
hadoop-2.7.6 完全分散式的安裝
準備環境
CentOS 7
jdk1.8 (這裡建議使用1.8版本的jdk 連結:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)
hadoop-2.7.3.tar.gz ( 連結:http://mirrors.hust.edu.cn/apache/hadoop/)
機器環境
使用三臺機器搭建hadoop叢集,其中一臺為Master,兩臺為Slave1.Slave2; (搭建叢集的機器數量最好為奇數,包括master)
這裡我們準備三臺機器,來搭建一個小型hadoop分散式叢集,分別是 master(主節點),slave1,slave2 。
三臺機器IP 如下:
- 192.168.1.106
- 192.168.1.105
- 192.168.1.104
三臺機器在叢集中的作用:
master 擔任 NameNode、DataNode、ResourceManager、NodeManager
slave1 擔任 DataNode、NodeManager
slave2 擔任 DataNode、NodeManager
hadoop環境準備
設定主機名

開啟後ins進入編輯模式 輸入主機名 master;同理 slave步驟也一樣 (我這裡已經設定好了)
Esc :wq! 儲存退出
這裡需要重啟 主機名生效
設定IP與主機名對映

進入編輯IP與主機名對映
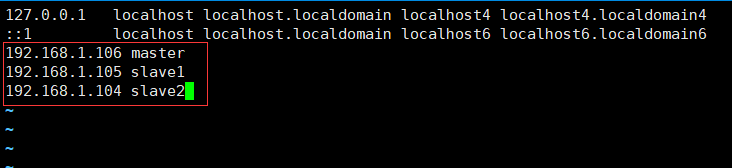
# 這裡 三臺機器都要需要此操作
#這裡 注意 IP與主機名之間 應有一個空格
在之後新增叢集 則需要在 /etc/hosts中新增對映關係 並且分發個各個叢集
關閉防火牆
systemctl stop firewalld.service
systemctl disable firewalld.service

配置ssh免密登入
叢集之間的機器需要相互通訊,所以我們必須先配置免密碼登入。在三臺機器上都得配置免密。(每臺機器都需要配置)

以 rsa 演算法生成金鑰。連續按四個空格,有yes輸入yes
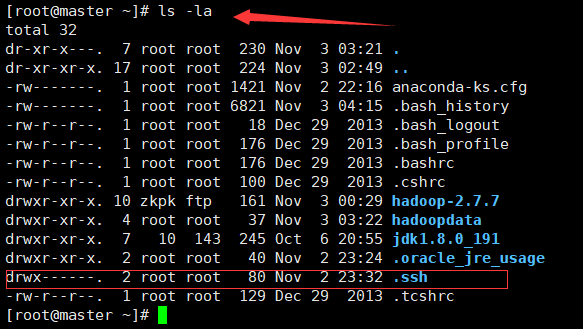
完成之後 ls -la 檢視當前隱藏檔案
看到一個 .ssh 的檔案 這就是剛才生成的 存放金鑰的資料夾
有.ssh 說明你金鑰已經生成成功了!!!
cd .ssh cd 進去之後可以看到有兩個檔案

id_rsa 為私鑰
id_rsa.pub 為公鑰
known_hosts 進行記錄連結到對方時,對方給的host key進行簡單的驗證 (首次建立免密且沒有任何連結的 是沒有這個檔案)
給金鑰新增許可權:
chmod 600 ~/.ssh/authorized_keys

複製公鑰檔案 給 authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys (首次建立免密且沒有任何連結的 是沒有這個檔案)
#注意 檔案明必須是 這個名稱!!!
按照以上步驟 把slave1, slave2 ,的 公鑰 拷貝到 authorized_keys 檔案中。(這裡只有一個authorized_keys檔案,且內容包括 master,slave1,slave2,的公鑰)
把三臺機器的公鑰拷貝給 authorized_keys 後。分發給各個slave
scp ~/.ssh/authorized_keys [email protected]:~/ (同理分發給 slave1,slave2 ,)
驗證是否 免密成功
以下操作在主節點master上
ssh master(此步驟是驗證master是否給master免密成功)
ssh slave1
ssh slave2



