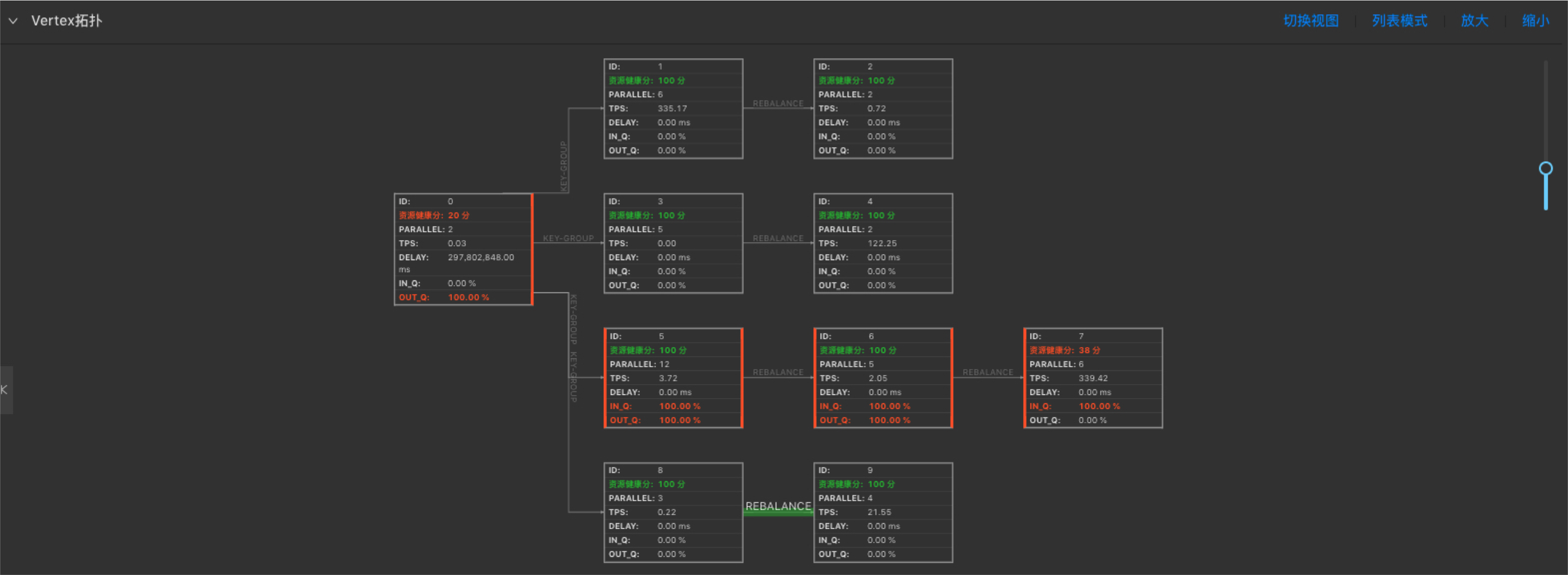
分析效能瓶頸因素
效能瓶頸的可分為三類。
- 併發(parallelism)不足
- CPU(core)不足
- MEM(heap_memory)不足
如下圖,7號節點的效能瓶頸是資源(CPU和/或MEM)配置不足所導致。
說明:判斷效能瓶頸因素方法
- 瓶頸節點的資源健康分為100,則認為資源已經合理分配,效能瓶頸是併發數不足所導致。
- 瓶頸節點的資源健康分低於100,則認為效能瓶頸是單個併發的資源(CPU和/或MEM)配置不足所導致。
- 無持續反壓,但資源健康分低於100,僅表明單個併發的資源使用率較高,但暫不影響作業效能,可暫不做調優。
通過作業運維頁面中Metrics Graph功能,進一步判斷效能瓶頸是CPU不足還是MEM不足。步驟如下。
-
運維介面中,點選TaskExecutor,找到效能瓶頸節點ID,點選檢視詳情。
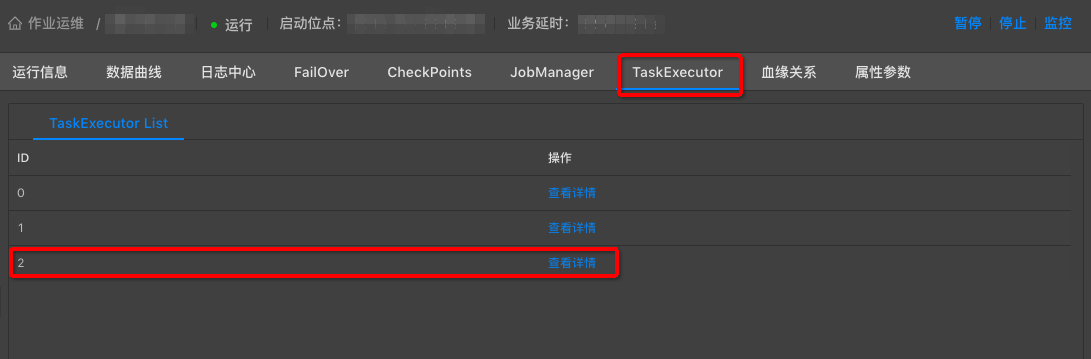
-
選擇Metrics Graph,根據曲線圖判斷CPU或者MEM是否配置不足(很多情況下兩者同時不足)。

調整資源配置
完成了效能瓶頸因素判斷後,點選開發>基本屬性>跳轉到新視窗配置,開始調整資源配置。
批量修改Operator
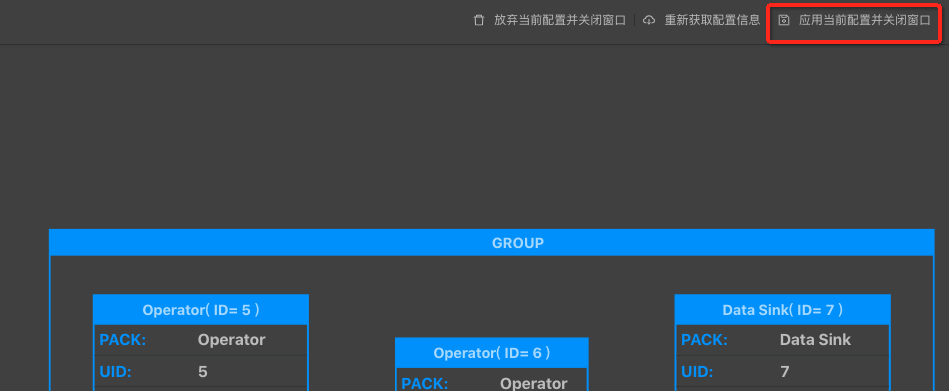
-
