
GraphQL和RESTful的區別
GraphQL和RESTful的區別
http://graphql.cn/learn/
https://www.cnblogs.com/Wolfmanlq/p/9094418.html
前面提到GraphQL可以理解為基於RESTful的一種封裝,目的在於構建使Client更加易用的服務,可以說GraphQL是更好的RESTful設計。在過去的十多年中,REST已經成為設計web api的標準(雖然只是一個模糊的標準)。它提供了一些很棒的想法,比如無狀態伺服器和結構化的資源訪問。然而REST api表現得過於僵化,無法跟上訪問它們的客戶的快速變化的需求。 GraphQL的開發是為了應付更多的靈活性和效率,它解決了與REST api互動時開發人員所經歷的許多缺點和低效之處。 為了說明在從API獲取資料時REST和GraphQL之間的主要區別,讓我們考慮一個簡單的示例場景:在blog應用程式中,應用程式需要顯示特定使用者的文章的標題。同一螢幕還顯示該使用者最後3個關注者的名稱。REST和GraphQL如何解決這種情況?
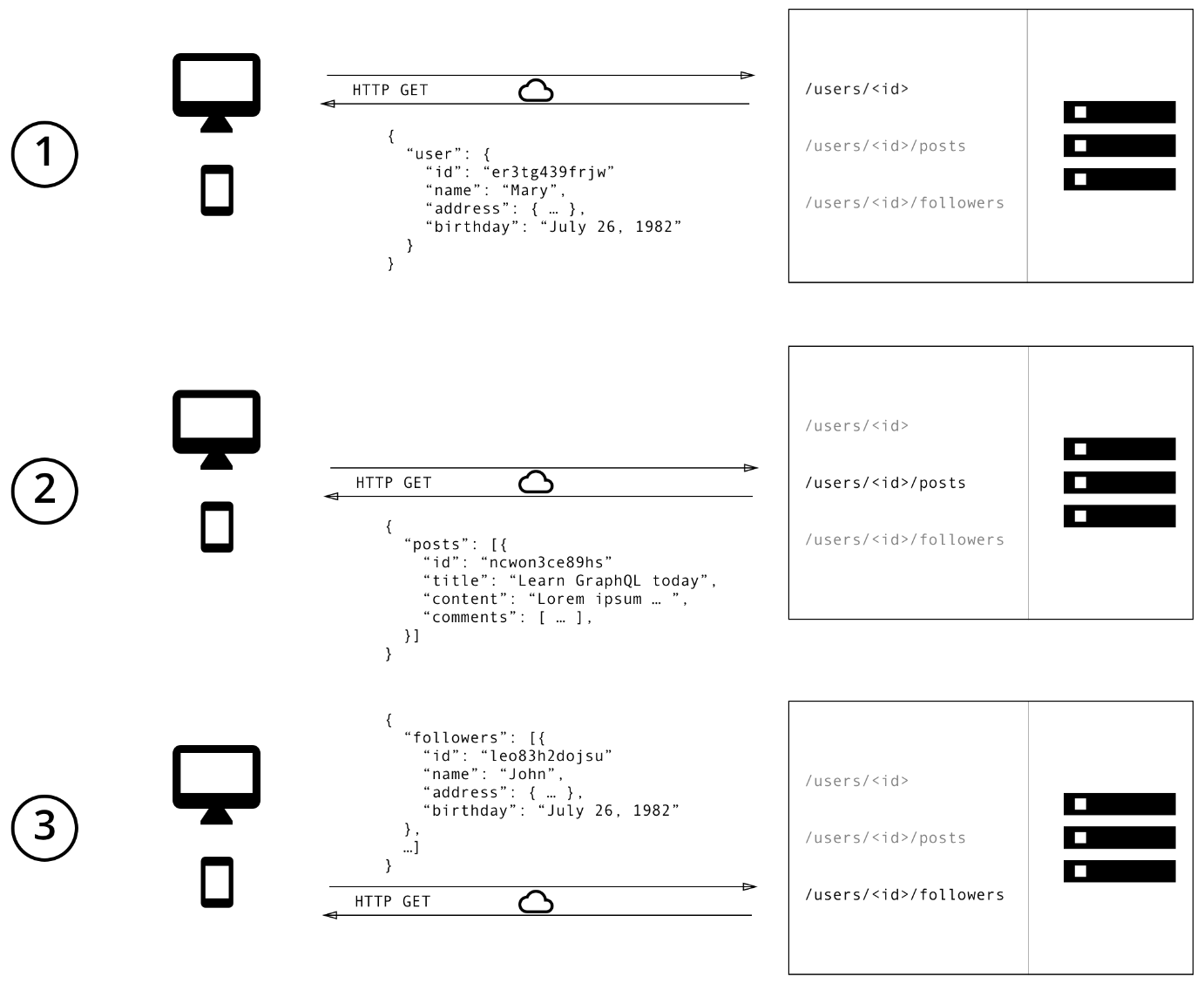
使用REST API來現實時,我們通常可以通過訪問多次請求來收集資料。比如在這個示例中,我們可以通過下面的三步來實現:
通過 /user/
獲取初始使用者資料 通過/user/
/posts 返回使用者的所有帖子 請求/user/
/followers,返回每個使用者的關注者列表
呼叫關係如下圖所示:
如果用GraphQL的話,我們只需要一次請求就可以完成上述的需求
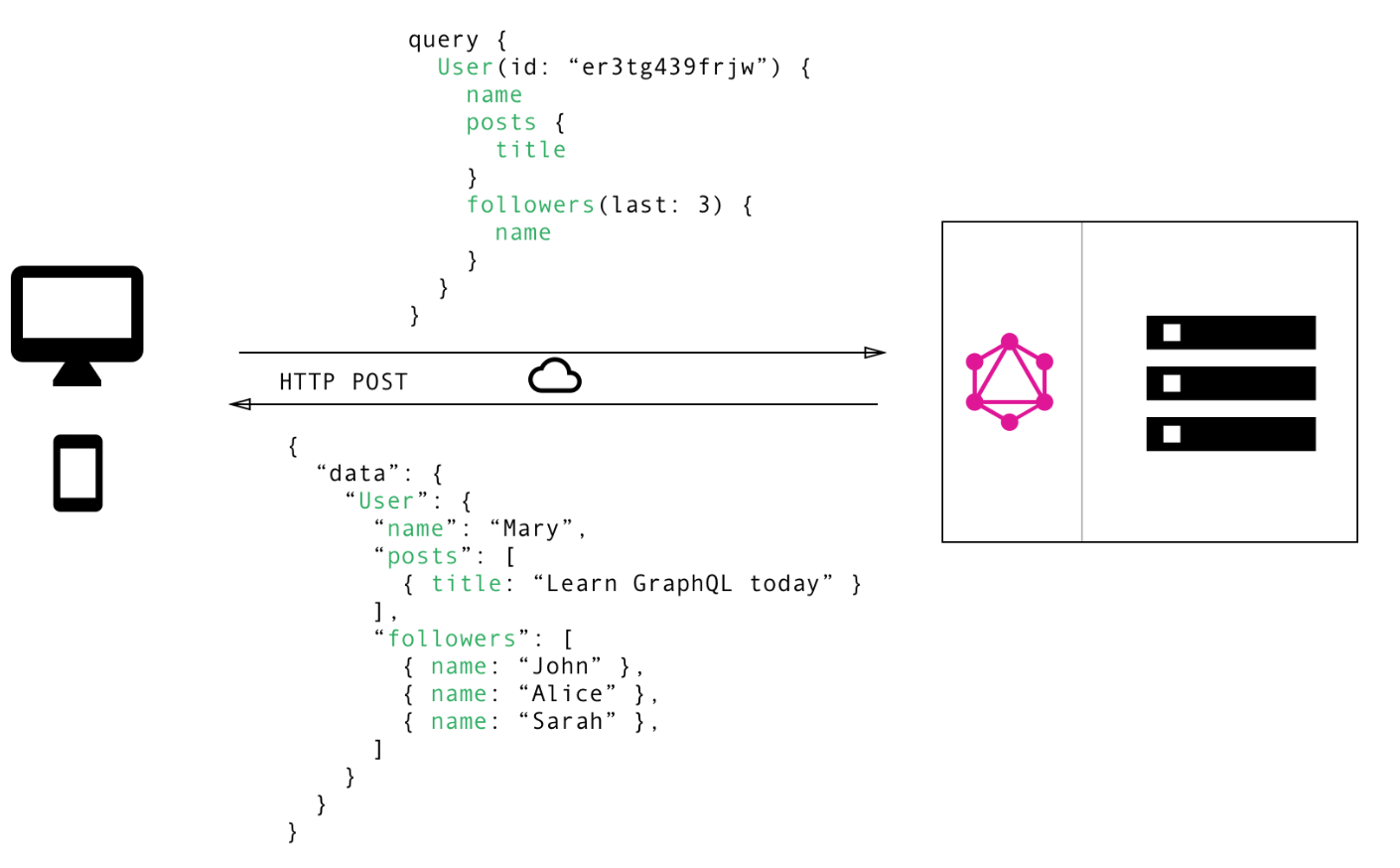
在GraphQL的世界裡我們不用多取資料,也不用擔心資料取少了,我們只需要按需獲取即可。
REST最常見的問題之一是API的返回資料過多或者過少,這是因為客戶端下載資料的唯一方法是通過訪問返回固定資料結構的endpoint,這就會導致我們設計API非常困難,因為它既要能夠為客戶提供精確的資料需求,又需要滿足不同調用者的需求,這本身就是相互矛盾的。GraphQL的發明者Lee Byron提出了一個很重要的概念: “用圖形來思考,而不是endpoint”
