阿里雲三臺節點,搭建完全分散式hadoop叢集,超簡單
完全分散式的安裝
1、叢集規劃
角色分配
| NODE-47 | NODE-101 | NODE-106 | |
| HDFS |
Namenode Datanode |
SecondaryNamenode Datanode |
Datanode |
| YARN | Nodemanager | Nodemanager |
RecourceManager Nodemanager |
| Histrory | HistroryServer |
2、阿里雲環境
CentOS 7.4 hadoop 2.8.3 jdk1.8 (centos 版本無影響)
2.1 . 關閉防火牆 (3臺) (root)
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall開機啟動
firewall-cmd --state #檢視預設防火牆狀態(關閉後顯示notrunning,開啟後顯示running)
2.2 . 配置主機對映 【三臺都需要需要新增】
# vi /etc/hosts (node-47為例)
106.xx.xx.xxx node-106 ( 外網ip)
172.xxx.xx.xx node-47 ( 內網ip)
101.xx.xx.1xx node-101 (外網ip)
注意:這裡有坑,就是每臺機器配置hosts的時候,自己的ip一定要設定為內網ip,其他節點ip設定為外網ip。否則hdfs或者yarn啟動的時候都會報埠被佔用的異常,不信可以試試。
2.3. 安裝jdk
先解除安裝自帶的jdk
# rpm -qa | grep jdk
# rpm -e --nodeps tzdata-java-2012j-1.el6.noarch
# rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.50.1.11.5.el6_3.x86_64
# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.9-2.3.4.1.el6_3.x86_64
下載jdk
#JAVA_HOME
export JAVA_HOME=/usr/jdk
export PATH=$JAVA_HOME/bin:$PATH
生效配置
source /etc/profile
檢查Java環境變數
[[email protected] ~]# java -version
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
3、配置SSH免金鑰登入
使用ssh登入的時候不需要使用者名稱密碼
對node-47執行
$ ssh-keygen 回車,生產當前主機的公鑰和私鑰
//分發金鑰(要向3臺都發送)
$ ssh-copy-id node-47
$ ssh-copy-id node-101
$ ssh-copy-id node-106
然後就可以測試一下,node-47 ssh 其他機器是不是可以免密碼登陸了,如果ok,如下
[[email protected] .ssh]# ssh node-101
Last login: Thu Sep 13 14:32:22 2018 from 180.169.129.212
Welcome to Alibaba Cloud Elastic Compute Service !
那接下來,操作另外兩臺機器對其他機器的免密碼登陸。
$ ssh-keygen
$ ssh-copy-id node-47
$ ssh-copy-id node-101
$ ssh-copy-id node-106
分發完成之後會在使用者主目錄下.ssh目錄生成以下檔案
$ ls .ssh/
authorized_keys id_rsa id_rsa.pub known_hosts