點選GROUP框,進入批量修改Operator資料視窗。

說明:
- GROUP內所有的operator具有相同的併發數。
- GROUP的core為所有operator的最大值。
- GROUP的_memory為所有operator之和。
- 建議單個Job維度的CPU:MEM=1:4,即1個核對應4G記憶體。
-
配置修改完成後點選應用當前配置並關閉視窗。
單個修改Operator
-
點選Operator框,進入修改Operator資料視窗。
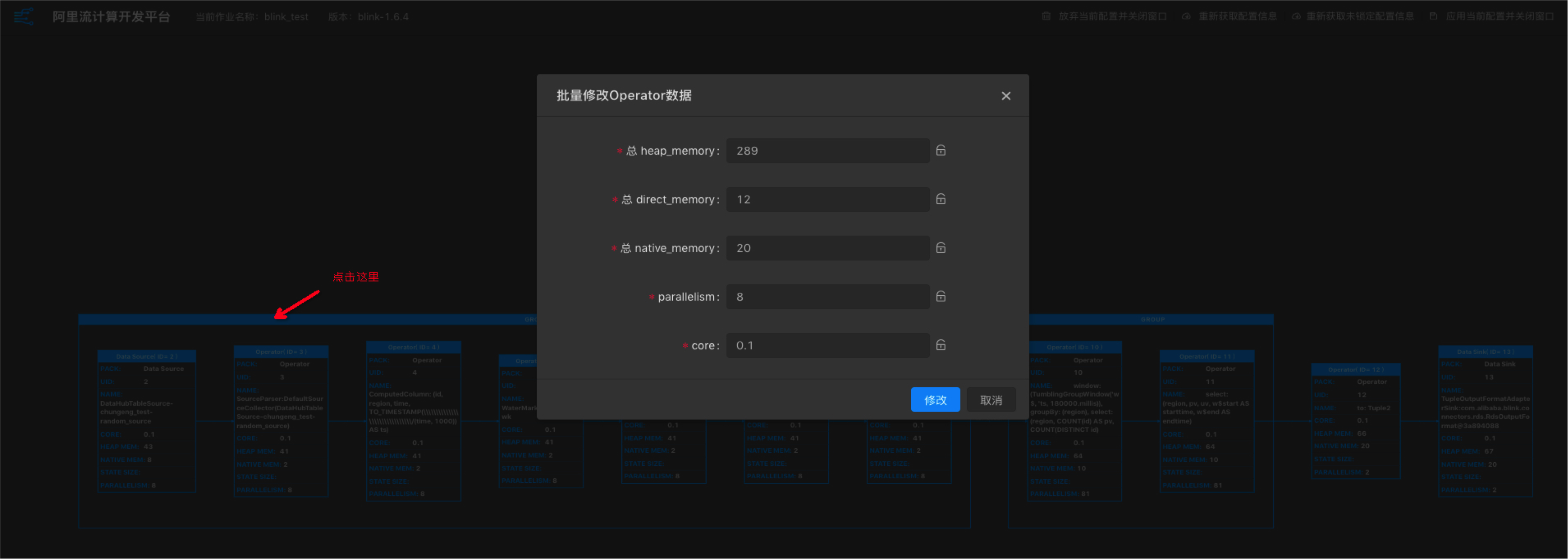
-
配置修改完成後點選應用當前配置並關閉視窗。
引數調整說明
您只需調整parallelism、core和heap_memory三個引數,即能滿足大部分的資源調優需求。
- Parallelism
- source節點
資源根據上游Partition數來。例如source的個數是16,那麼source的併發可以配置為16、8、4等。不能超過16。 - 中間節點
根據預估的QPS計算。對於資料量較小的任務,設定和source相同的併發度。QPS高的任務,可以配置更大的併發數,例如64、128、或者256。 - sink節點
併發度和下游儲存的Partition數相關,一般是下游Partition個數的2~3倍。如果配置太大會導致資料寫入超時或失敗。例如,下游sink的個數是16,那麼sink的併發最大可以配置48。
- source節點