出現這種情況表明ssh免密成功
exit 退出當前使用者

安裝jdk
上傳jdk安裝包到 Linux 上 (參考軟體 Xshell 等)
解壓 jdk
tar -zxvf jdk-8u152-linux-x64.tar.gz (解壓到當前目錄下)
配置環境變數

vi /etc/profile 開啟後再最後加上一下幾句話:
export JAVA_HOME=/root/usr/java/jdk1.8.0_152
export PATH=$JAVA_HOME/bin:$PATH

使用source /etc/profile讓profile檔案立即生效。

輸入 java 命令測試是否完成
如出現以下情況 則完成環境的安裝:
輸入 java -version 來驗證,如出現以下則為成功:

輸入 jps
出現 jps則成功
hadoop安裝
下載hadoop-2.7.3.tar.gz 解壓
tar -zxvf hadoop-2.7.3.tar.gz (解壓到當前目錄)
cd 到Hadoop目錄下
cd hadoop-2.7.3/etc/hadoop/

配置環境變數 hadoop-env.sh
進入Hadoop目錄下
ls 檢視 檔案

vi hadoop-env.sh
開啟後在檔案靠前的一部分找到
export JAVA_HOME=${JAVA_HOME}

修改為你本機 jdk安裝的路徑

這裡修改的是我本機 jdk 的路徑
儲存 退出 :wq!
配置環境變數 yarn-env.sh
vi yarn-en.sh
在檔案靠前一部分找到以下程式碼:
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/

將這行程式碼修改為下面的程式碼(將#號去掉):
export JAVA_HOME=/root/usr/java/jdk1.8.0_152 (這裡是本機的 jdk 路徑)

配置核心元件 core-site.xml
vi core-site.xml
用下面的程式碼替換 <configuration> 中的內容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
配置檔案系統 hdfs-site.xml
vi hdfs-site.xml
用下面的程式碼替換 <configuration> 中的內容:
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop_tmp</value>
</property>
配置檔案系統 yarn-site.xml
vi yarn-site.xml
用下面的程式碼替換 <configuration> 中的內容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
配置計算框架 mapred-site.xml
先把mapred-site-template.xml更名為 mapred-site.xml
mv mapred-site-template.xml mapred-site.xml
vi mapred-site.xml
用下面的程式碼替換 <configuration> 中的內容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
在 master 節點配置 slaves 檔案
vi slaves
用下面的程式碼替換 slaves 中的內容:
slave1
slave2
以上配置是叢集的主機名 (如需要新增叢集 這裡配置需要新增)
#以上配置需要都在slave等從機設定以上配置,或者手動新增配置,或者拷貝過去。
配置 Hadoop 啟動的系統環境變數
先回到根目錄
cd ~
vi .bash_profile

export HADOOP_HOME=/root/bigdata/hadoop-2.7.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin

重新整理環境變數
source ~/.bash_profile
格式化 Hadoop 叢集
首先進入Hadoop安裝目錄下 的 bin 目錄
hdfs namenode -format
至此格式化完成,Hadoop安裝完成
啟動 Hadoop 叢集
首先進入Hadoop安裝目錄下
sbin/start-all.sh (只需要在master節點上啟動一次,無需再slave節點上啟動此命令!!!)
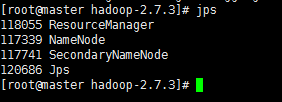
出現以下情況Hadoop則為啟動成功:

在master節點上輸入 jps 檢視程序
在slave節點上分別輸入 jps 檢視程序

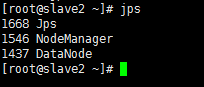
出現以上程序則為成啟動成功
為驗證是否Hadoop啟動成功,請在同區域網下的瀏覽器下輸入
master:50070 (有部分情況顯示解析不了 則把master換成master節點機器的ip地址)
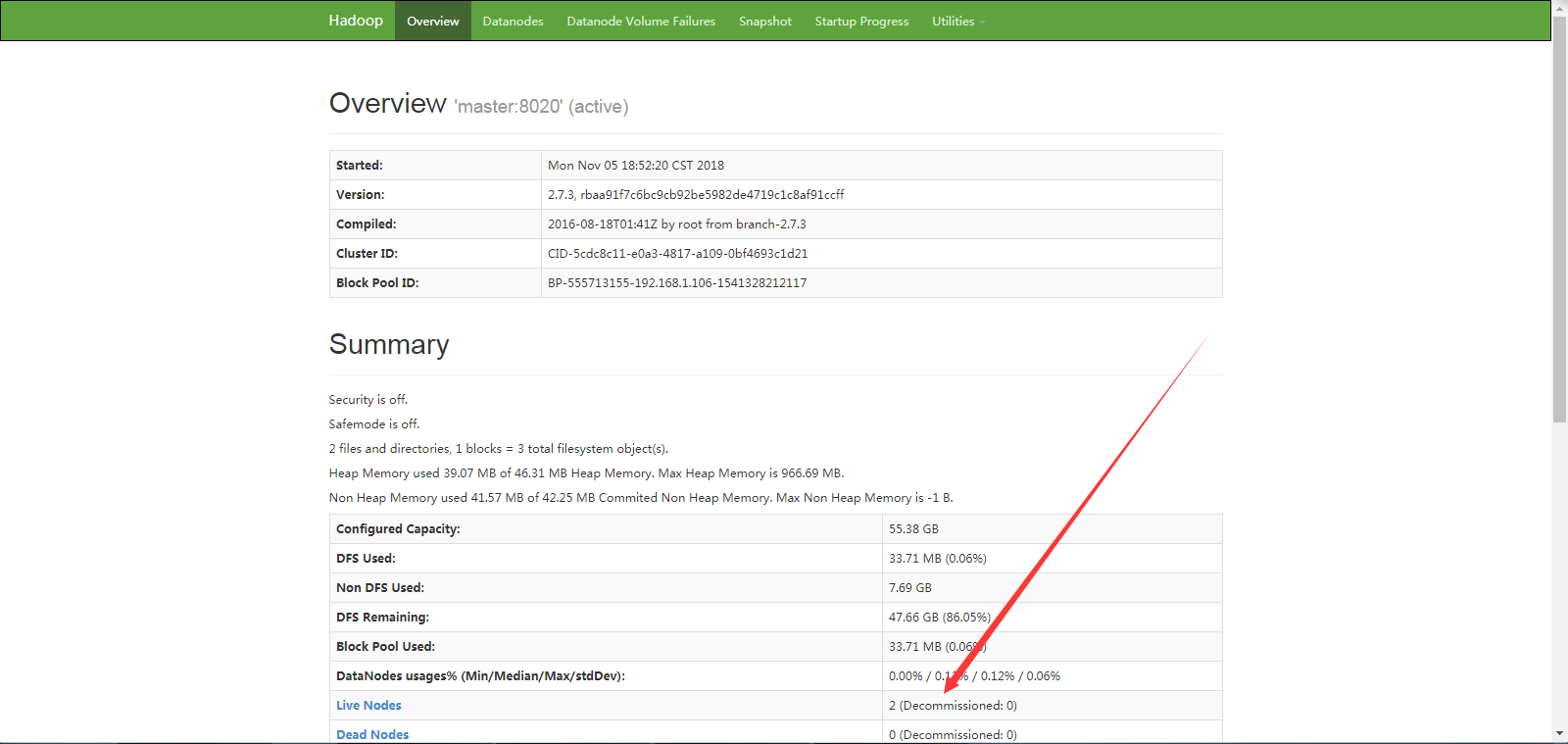
可以發現 存活的節點 數量為 2 。可是我們是三臺機器
開始排查錯誤
開啟web管理介面的 DataNode