測試失敗,需要先刪除.ssh目錄下的所有檔案,重做一遍
4、安裝Hadoop
1. 下載hadoop
2. 刪除${HADOOP_HOME}/share/doc
$ rm -rf doc/
3. 配置java環境支援在${HADOOP_HOME}/etc/hadoop
在hadoop-env.sh mapred-env.sh yarn-env.sh中配置
export JAVA_HOME=/usr/jdk
4.=======core-site.xml===
<!--指定第一臺作為NameNode-->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node-47:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.8.3/data</value>
</property>
</configuration>
=============hdfs-site.xml==========
<configuration>
<!-- 分散式副本數設定為3 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- secondarynamenode主機名 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node-101:50090</value>
</property>
<!-- namenode的web訪問主機名:埠號 -->
<property>
<name>dfs.namenode.http-address</name>
<value>node-47:50070</value>
</property>
<!-- 關閉許可權檢查使用者或使用者組 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
=================mapred-site.xml=======
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node-47:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node-47:19888</value>
</property>
</configuration>
================yarn-site.xml======
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node-106</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
</configuration>
===============================
5. 配置slaves
node-47
node-101
node-106
5、分發hadoop(已經配置好的)目錄到其他兩臺伺服器上
scp -r /opt/modules/hadoop-2.8.3 node-101:/opt/modules/
scp -r /opt/modules/hadoop-2.8.3 node-106:/opt/modules/
6、格式化Namenode
先配置hadoop環境變數
export HADOOP_HOME=/opt/modules/hadoop-2.8.3
export PATH=$HADOOP_HOME/bin:$PATH
在node-47上的${HADOOP_HOME}/bin
$ bin/hdfs namenode -format
【注意】
1.先將node-47的hadoop配置目錄分發到node-101和node-106
2.保證3臺上的配置內容一模一樣