- Core
即CPU,根據實際CPU使用比例配置,建議配置值為0.25,可大於1。 - Heap_memory
堆記憶體。根據實際記憶體使用狀況進行配置。 - 其他引數
- state_size:預設為0,group by、join、over、window等operator需設定為1。
- direct_memory:JVM堆外記憶體,預設值為0, 建議不要修改。
- native_memory:JVM堆外記憶體,預設值為0,建議修改為10MB。
- chainingStrategy:chain策略,根據實際需要修改。
作業引數調優
-
在開發頁面的右側選擇作業引數。
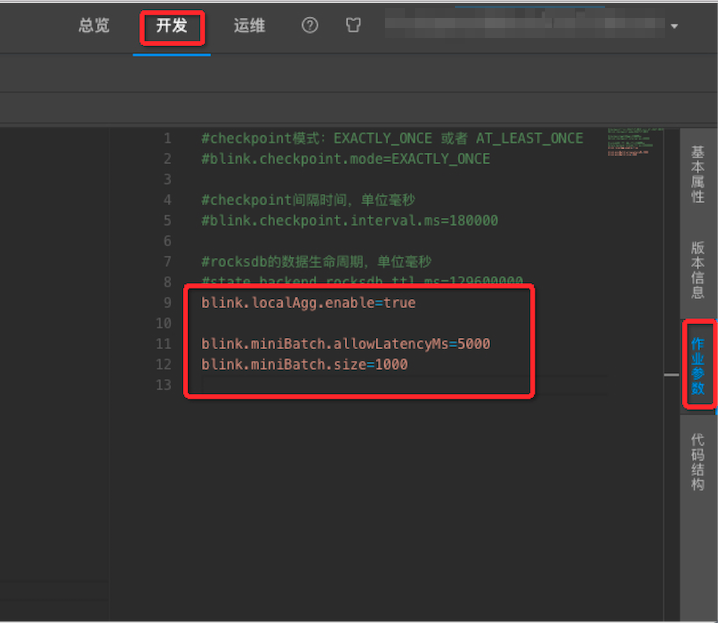
-
輸入調優語句。
| 優化 | 解決問題 | 調優語句 |
|---|---|---|
| MiniBatch | 提升吞吐,降低對下游壓力僅對Group by有效。 | blink.miniBatch.allowLatencyMs=5000blink.miniBatch.size=1000 |
| LocalGlobal | 優化資料傾斜問題 | blink.localAgg.enable=true |
| TTL | 設定State狀態時間 | 1.x:state.backend.rocksdb.ttl.ms=1296000002.x:state.backend.niagara.ttl.ms=129600000其中,1.x 表示需顯式開啟,2.x 表示預設開啟。 |