檢視存活的節點

可以發現 slave1, slave2 。節點存活正常,而管理介面可以開啟,則master的namenode為正常,因無資料 則 DataNode 可能沒有啟動
我們單獨先啟動DataNode程序
首先進入Hadoop目錄下
輸入以下命令:
sbin/hadoop-daemon.sh start datanode

啟動完成,我們jps檢視以下啟動的程序,看看DataNode啟動沒有

可以發現 DataNode啟動成功,我們開啟web管理介面 重新整理看看有沒有master節點
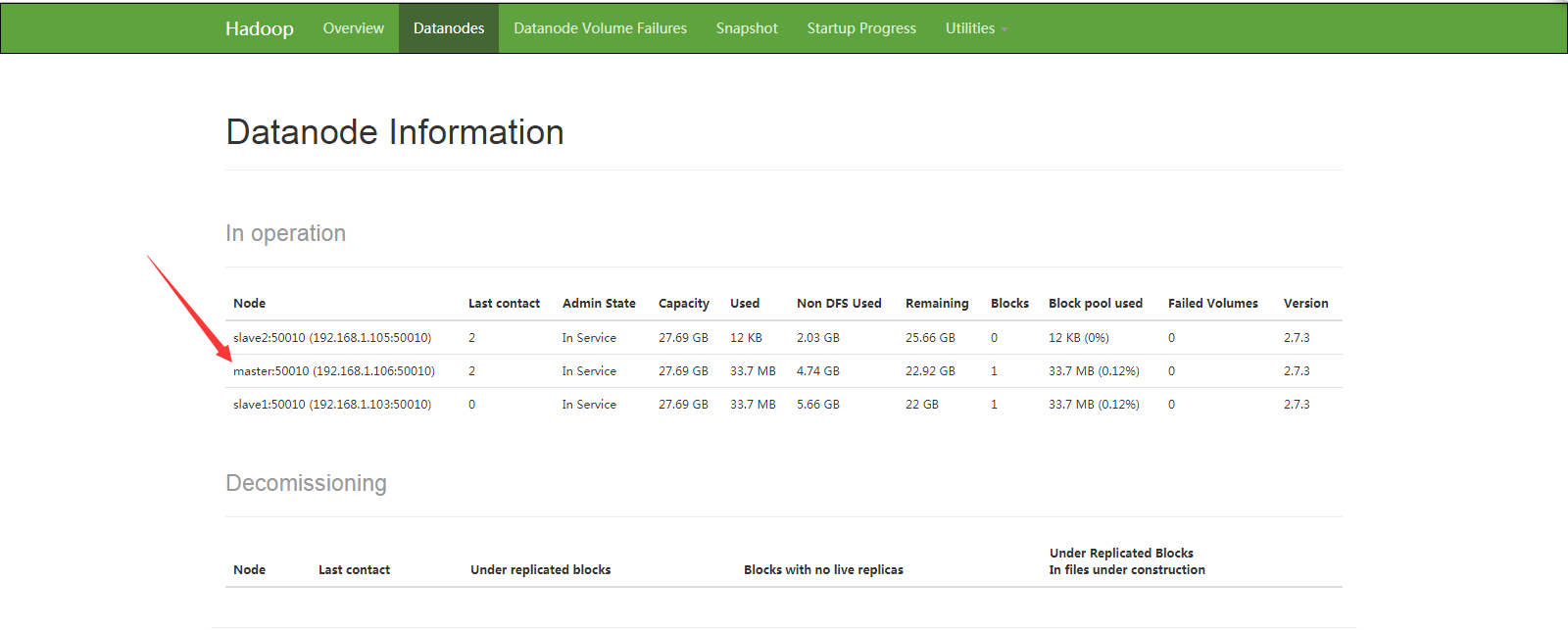
可以看到 master(主節點)啟動成功;
現在開啟yarn管理介面
