
吳恩達老師機器學習筆記SVM(二)
今天的部分是利用高斯核函式對分佈稍微複雜一點的資料進行分類
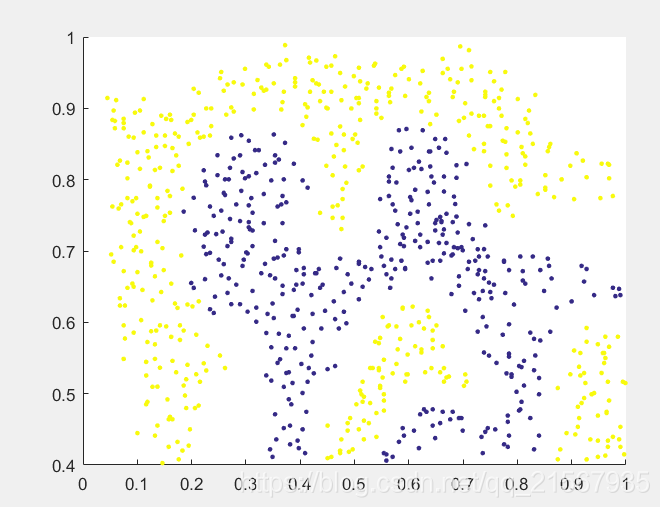
這裡的高斯核函式是構建新的特徵,該特徵是關於到其餘所有樣點的歐式距離。

下面放出程式碼:
load('ex6data2.mat'); [m n]=size(X); f=zeros(m,m); a=0.005 for i=1:m Xp=X(i,:); Xp=repmat(Xp,m,1); Xp=exp(-sum((Xp-X).^2,2)./(2*a)); f(i,:)=Xp'; end C=1000; theta=rand(m,1); for i=1:1000 % 擬合次數 theta=theta-(((f).*(f*theta>=-1))'*(1-y)+((-f).*(f*theta<=1))'*y); end sum((1-y).*(f*theta>=-1)+y.*(f*theta<=1)) % 檢查分類錯誤樣本數
這裡的a比較關鍵,相當於放縮不同距離的權重,影響著最後的分類精度。
不太瞭解這個圖是怎麼畫出來的:
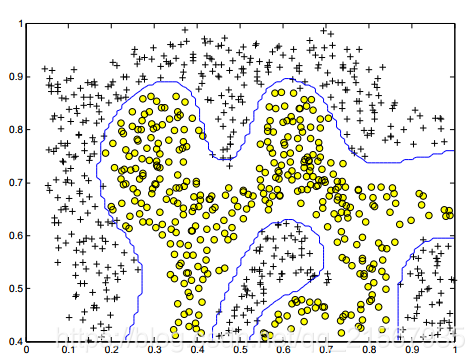
統計最後分類的錯誤樣本數量為0。以後有時間會再鑽研鑽研怎麼畫出來的。
(程式碼如果一時半會找不到錯誤,可以先放放,過幾天再看看的說~)
相關推薦
吳恩達老師機器學習筆記SVM(二)
今天的部分是利用高斯核函式對分佈稍微複雜一點的資料進行分類 這裡的高斯核函式是構建新的特徵,該特徵是關於到其餘所有樣點的歐式距離。 下面放出程式碼: load('ex6data2.mat'); [m n]=size(X); f=zeros(m,m); a=0.005 for i=
吳恩達老師機器學習筆記SVM(一)
時隔好久沒有再拾起機器學習了,今日抽空接著學 今天是從最簡單的二維資料分類開始學習SVM~ (上圖為原始資料) SVM的代價函式 這裡套用以前logistic迴歸的模板改一下下。。 load('ex6data1.mat'); theta=rand(3,1); [
吳恩達老師機器學習筆記異常檢測(一)
明天就要開組會了,天天在辦公室划水都不知道講啥。。。 今天開始異常檢測的學習,同樣程式碼比較簡單一點 異常檢測的原理就是假設樣本的個特徵值都呈高斯分佈,選擇分佈較離散的樣本的作為異常值。這裡主要注意的是通過交叉驗證對閾值的選擇和F1score的應用。 原始資料: 程式碼如下:
吳恩達老師機器學習筆記主成分分析PCA
接著學習主成分分析,這個演算法在之前計量地理學的作業裡寫過,不過前者稍微囉嗦了一點。 原始二維資料: 放程式碼: load('ex7data1.mat'); [m n]=size(X); X=(X-mean(X))./std(X); sigma=1/m*(X'*X); % 求取協
吳恩達老師機器學習筆記K-means聚類演算法(二)
運用K-means聚類演算法進行影象壓縮 趁熱打鐵,修改之前的演算法來做第二個練習—影象壓縮 原始圖片如下: 程式碼如下: X =imread('bird.png'); % 讀取圖片 X =im2double(X); % unit8轉成double型別 [m,n,z]=size
吳恩達老師機器學習筆記K-means聚類演算法(一)
今天接著學習聚類演算法 以後堅決要八點之前起床學習!不要浪費每一個早晨。 K-means聚類演算法聚類過程如下: 原理基本就是先從樣本中隨機選擇聚類中心,計算樣本到聚類中心的距離,選擇樣本最近的中心作為該樣本的類別。最後某一類樣本的座標平均值作為新聚類中心的座標,如此往復。 原
吳恩達老師機器學習筆記異常檢測(二)
明天就要開組會了,天天在辦公室划水都不知道講啥。。。 今天開始異常檢測的學習,同樣程式碼比較簡單一點 異常檢測的原理就是假設樣本的個特徵值都呈高斯分佈,選擇分佈較離散的樣本的作為異常值。這裡主要注意的是通過交叉驗證對閾值的選擇和F1score的應用。 原始資料:
寫吳恩達老師機器學習課時使用scipy.optimize.fmin_cg結果出現問題
訓練完成提示: Warning: Desired error not necessarily achieved due to precision loss. Current function value: 原因是我前邊的def computeCost(m
<吳恩達老師深度學習筆記二>第一周,深度學習介紹(未完待續)