注意:新增或刪除MiniBatch或LocalGlobal引數,job狀態會丟失,修改值大小狀態不會丟失。
上下游引數調優
實時計算 Flink可以在with引數內設定相應的引數,達到調優上下游儲存效能的目的。
調優步驟:
- 進入作業的開發介面。
- 確定需要調優的上下游引用表的語句。
- 在with引數中配置相應的調優引數。如下圖。

batchsize引數調優
實時計算 Flink的每條資料均會觸發上下游儲存的讀寫,會對上下游儲存形成效能壓力。可以通過設定batchsize,批量的讀寫上下游儲存資料來降低對上下游儲存的壓力。
| 名字 | 引數 | 詳情 | 設定引數值 |
|---|---|---|---|
| Datahub源表 | batchReadSize | 單次讀取條數 | 可選,預設為10 |
| Datahub結果表 | batchSize | 單次寫入條數 | 可選,預設為300 |
| 日誌服務源表 | batchGetSize | 單次讀取logGroup條數 | 可選,預設為10 |
| ADB結果表 | batchSize | 每次寫入的批次大小 | 可選,預設為1000 |
| RDS結果表 | batchSize | 每次寫入的批次大小 | 可選,預設為50 |
注意: 新增、修改或者刪除以上引數後,作業必須停止-啟動後,調優才能生效。