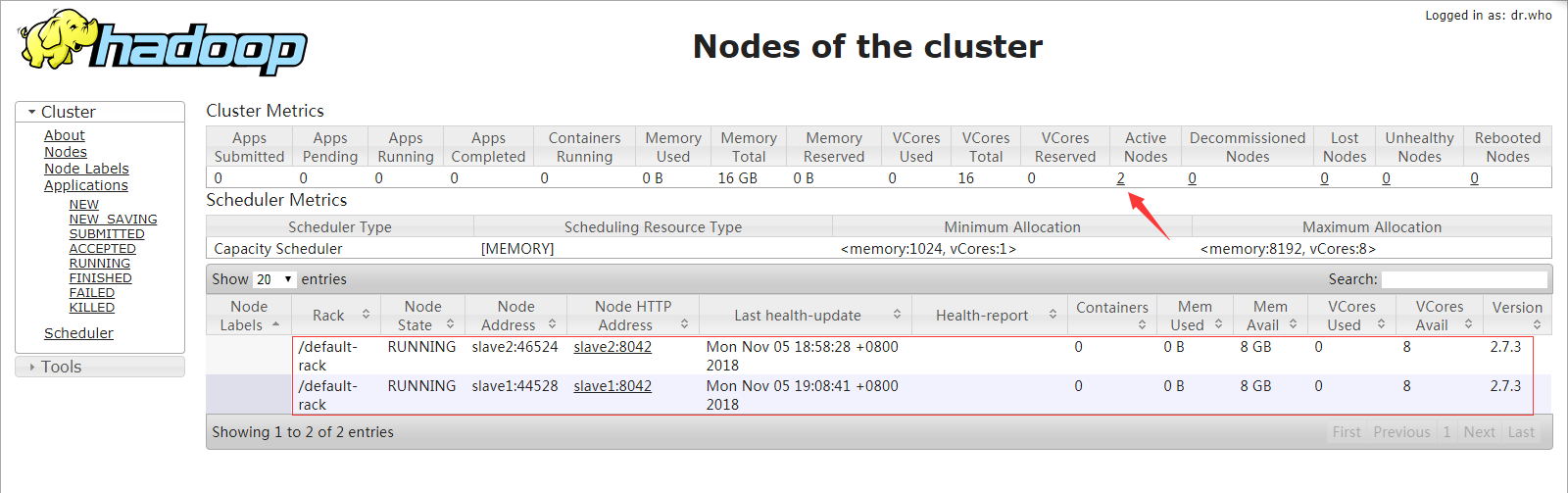
存活節點為 2 節點 slave1,slave2,都為正常
Hadoop停止
首先進入Hadoop安裝目錄下
sbin/stop-all.sh
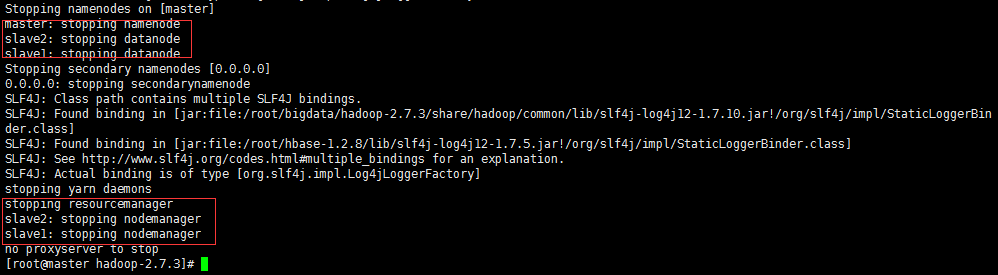
出現次情況則停止成功!!!此外 我們剛才單獨啟動了 DataNode 我們再次 jps 檢視一下程序


可以看出 master 節點上 DataNode 沒有停止。slave節點上都正常停止。
接下來我們單獨 關閉 DataNode 節點

master slave 節點程序全部關閉完成!!(在關機前必須得關閉所有的程序!!!)
至此 Hadoop安裝完成安裝 謝謝!!