吳恩達老師機器學習筆記異常檢測(一)
阿新 • • 發佈:2018-11-05
明天就要開組會了,天天在辦公室划水都不知道講啥。。。
今天開始異常檢測的學習,同樣程式碼比較簡單一點
異常檢測的原理就是假設樣本的個特徵值都呈高斯分佈,選擇分佈較離散的樣本的作為異常值。這裡主要注意的是通過交叉驗證對閾值的選擇和F1score的應用。
原始資料:
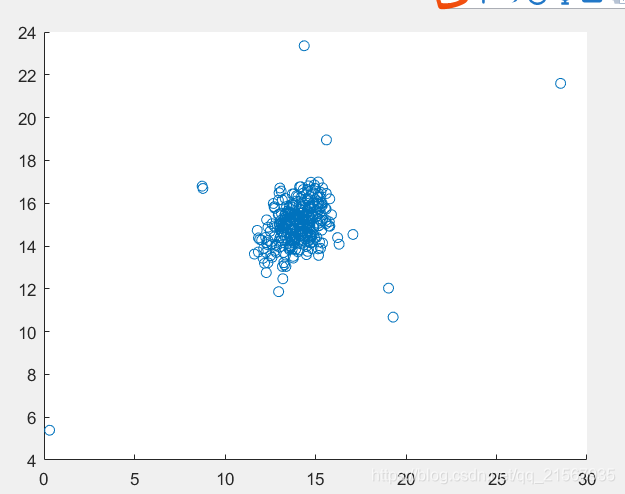
程式碼如下:
load('ex8data1.mat'); [m n]=size(X); X_mean=mean(X); theta=(sum((X-X_mean).^2))./m; % 用無標籤樣本建立高斯分佈模型 P=exp(-(Xval-X_mean).^2./(theta.*2).^2).*(1./sqrt(theta.*pi.*2)); P=prod(P,2); F1_best=0; % F1score越大,模型越穩健 for e=0:0.001:0.3 % 通過對有標籤樣本交叉驗證選取合適的閾值 P(:,2)=(P(:,1)<e); c=P(:,2)+yval; tp=sum(c==2); % 計算異常樣本正確分類的數量 c=P(:,2)-yval; fp=sum(c==1); % 計算把正確樣本劃分為錯誤樣本的數量 fn=sum(c==-1); % 計算把錯誤樣本劃分為正確樣本的數量 prec=tp/(tp+fp); % 計算精確度 rec=tp/(tp+fn); % 計算召回率 F1=2*prec*rec/(prec+rec); % 計算F1score if F1_best<F1 F1_best=F1; e_best=e; end end P(:,2)=(P(:,1)<e_best); scatter(Xval(:,1),Xval(:,2),8,P(:,2),'filled');
最後結果如下:

後面第二個多維資料的練習就懶得做了,如果正式做的記得要平均分配好交叉訓練集和驗證集。
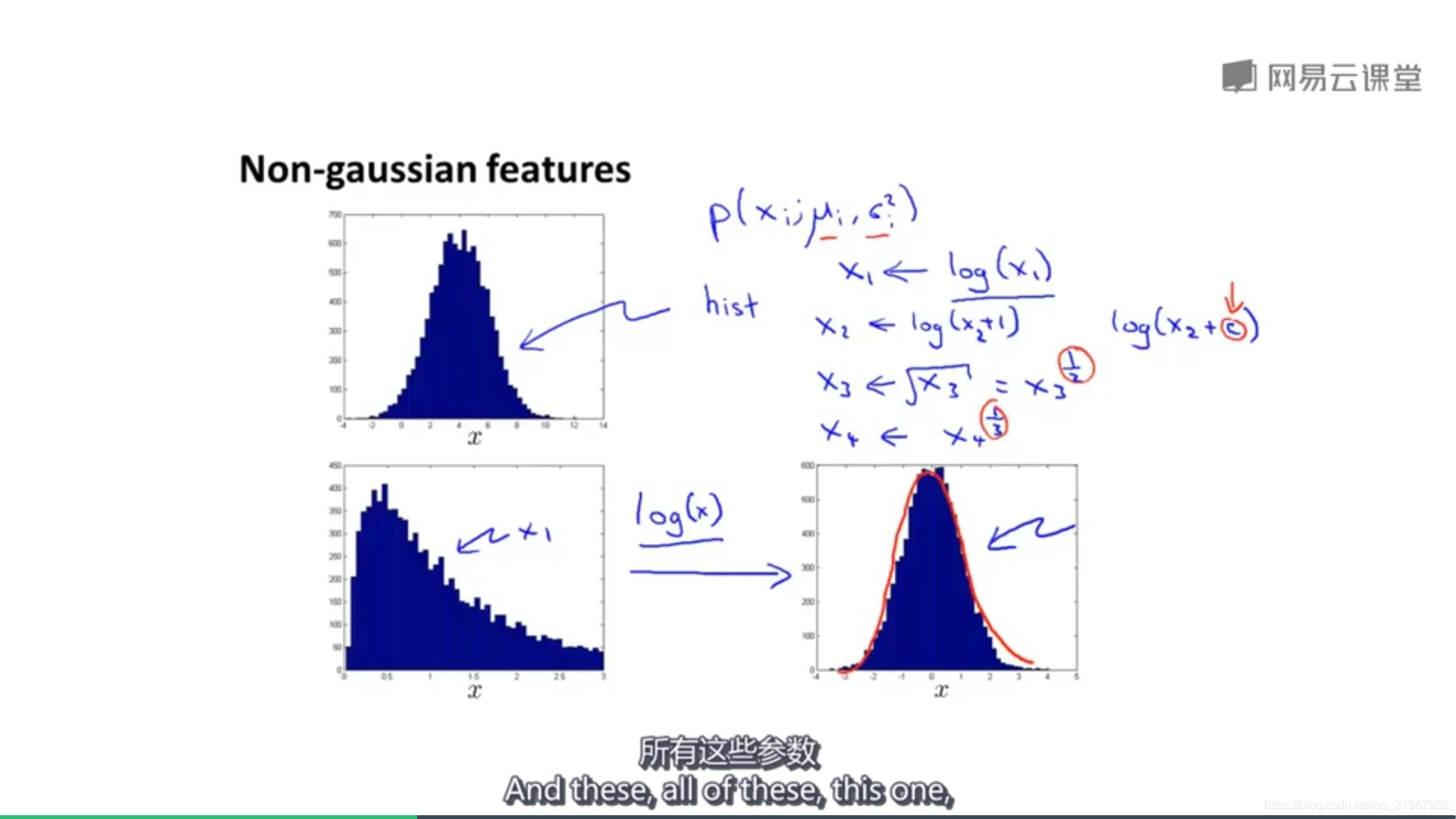
Optional:如果資料並不是很明顯的呈高斯分佈,可以通過log(x)或者x^0.3之類的函式來讓資料呈明顯高斯分佈。