cache引數調優
| 名字 | 引數 | 詳情 | 設定引數值 |
|---|---|---|---|
| RDS維表 | Cache | 快取策略 | 預設值為None,可選LRU、ALL。 |
| RDS維表 | cacheSize | 快取大小 | 預設值為None,可選LRU、ALL。 |
| RDS維表 | cacheTTLMs | 快取超時時間 | 預設值為None,可選LRU、ALL。 |
| OTS維表 | Cache | 快取策略 | 預設值為None, 可選LRU,不支援ALL。 |
| OTS維表 | cacheSize | 快取大小 | 預設值為None, 可選LRU,不支援ALL。 |
| OTS維表 | cacheTTLMs | 快取超時時間 | 預設值為None, 可選LRU,不支援ALL。 |
注意: 新增、修改或者刪除以上引數後,作業必須停止-啟動後,調優才能生效。
手動配置調優流程
- 資源調優、作業引數調優、上下游引數調優
- 開發上線作業
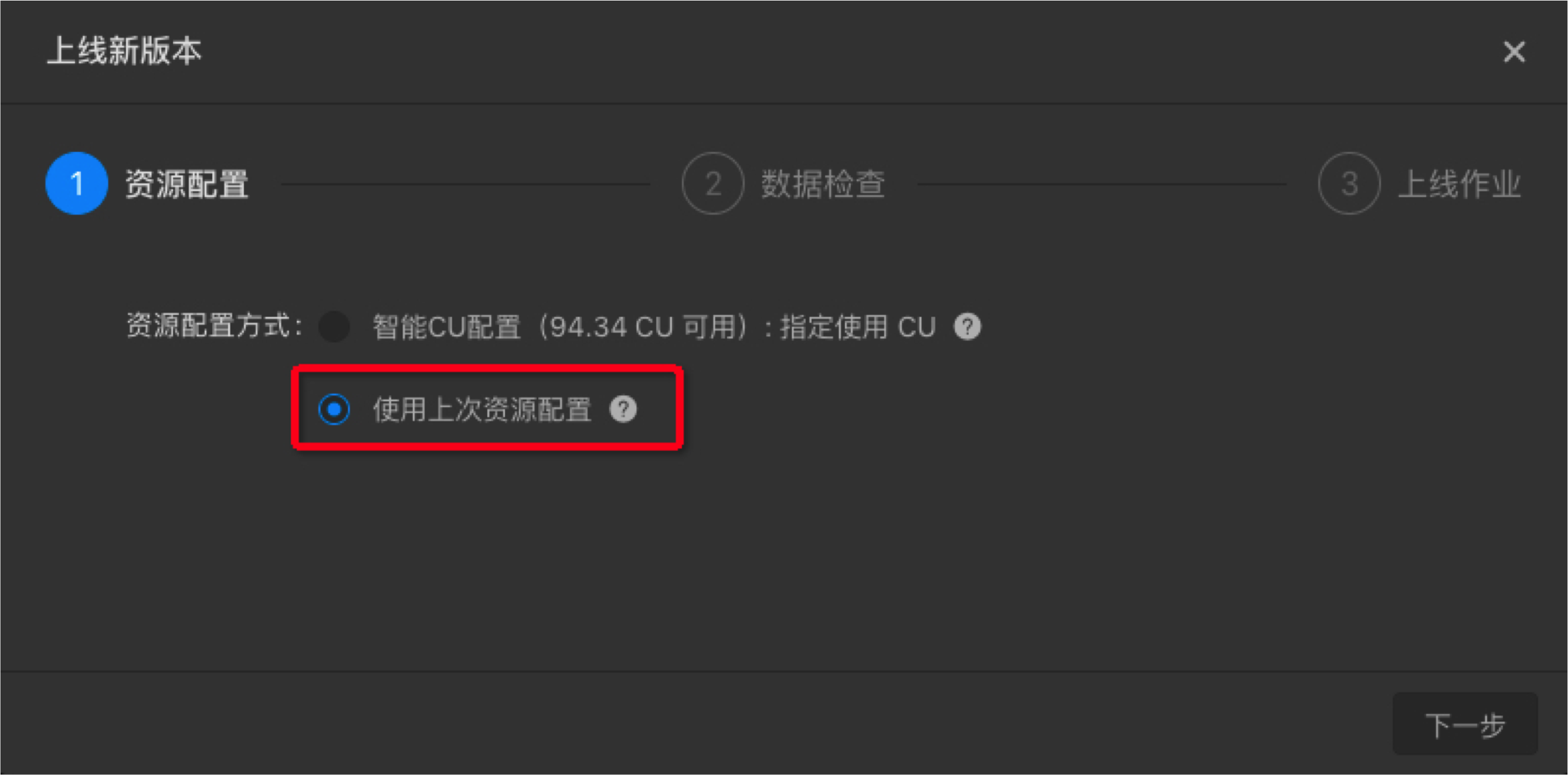
- 資源配置方式:使用上次資源配置
- 資料檢查
- 上線
說明:完成資源、作業引數、上下游引數調優後,手動配置調優後續的步驟與自動配置調優基本一致。區別在於資源配置環節需要選擇使用上次資源配置。
FAQ
Q:效能調優後作業為什麼執行不起來?