通過上述直觀展示我們可以得出一下幾點:
- 獲取了許多多餘的資料
通常情況下我們在呼叫一個通用API介面時,客戶端獲取的資訊比應用程式中實際需要的要多。例如UI需要顯示一個使用者列表,而實際上只需要使用他們的名字。在REST API中通常會呼叫 /user 這個endpoint,並接收一個帶有使用者資料的JSON陣列。但是這個響應可能包含更多關於返回的使用者的資訊,例如他們的生日或地址,而這些資訊對客戶來說是無用的,因為它只需要顯示使用者的名字。
- 獲取的資料少於Client所需要的資料
一般來說資料獲取不足意味著某個特定的endpoint 沒有提供客戶端需要的足夠資訊,客戶端將需要額外的請求來獲取它所需要的一切。這可能會升級到客戶端需要首先獲取列表資訊,然後需要對單條資料新增一個額外的請求以獲取其他所需的資料,例如考慮其他Client 也需要顯示每個使用者的最後三個關注者,該API提供了額外的endpoint /user/
- 前端的快速產品迭代對API有很大的挑戰
REST api的一個常見模式是根據您在應用程式內部的展現邏輯來構造endpoint,這很方便,因為它允許客戶端通過訪問相應的endpoint獲取特定檢視的所有所需資訊。 這種方法的主要缺點是它不允許前端的快速迭代。對於UI所做的每一個更改,現在都存在比以前更多(或更少)的資料的高風險。因此,需要對後端進行調整,以滿足新的資料需求,這會降低生產力並顯著降低將使用者反饋整合到產品中的能力。 使用GraphQL這個問題就解決了。由於GraphQL的靈活性,無需在伺服器上額外工作就可以在客戶端上進行更改。由於客戶端可以指定準確的資料需求,所以當前端的設計和資料需求發生變化時,並不需要後端API做出任何的修改就可以滿足展現層的變化。
- Schema和型別系統的好處
