
Storm-1.2.2介紹及完全分散式安裝
目錄
1 Storm是什麼
Apache Storm是一個分散式的、可靠的、容錯的實時資料流處理框架。Storm是Twitter開源的分散式實時大資料處理框架,最早開源於github,從0.9.1版本之後,歸於Apache社群,被業界稱為實時版Hadoop。隨著越來越多的場景對Hadoop的MapReduce高延遲無法容忍,比如網站統計、推薦系統、預警系統、金融系統(高頻交易、股票)等等,大資料實時處理解決方案(流計算)的應用日趨廣泛,目前已是分散式技術領域最新爆發點,而Storm更是流計算技術中的佼佼者和主流。

Storm的處理流程類似工業上的生產線,如上圖,取水口就相當於Storm的資料來源口Spout,經歷一系列的處理階段Bolt,最終送給使用者(即資料落地),構成一個拓撲結構。
它與Spark Streaming的最大區別在於它是逐個處理流式資料事件,而Spark Streaming是微批次處理,因此,它比Spark Streaming更實時。但相比新的實時流處理框架Flink來說,Flink提供了DataSet 和 DataStream兩個介面實現可批可流的處理機制,並且提供了Exactly-once語義,因此被越來越多的公司使用。如果非得給流處理框架排個序,小廚認為:Flink>Storm>Storm Trident>Spark Streaming。至於優先程度主要還得看具體的業務場景,例如某公司已經搭建了一個Spark平臺,並且對資料的實時性可以接受為分鐘級別,那麼可能Spark Streaming是最適合的。
2 Storm的核心概念
- nimbus:即Storm的Master,負責資源分配和任務排程。一個Storm叢集只有一個Nimbus。
- Supervisor:即Storm的Slave,負責接收Nimbus分配的任務,管理其本身所有Worker,一個Supervisor節點中包含多個Worker程序。
- worker:工作程序,每個工作程序中都有多個Task。
- Task:任務,在 Storm 叢集中每個 Spout 和 Bolt 都由若干個任務(tasks)來執行。每個任務都與一個執行執行緒相對應。
- Topology:DAG有向無環圖的實現。計算拓撲,Storm 的拓撲是對實時計算應用邏輯的封裝,它的作用與 MapReduce 的任務(Job)很相似,區別在於 MapReduce 的一個 Job 在得到結果之後總會結束,而拓撲會一直在叢集中執行,直到你手動去終止它。拓撲還可以理解成由一系列通過資料流(Stream Grouping)相互關聯的 Spout 和 Bolt 組成的的拓撲結構。
- Stream:從Spout中源源不斷傳遞資料給Bolt、以及上一個Bolt傳遞資料給下一個Bolt,所形成的這些資料通道即叫做Stream。可以根據StreamId繫結上下游的Bolt.
- Tuple:Stream中最小資料組成單元。(如下圖:多個Tuple構成一個Stream通道)

- Spout:資料來源(Spout)是拓撲中資料流的來源。一般 Spout 會從一個外部的資料來源讀取元組然後將他們傳送到拓撲中。根據需求的不同,Spout 既可以定義為可靠的資料來源,也可以定義為不可靠的資料來源。一個可靠的 Spout 能夠在它傳送的元組處理失敗時重新發送該元組,以確保所有的元組都能得到正確的處理;相對應的,不可靠的 Spout 就不會在元組傳送之後對元組進行任何其他的處理。一個 Spout 可以傳送多個數據流。
- Bolt:拓撲中所有的資料處理均是由 Bolt 完成的。通過資料過濾(filtering)、函式處理(functions)、聚合(aggregations)、聯結(joins)、資料庫互動等功能,Bolt 幾乎能夠完成任何一種資料處理需求。一個 Bolt 可以實現簡單的資料流轉換,而更復雜的資料流變換通常需要使用多個 Bolt 並通過多個步驟完成。
資料流處理圖如下圖所示:

3 Storm原理架構

Storm架構圖如上圖所示。
整個結構非常類似於Hadoop的架構,其中
- Nimbus:主控節點,用於提交任務,負責資源分配和認為排程,相當於Hadoop的JobManager;
- Supervisor:接受Nimbus分配的任務,管理worker程序,相當於Hadoop的TaskManager;
- Zookeeper:協調,存放叢集的公共資料(心跳、叢集狀態、配置資訊等),Nimbus分配給supervisor的任務
Supervisor節點與Nimbus節點通訊是依靠心跳機制,而Zookeeper對整個叢集統一進行協調管理。Topo處理如下圖所示:

4 Storm叢集安裝部署
主機資訊如下表:
|
主機名 |
作業系統版本 |
IP地址 |
安裝軟體 |
|
master |
Centos 6.5 |
192.168.83.131 |
JDK 1.8、 zookeeper-3.4.10、apache-storm-1.2.2 |
|
slave1 |
Centos 6.5 |
192.168.83.130 |
JDK 1.8、 zookeeper-3.4.10、apache-storm-1.2.2 |
|
slave3 |
Centos 6.5 |
192.168.83.133 |
JDK 1.8、 zookeeper-3.4.10、apache-storm-1.2.2 |
安裝Storm之前首先保證之前安裝的Zookeeper服務正常執行,包括配置hosts對映,主機名修改,防火牆都已經設定完好
4.1 下載Storm 1.2.2
http://storm.apache.org/downloads.html。儲存到windows下之後,在linux系統中建立Storm目錄,mkdir /usr/storm 使用Winscp傳輸到linux系統該資料夾內,如下:

4.2 解壓,更改配置檔案
Linux 系統下解壓即安裝: tar -zvxf apache-storm-1.2.2.tar.gz
![]()
切換到conf目錄下,建立storm-local目錄,更改storm.yaml檔案。1、首先配置Zookeeper的主機名,也可用IP地址代替;2、指定Storm-Local的資料夾位置,Nimbus和Supervisor守護程序需要本地磁碟上的目錄來儲存少量狀態(如jar,confs和類似的東西);3、用於配置主控節點的地址,可以配置多個;4、配置每個 Supervisor 機器能夠執行的工作程序(worker)數。每個 worker 都需要一個單獨的埠來接收訊息。新增以下內容:
########### These MUST be filled in for a storm configuration
storm.zookeeper.servers:
- "master"
- "slave1"
- "slave3"
#
storm.local.dir: "/usr/storm/apache-storm-1.2.2/storm-local"
nimbus.seeds: ["master"]
supervisor.slots.ports:
- 6701
- 6702
- 6703
- 6704
- 6705
- 6706更改完的配置檔案如下圖所示,此處設定了6個Slots埠,可根據實際情況設定。

本文省略了將Storm配置到環境變數一步,步驟很簡單。vi /etc/profile 新增以下內容,再執行 source /etc/profile即可:
export STORM_HOME=/usr/storm/apache-storm-1.2.2/
export PATH=$PATH:$STORM_HOME/bin4.3 將配置好的節點分發到兩個從節點上
scp -r /usr/storm/apache-storm-1.2.2/ [email protected]: /usr/storm
scp -r /usr/storm/apache-storm-1.2.2/ [email protected]: /usr/storm
5 啟動storm叢集及web監控
啟動Storm叢集之前,我們首先需要在三臺虛機上啟動ZooKeeper程序
cd /usr/zookeeper/zookeeper-3.4.10/bin
./zkServer.sh start在三臺機器啟動zookeeper程序之後,可以分別檢視機器狀態,./zkServer.sh status。至此,開始分別啟動storm叢集
啟動nimbus程序在master機器上執行啟動命令,兩種方式:
- 前臺啟動:./storm nimbus 這種方式啟動之後,程序資訊會一直佔用介面,從而導致需要重新開啟視窗進行相關操作

- 後臺啟動:./storm nimbus 1>/dev/null 2>&1 這種啟動方式所有的提示資訊均在後臺,使用者不可直觀看見,但是可以在本介面輸入其他命令,進行叢集操作。推薦此種方法

啟動Supervisor程序,在兩臺slave機器上執行啟動命令,方式也如nimbus啟動一樣
./storm supervisor
或者
./storm supervisor 1>/dev/null 2>&1 &至此,nimbus和supervisor均已啟動成功,可使用jps檢視相關程序是否啟動成功,本例檢視slave3上的相關程序:
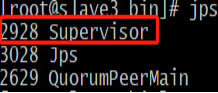
啟動UI頁面,進行相關監控,包括solts數量、目前正在執行的topo
在master節點上,輸入以下命令,啟動方式如nimbus:
./storm ui
或者
./storm ui 1>/dev/null 2>&1 &訪問ui頁面: master:8080/ 或者 192.168.83.131:8080

在master上檢視相關程序,如下圖:

至此,storm叢集已經搭建成功。
相關推薦
Storm-1.2.2介紹及完全分散式安裝
目錄 1 Storm是什麼 Apache Storm是一個分散式的、可靠的、容錯的實時資料流處理框架。Storm是Twitter開源的分散式實時大資料處理框架,最早開源於github,從0.9.1版本之後,歸於Apache社群,被業界稱為
Storm-1.2.2完全分散式安裝
環境:zookeeper-3.4.10,ubuntu-16.0.4,jdk1.8.0_111我這裡在四臺機器上安裝,分別是Desktop(Master),Server1,(Slave1),Server2(Slave2),Server3(Slave3)可以將Storm中的nim
hadoop2.7.3完全分散式安裝-docker-hive1.2.1-hiveserver2-weave1.9.3
0.環境介紹: 1)ubuntu14.04 docker映象 地址:https://github.com/gaojunhao/ubuntu14.04 2)hadoop2.7.3 地址:http://www.apache.org/dyn/closer.cgi/hadoop/c
初識TomCat之2——TomCat介紹及安裝
重啟 一個tomcat security direct 查看 介紹 虛擬 vpd use 一、TomCat介紹通過之前的介紹,Tomcat與JDK共同構成了一個Web Container容器,它在JDK的基礎上提供了Servlet和JSP組件,可以接受來自客戶端的動態請求,
Hadoop2.5.2叢集部署(完全分散式)
環境介紹 硬體環境 CPU 4 MEM 4G 磁碟 60G 軟體環境 OS:centos6.5版本 64位 Hadoop:hadoop2.5.2 64位 JDK: JDK 1.8.0_91 主機配
Hadoop完全分散式安裝2
hadoop簡介: 1.獨立模式(standalone|local)單機模式;所有的產品都安裝在一臺機器上且本地磁碟和副本可以在接下來的xml檔案中 nothing! &
大資料技術學習筆記之Hadoop框架基礎1-Hadoop介紹及偽分散式部署
一、學習建議 -》學習思想 -》設計思想:分散式 -》資料採集
基於hadoop-2.6.0的hbase完全分散式安裝
1.安裝環境:有一個完全分散式的hadoop-2.6.0。 2.安裝準備:需要在網上下一個hbase的壓縮包,我這兒用的是hbase-1.0.3-bin.tar.gz,下載地址here 3.解壓下載好的hbase到一個目錄下,並更改使用者及使用者組(我這兒用
Storm 1.0.2
單詞計數拓撲WordCountTopology實現的基本功能就是不停地讀入一個個句子,最後輸出每個單詞和數目並在終端不斷的更新結果,拓撲的資料流如下: 語句輸入Spout: 從資料來源不停地讀入資料,並生成一個個句子,輸出的tuple格式:{"sentence"
Fiddler抓包【1】_介紹及界面概述
緩存 沒有 user 編輯器 主菜單 selected ble bar 文件格式 一、 主要抓包工具介紹與對比 1、Wireshark :通用抓包工具,抓取信息量龐大,需要過濾才能得到有用信息,只抓HTTP請求有點大財小用。 2、Firebug、HttpWatch等We
自動化運維工具之SaltStack-1、SaltStack介紹及安裝
自動生成 模塊 模糊匹配 mini 說明 pac roc redhat 通信 1、SaltStack簡介 官方網址:http://www.saltstack.com官方文檔:http://docs.saltstack.comGitHub:https:github.com/s
21.2 memcached介紹;21.2 memcached介紹;21.3 安裝memcached
安裝memcached21.2 memcached介紹什麽是NoSQL?1. 非關系型數據庫就是NoSQL,關系型數據庫代表MySQL2. 對於關系型數據庫來說,是需要把數據存儲到庫、表、行、字段裏,查詢的時候根據條件一行一行地去匹配,當量非常大的時候就很耗費時間和資源,尤其是數據是需要從磁盤裏去檢索3. N
2.Keepalived介紹 (接上keepalived安裝配置並測試)
cpu ash 說明 多臺 curl sta 配置 keepaliv ipaddress 2.Keepalived介紹在這裏我們使用Keeplived來實現高可用集群,因為heartbeat在centos6上有一些問題,影響實驗效果(切換不及時問題)keepalived通過
hadoop3.1.0 HA高可用完全分散式叢集的安裝部署(詳細教程)
1.環境介紹 伺服器環境:CentOS 7 5臺伺服器 兩臺namenode 三臺datanode 節點 IP NN DN ZK ZKFC
hadoop2.2.0上spark偽分散式安裝
1. 從官網上下下載合適的版本: http://spark.apache.org/downloads.html 筆者下載的是for hadoop2.2版本的spark0.9.2 2. 解壓,配置環境: sudo gedit /etc/profile 新增SPARK_HOM
MYSQL基礎加固——SQL的介紹及MySQL的安裝
語句格式 查看表 產生 進行 ble mysql lin perf 需求 2.1 數據庫和 SQL 概念 數據庫(Database)是按照數據結構來組織、存儲和管理數據的倉庫,它的產生距今已有六十多年。隨著信息技術和市場的發展,數據庫變得無處不在:它在電子商務、銀行系統等眾
Lamp、MySQL架構介紹及MySQL的安裝
20180523一、Lamp架構介紹 1?是一個簡寫,它包含了四個東西:Linux 操作系統;Apache(httpd) 是一個web服務軟件;MySQL 數據存儲軟件;PHP 腳本語言,和shell類似,比shell復雜,通常用來做網站; 2?httpd 、PHP、MySQL三者是如何工作的,用戶瀏覽器
LNMP介紹及php的安裝
LNMP PHP LNMP架構介紹 和LAMP不同的是,提供web服務的是Nginx 並且php是作為一個獨立服務存在的,這個服務叫做php-fpm Nginx直接處理靜態請求(並發量比apache高多),動態請求會轉發給php-fpm Mysql安裝 卸載mysql,直接刪除mysql的相關
NFS的介紹及服務端安裝配置、配置選項
c89 數據傳輸 net nfs配置 MF RoCE mage tap blog 一、NFS介紹NFS是Network File System的縮寫NFS最早由Sun公司開發,分2,3,4三個版本,2和3由Sun起草開發,4.0開始Netapp公司參與並主導開發,最新為4.
Hadoop完全分散式安裝Hive
編譯安裝 Hive 如果需要直接安裝 Hive,可以跳過編譯步驟,從 Hive 的官網下載編譯好的安裝包,下載地址為http://hive.apache.org/downloads.html。 Hive的環境配置需要MySQL的支援,所以首先需要安裝MySQL,