A:可能性1:首次自動配置時指定了CU數,但指定的CU數太小(比如小於自動配置預設演算法的建議值,多見於作業比較複雜的情況),建議首次自動配置時不指定CU數。
可能性2:預設演算法建議的CU數或指定的CU數超過了專案當前可用的CU數,建議擴容。
Q:Vertex拓撲中看不到持續反壓,但延遲卻非常大,為什麼?
A:可能性1:若延時直線上升,需考慮是否上游source中部分partition中沒有新的資料,因為目前delay統計的是所有partition的延時最大值。 自動配置調優
實時計算 Flink新增自動調優功能autoconf。能夠在流作業以及上下游效能達到穩定的前提下,根據您作業的歷史執行狀況,重新分配各運算元資源和併發數,達到優化作業的目的。更多詳細說明請您參閱自動配置調優。
首次智慧調優
建立一個作業。如何建立作業請參看快速入門。
上線作業
最近完成了一個雲端計算平臺應用的架構調優。客戶是一個 Wordpress + MySQL 的站點,剛從本地資料中心遷移到了 AWS,由於團隊技能限制,無法充分發揮雲端計算的優勢。加之應用程式在夜間高流量時段崩潰,架構優化和遷移迫在眉睫。本文以這次架構遷移經驗為例,介紹雲端計算架構優化遷移的基本步驟和
介紹
Optimization Overview 優化概述
Optimizing SQL Statements 優化SQL語句
Optimization and Indexes 優化和索引
Optimizing Database Structure 優化資料庫結
深入理解Java虛擬機器總結一虛擬機器效能監控工具與效能調優(三)
JDK的命令列工具
JDK的視覺化工具
效能調優
JDK的命令列工具
主要有以下幾種:
jps (Java Process Status Tool): 虛擬機器程序
1. 分配資源調優
Spark效能調優的王道就是分配資源,即增加和分配更多的資源對效能速度的提升是顯而易見的,基本上,在一定範圍之內,增加資源與效能的提升是成正比的,當公司資源有限,能分配的資源達到頂峰之後,那麼才去考慮做其他的調優
如何分配及分配哪些資源
在生產環境中,提交spark作 此文已由作者張洪簫授權網易雲社群釋出。
歡迎訪問網易雲社群,瞭解更多網易技術產品運營經驗。
問題描述
隨著考拉業務的增長和規模的擴大,很多的應用都開始重度依賴快取服務,也就是杭研的nkv。但是在使用過程中,發現服務端壓力並不是特別大的情況下,客戶端的rt卻很高,導致應用在到達一定併發的情況下,服務的質量下降的 https://blog.csdn.net/defonds/article/details/52598018
多次拉取 JStack,發現很多執行緒處於這個狀態: at jrockit/vm/Allocator.getNewTla(JJ)V(Native Method)
一、 Hadoop概述
