
pytorch綜合多個弱分類器,投票機制,進行手寫數字分類(boosting)
阿新 • • 發佈:2018-11-05
首先,這個文章的出發點就是讓一個網路一個圖片進行預測,在直觀上不如多個網路對一個圖片進行預測之後再少數服從多數效果好。
也就是對於任何一個分類任務,訓練n個弱分類器,也就是分類準確度只比隨機猜好一點,那麼當n足夠大的時候,通過投票機制,也能提升很大的準確度:畢竟每個網路都分錯同一個資料的可能性會降低。
接下來就是程式碼實現。
import torch import torchvision import torch.nn as nn from torch.utils.data import DataLoader from collections import Counter import numpy as np class MLP(nn.Module): def __init__(self): super(MLP, self).__init__() self.input_layer=nn.Sequential( nn.Linear(28*28,30), nn.Tanh(), ) self.output_layer=nn.Sequential( nn.Linear(30,10), #nn.Sigmoid() ) def forward(self, x): x=x.view(x.size(0),-1) x=self.input_layer(x) x=self.output_layer(x) return x trans=torchvision.transforms.Compose( [ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize([.5],[.5]), ] ) BATCHSIZE=100 DOWNLOAD_MNIST=False EPOCHES=200 LR=0.001 train_data=torchvision.datasets.MNIST( root="./mnist",train=True,transform=trans,download=DOWNLOAD_MNIST, ) test_data=torchvision.datasets.MNIST( root="./mnist",train=False,transform=trans,download=DOWNLOAD_MNIST, ) train_loader=DataLoader(train_data,batch_size=BATCHSIZE,shuffle=True) test_loader =DataLoader(test_data,batch_size=BATCHSIZE,shuffle=False) mlps=[MLP().cuda() for i in range(10)] optimizer=torch.optim.Adam([{"params":mlp.parameters()} for mlp in mlps],lr=LR) loss_function=nn.CrossEntropyLoss() for ep in range(EPOCHES): for img,label in train_loader: img,label=img.cuda(),label.cuda() optimizer.zero_grad()#10個網路清除梯度 for mlp in mlps: out=mlp(img) loss=loss_function(out,label) loss.backward()#網路們獲得梯度 optimizer.step() pre=[] vote_correct=0 mlps_correct=[0 for i in range(len(mlps))] for img,label in test_loader: img,label=img.cuda(),label.cuda() for i, mlp in enumerate( mlps): out=mlp(img) _,prediction=torch.max(out,1) #按行取最大值 pre_num=prediction.cpu().numpy() mlps_correct[i]+=(pre_num==label.cpu().numpy()).sum() pre.append(pre_num) arr=np.array(pre) pre.clear() result=[Counter(arr[:,i]).most_common(1)[0][0] for i in range(BATCHSIZE)] vote_correct+=(result == label.cpu().numpy()).sum() print("epoch:" + str(ep)+"總的正確率"+str(vote_correct/len(test_data))) for idx, coreect in enumerate( mlps_correct): print("網路"+str(idx)+"的正確率為:"+str(coreect/len(test_data)))
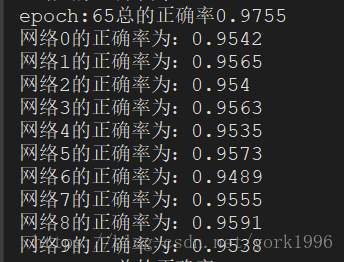
可以看到雖然網路模型很簡單,但是通過多個弱分類模型的投票,得到的結果也是比其中任何一個網路的效果都要好不少的。應該關注相對提升,不應該關注絕對提升。
這些網路模型的架構一致,只是初始化不一樣。如果模型之間架構差別比較大,比如有簡單的cnn,dnn,rnn,svm等等,效果可能更好。