神奇 建立 網絡筆記 1.3 展示 定義 信息 英語 輸出 摘要: 本篇博客僅作為筆記,如有侵權,請聯系,立即刪除(網上找博客學習,然後手記筆記,因紙質筆記不便保存,所以保存到網絡筆記)。 1.1 歡迎 深度學習常常運用於:讀取X光圖像、個性化教育、精準化農業、駕駛
<吳恩達老師深度學習筆記二>第一週,深度學習介紹(未完待續)
摘要: 本篇部落格僅作為筆記,如有侵權,請聯絡,立即刪除(網上找部落格學習,然後手記筆記,因紙質筆記不便儲存,所以儲存到網路筆記)。 1.1 歡迎 深度學習常常運用於:讀取X光影象、個性化教育、精準化農業、駕駛汽車等領域。深度學習處於AI分支中,學習如何建立神經網路(包含一個深度神經網路),以及如
spark機器學習筆記:(二)用Spark Python進行資料處理和特徵提取
下面用“|”字元來分隔各行資料。這將生成一個RDD,其中每一個記錄對應一個Python列表,各列表由使用者ID(user ID)、年齡(age)、性別(gender)、職業(occupation)和郵編(ZIP code)五個屬性構成。4之後再統計使用者、性別、職業和郵編的數目。這可通過如下程式碼
吳恩達老師深度學習視訊課筆記:構建機器學習專案(機器學習策略)(1)
機器學習策略(machine learning strategy):分析機器學習問題的方法。 正交化(orthogonalization):要讓一個監督機器學習系統很好的工作,一般要確保四件事情,如下圖: (1)、首先,你通常必須確保至少系
Coursera 深度學習 吳恩達 deep learning.ai 筆記整理(3-2)——機器學習策略
新的 bsp 誤差 spa 歸納 空間 font 處理 整理 一、誤差分析 定義:有時我們希望算法能夠勝任人類能做的任務,但是當算法還沒達到人類所預期的性能時,人工檢查算法錯誤會讓你知道接下來做什麽,這也就是誤差分析 檢查,發現會把夠狗當恒,是否需要做一個項目專門處理狗
深度學習,周志華,機器學習,西瓜書,TensorFlow,Google,吳軍,數學之美,李航,統計學習方法,吳恩達,深度學習筆記,pdf下載
1. 機器學習入門經典,李航《統計學習方法》 2. 周志華的《機器學習》pdf 3.《數學之美》吳軍博士著pdf 4. Tensorflow 實戰Google深度學習框架.pdf 5.《TensorFlow實戰》黃文堅 高清完整PDF 6. 復旦大
吳恩達新書-機器學習學習筆記-(四)學習曲線
1.診斷偏差與方差:學習曲線 學習曲線可以將開發集的誤差與訓練集樣本的數量進行關聯比較。想要繪製出它,你需要設定不同大小的訓練集執行演算法。假設有1000個樣本,你可以選擇在規模為100、200、300、····1000的樣本集中分別執行演算法,接著便能得到開發集誤差隨訓練
吳恩達新書-機器學習學習筆記-(五)與人類表現水平對比
1.為何與人類表現水平進行對比 許多機器學習系統的設計目的是想要自動化處理一些人類可以處理得很好的事情。可舉的例子有影象識別、語音識別以及垃圾郵件分類等等。學習演算法進步如此之快,有許多類似任務的處理已經超過了人類的表現水平。 有很多理由表明在處理人類擅長的任務時,構建一
吳恩達《機器學習》課程筆記——第一章:緒論 初識機器學習
【重要提示】:本人機器學習課程的主要學習資料包括:吳恩達教授的機器學習課程和黃廣海博士的中文學習筆記。感謝吳恩達教授和黃廣海博士的知識分享和無私奉獻。作為機器學習小白,計劃每週末記錄一週以來的學習內容,總結回顧。希望大家多多挑錯,也願我的學習筆記能幫助到有需要的人。 1.1 什麼是機器學習 卡內基梅隆大學
吳恩達Coursera機器學習課程筆記-單變數線性迴歸
The Hypothesis Function we will be trying out various values of θ0 and θ1 to try to find values which provide the best possibl
吳恩達《機器學習》課程筆記
class 關於 閱讀全文 多變量 第一章 title 知識 代數 ref 吳恩達《機器學習》課程筆記 吳恩達《機器學習》課程筆記——第五章:Matlab/Octave教程 摘要: 這一章的內容比較簡單,主要是MATLAB的一些基礎教程,
吳恩達《機器學習》課程總結(7)正則化
額外 分享 哪些 TP 回歸 分享圖片 表現 例子 兩個 7.1過擬合的問題 訓練集表現良好,測試集表現差。魯棒性差。以下是兩個例子(一個是回歸問題,一個是分類問題) 解決辦法: (1)丟棄一些不能幫助我們正確預測的特征。可以使用工選擇保留哪些特征,或者使用一些模型選擇