隨著企業要處理的資料量越來越大,MapReduce思想越來越受到重視。Hadoop是MapReduce的一個開源實現,由於其良好的擴充套件性和容錯性,已得到越來越廣泛的應用。
Hadoop實現了一個分散式檔案系統(Hadoop Distributed File Sys
最近因為學習原因,eclipse中外掛越來越多,造成eclipse一次次假死,著實很影響工作效率和心情,有時正是興起,但是造成短片很令人生氣,如果eclipse卡頓或者假死,在電腦配置較不錯的情況下,不要懷疑自己的電腦,嘗試去除錯一下自己的eclipse。
找到eclipse或
監控
nginx有自帶的監控模組,編譯nginx的時候,加上引數 --with-http_stub_status_module
#配置指令
./configure --prefix=/usr/local
--user=nginx
--group=nginx
tomcat優化的我用到的幾個點:
1.記憶體優化
2.執行緒優化 docs/config/http.html
maxConnections
acceptCount(配置的太大是沒有意義的)
maxThreads
minSpareThreads 最小空閒的工作
技巧#1:確定MySQL的最大連線數
對於MySQL的最大連線數,一次最好是傳送5個請求到Web伺服器。對Web伺服器的5個請求中的一部分將用於CSS樣式表,影象和指令碼等資源。由於諸如瀏覽器快取等原因,要獲得準確的MySQL到Web伺服器的請求比率可能很困難; 要想得到一個確切的數字,就需要分
1.優化Linux核心及TCP連線
編輯系統配置檔案:
vim /etc/sysctl.conf
修改內容如下:
配置
說明
fs.file-max = 655350
系統檔案描述符
現實企業級Java開發中,有時候我們會碰到下面這些問題:
OutOfMemoryError,記憶體不足
記憶體洩露
執行緒死鎖
鎖爭用(Lock Contention)
Java程序消耗CPU過高
......
&n 總結一下spark的調優方案:
一、效能調優
1、效能上的調優主要注重一下幾點:
Excutor的數量
每個Excutor所分配的CPU的數量
每個Excutor所能分配的記憶體量
Driver端分配的記憶體數量
2、如何分配資源
在生產環境中,
Nginx可以快取一些檔案(一般是靜態檔案),減少Nginx與後端伺服器的IO,提高使用者訪問速度。而且當後端伺服器宕機時,Nginx伺服器能給出相應的快取檔案響應相關的使用者請求。
一 Nginx靜態快取基本配置
在tomcat的webapps目錄下建立hello.html,內容 效能概述
看懂程式的效能
一般來說,程式的效能能通過以下幾個方面來表現:
執行速度:程式的反映是否迅速,響應時間是否足夠短
記憶體分配:記憶體分配是否合理,是否過多地消耗記憶體或者存在洩漏