GraphQL使用強大的Type System來定義API的功能。所有在API中公開的型別都是使用GraphQL schema Definition Language (SDL)在模式中編寫的。該模式充當客戶端和伺服器之間的契約,以定義客戶機如何訪問資料。 一旦定義了模式,在前端和後端工作的團隊就可以在沒有進一步通訊的情況下完成工作,因為他們都知道通過網路傳送的資料的確切結構。 前端團隊可以通過mock所需的資料結構來輕鬆測試他們的應用程式。一旦後端API實現完成,就可以對客戶端應用程式進行切換來呼叫實際的API獲取資料,這也可以使得我們實現更好的客戶端和服務端的分離。
寫在最後
我們可以看出GraphQL的出現可以使得我們後端API具有更大的靈活性以及擴充套件性以滿足不同client對資料的需要,這大大豐富了API的資料提供的能力。
GraphQL是一種新的API標準,它提供了一種更高效、強大和靈活的資料提供方式。它是由Facebook開發和開源,目前由來自世界各地的大公司和個人維護。GraphQL本質上是一種基於api的查詢語言,現在大多數應用程式都需要從伺服器中獲取資料,這些資料儲存可能儲存在資料庫中,API的職責是提供與應用程式需求相匹配的儲存資料的介面。有的人經常把GraphQL和資料庫技術相混淆,這是一個誤解,GraphQL是api的查詢語言,而不是資料庫。從這個意義上說,它是資料庫無關的,而且可以在使用API的任何環境中有效使用,我們可以理解為GraphQL是基於API之上的一層封裝,目的是為了更好,更靈活的適用於業務的需求變化。 GraphQL出現的歷史背景
當提起API設計的時候,大家通常會想到SOAP,RESTful等設計方式,從2000年RESTful的理論被提出的時候,在業界引起了很大反響,因為這種設計理念更易於使用者的使用,所以便很快的被大家所接受。我們知道REST是一種從伺服器公開資料的流行方式。當REST的概念被提及出來時,客戶端應用程式對資料的需求相對簡單,而開發的速度並沒有達到今天的水平。因此REST對於許多應用程式來說是非常適合的。然而在業務越發複雜,客戶對系統的擴充套件性有了更高的要求時,API環境發生了巨大的變化。特別是從下面三個方面在挑戰api設計的方式:
1.移動端使用者的爆發式增長需要更高效的資料載入
Facebook開發GraphQL的最初原因是移動使用者的增加、低功耗裝置和鬆散的網路。GraphQL最小化了需要網路傳輸的資料量,從而極大地改善了在這些條件下執行的應用程式。
2.各種不同的前端框架和平臺
前端框架和平臺執行客戶端應用程式的異構環境使得我們在構建和維護一個符合所有需求的API變得困難,使用GraphQL每個客戶機都可以精確地訪問它需要的資料。
3.在不同前端框架,不同平臺下想要加快產品快速開發變的越來越難
持續部署已經成為許多公司的標準,快速的迭代和頻繁的產品更新是必不可少的。對於REST api,伺服器公開資料的方式常常需要修改,以滿足客戶端的特定需求和設計更改。這阻礙了快速開發實踐和產品迭代。
GraphQL的出現不僅僅是針對開發人員的,Facebook在2012年開始在其native mobile apps中使用GraphQL。但有趣的是GraphQL大部分都是在web技術的背景下使用的,並且在native mobile 領域中只得到很少的支援。 Facebook第一次公開談論GraphQL是在宣佈開源計劃後不久的2015年React峰會的時候。因為Facebook總是在React的背景下談GraphQL,所以對於沒有React經驗的開發人員來說,要理解GraphQL並不是一種僅限於React使用的技術可能還需要一段時間。即便是在這樣的背景下誕生的GraphQL依然是一個快速增長的社群 ,事實上GraphQL是一種技術,可以在客戶端與API通訊的任何地方使用。有趣的是Netflix和Coursera等其他公司都在研究類似的想法以提高API的互動效率。Coursera設想了一種類似的技術,可以讓客戶指定其資料需求,而Netflix甚至將其解決方案稱為Falcor。在GraphQL被開源之後,Coursera完全停止了他們在Falcor上的努力,並轉到了GraphQL的學習上。目前已經有很多的公司在使用GraphQL(https://graphql.org/users/)。