啟動時間:程式從執行到可以正常處理業務需要花費多長時間
負責承受能力:當系統壓力上升時,系統的執
一、GC概要:
JVM堆相關知識 為什麼先說JVM堆? JVM的堆是Java物件的活動空間,程式中的類的物件從中分配空間,其儲存著正在執行著的應用程式用到的所有物件。這些物件的建立方式就是那些new一類的操作,當物件 一、對於資料傾斜的發生一般都是一個key對應的資料過大,而導致Task執行過慢,或者記憶體溢位(OOM),一般是發生在shuffle的時候,比如reduceByKey,groupByKey,sortByKey等,容易產生資料傾斜。
那麼針對資料傾斜我們如何解決呢?我們可以首先觀看log日誌,以為log日誌報 本文將從Redis的基本特性入手,通過講述Redis的資料結構和主要命令對Redis的基本能力進行直觀介紹。之後概覽Redis提供的高階能力,並在部署、維護、效能調優等多個方面進行更深入的介紹和指導。
本文適合使用Redis的普通開發人員,以及對Redis進行選型、架構設計和效能調優的架構設計人員。
&n
可能性2:Vertex拓撲中看不到持續反壓,那麼效能瓶頸點可能出現在source節點。因為source節點沒有輸入快取佇列,即使有效能問題,IN_Q也永遠為0(同樣,sink節點的OUT_Q也永遠為0)。
解決方案:通過手動配置調優,將source節點(GROUP)中的operator中chainingStrategy修改為HEAD,將其從GROUP中拆解出來。然後上線執行後再看具體是哪個節點是效能瓶頸節點,若依然看不到效能瓶頸節點,則可能是因為上游source吞吐不夠,需考慮增加source的batchsize或增加上游source的shard數。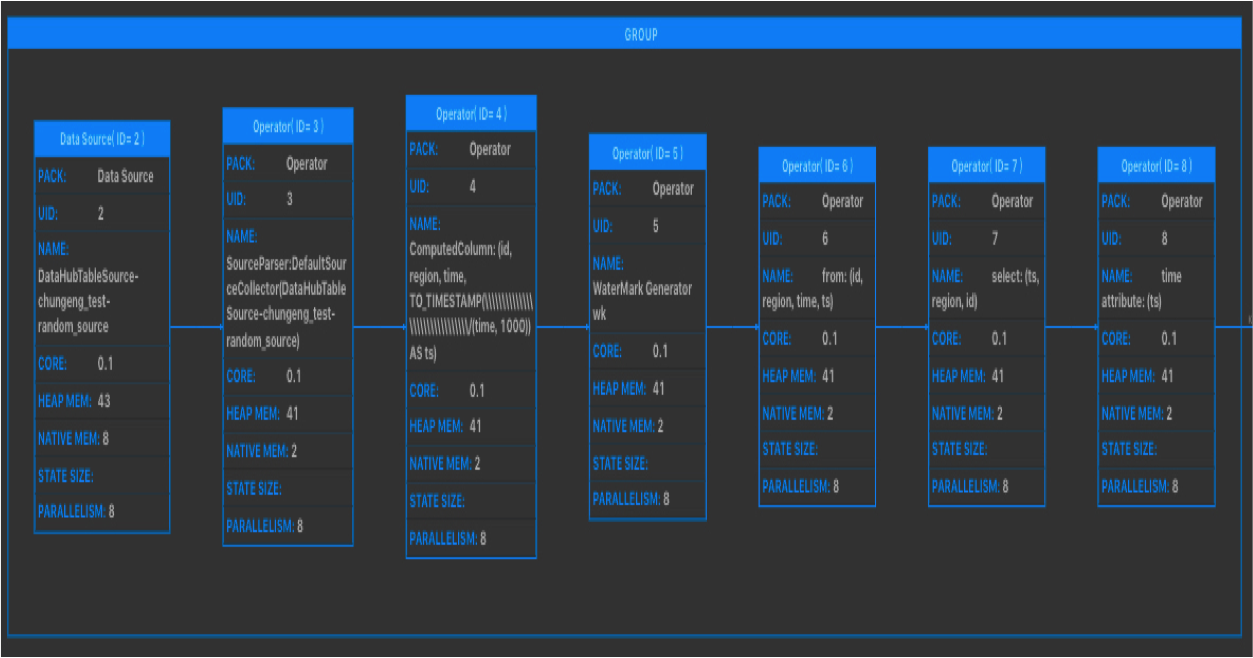
相關推薦
實時計算 Flink效能調優
雲端計算生產環境架構效能調優和遷移套路總結(以 AWS 為例)
1.效能調優概覽
深入理解Java虛擬機器總結一虛擬機器效能監控工具與效能調優(三)
【Big Data 每日一題】Spark開發效能調優總結
nkv客戶端效能調優
ifeve.com 南方《JVM 效能調優實戰之:使用阿里開源工具 TProfiler 在海量業務程式碼中精確定位效能程式碼》
Hadoop效能調優全面總結
eclipse效能調優的一次記錄
nginx監控與效能調優
Tomcat效能調優以及遠端管理(Tomcat manager與psi-probe監控)
MySQL 效能調優技巧
Tomcat8 效能調優
JVM效能調優監控工具jps、jstack、jstat、jmap、jinfo使用
Spark之效能調優總結(一)
Nginx效能調優之快取記憶體
第一章 Java效能調優概述
JVM 垃圾回收機制與GC效能調優
大資料之效能調優方面(資料傾斜、shuffle、JVM等方面)
Redis 基礎、高階特性與效能調優