3.先確保將3臺之前殘留的data 和 logs刪除掉(如果沒有data目錄,需要先建立data目錄)
4.最後格式化
7、啟動程序
在node-47上使用如下命令啟動HDFS
$ sbin/start-dfs.sh
在node-106上使用如下命令啟動YARN
$ sbin/start-yarn.sh
停止程序
在node-47上使用如下命令停止HDFS
$ sbin/stop-dfs.sh
在node-106上使用如下命令停止YARN
$ sbin/stop-yarn.sh
【注意】
修改任何配置檔案,請先停止所有程序,然後重新啟動
8、檢查啟動是否正常
3臺上jps檢視程序,參考之前的叢集規劃
node-47:
15328 SecondaryNameNode
15411 NodeManager
15610 Jps
15228 DataNode
node-101:
15328 SecondaryNameNode
15411 NodeManager
15620 Jps
15228 DataNode
PC3
17170 DataNode
17298 ResourceManager
17401 NodeManager
驗證namenode的web訪問是否正常
namenode的web訪問主機名 (注意如果訪問不了,應該是埠沒有開啟,可以配置安全組,將50070埠開啟)
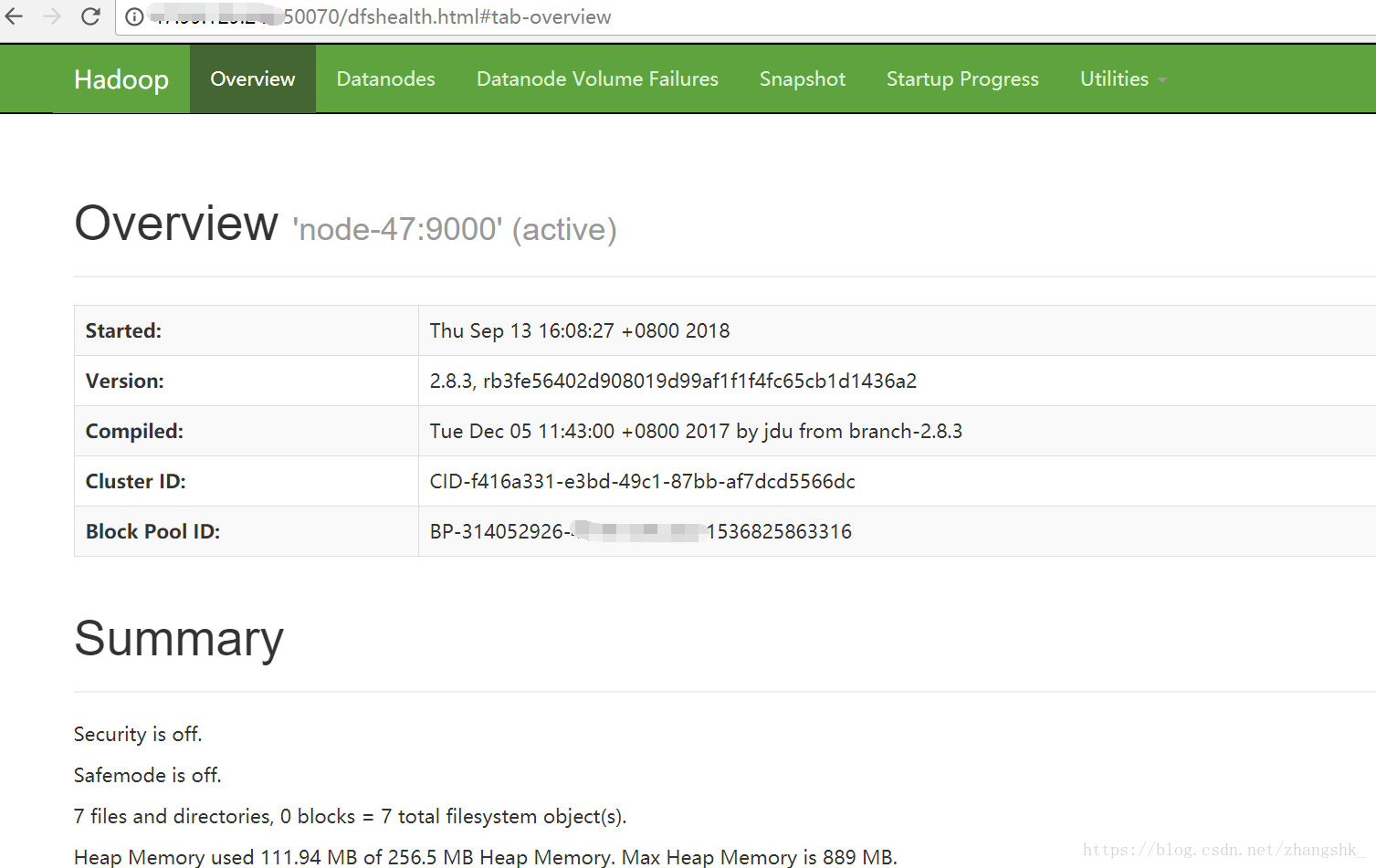
此外可以看到三個節點連線正常:
hdfs dfs -put wc.txt /test
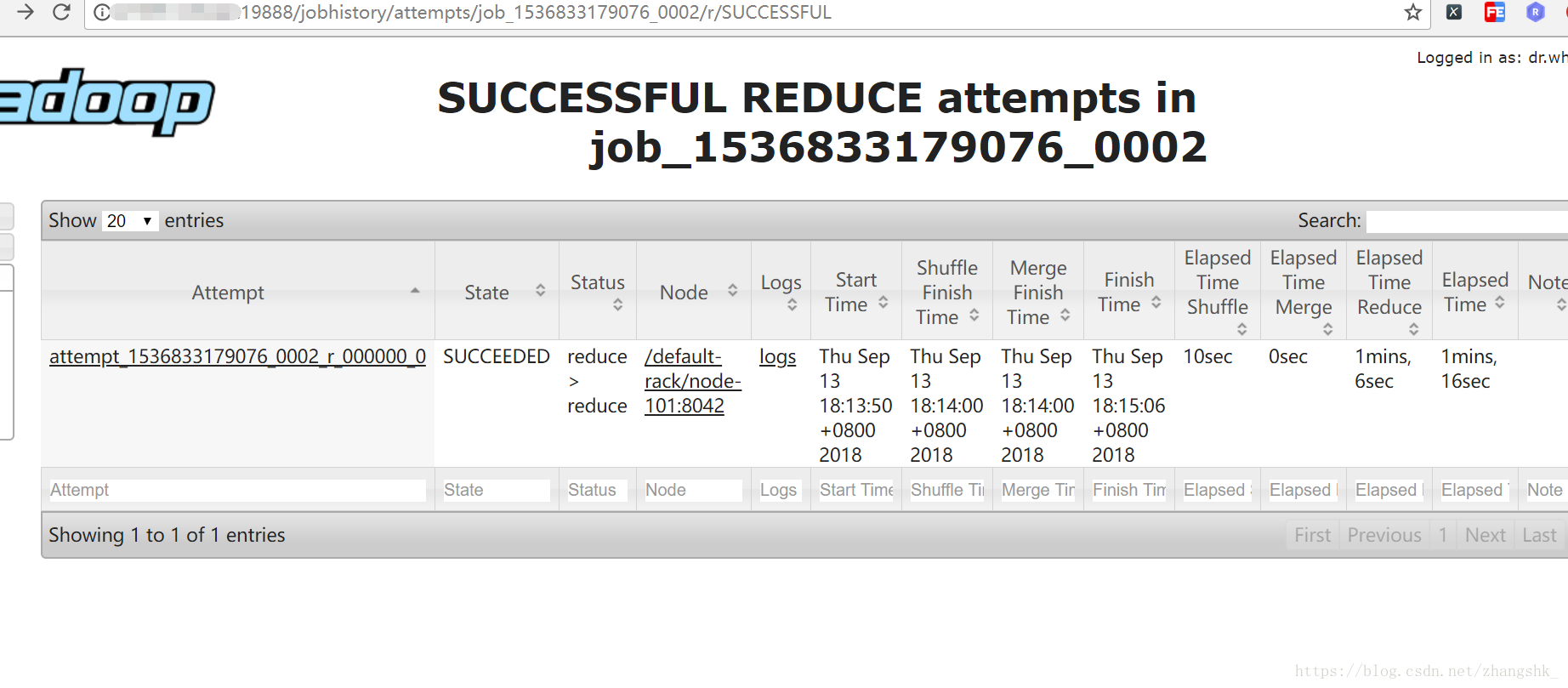
9.wordcount驗證
下面,通過hadoop自帶的example ,入門的wordcount,測試一下MR, 同時看一下日誌聚集功能是否正常。
hadoop jar /opt/modules/hadoop-2.8.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar wordcount /test/wc.txt /output/wc
發現可以正常執行:
[[email protected] datasource]# hadoop jar /opt/modules/hadoop-2.8.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar wordcount /test/wc.txt /output/wc
18/09/13 18:12:49 INFO client.RMProxy: Connecting to ResourceManager at node-106/106.15.182.83:8032
18/09/13 18:12:51 INFO input.FileInputFormat: Total input files to process : 1
18/09/13 18:12:52 INFO mapreduce.JobSubmitter: number of splits:1
18/09/13 18:12:54 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1536833179076_0002
18/09/13 18:12:56 INFO impl.YarnClientImpl: Submitted application application_1536833179076_0002
18/09/13 18:12:56 INFO mapreduce.Job: The url to track the job: http://node-106:8088/proxy/application_1536833179076_0002/
18/09/13 18:12:56 INFO mapreduce.Job: Running job: job_1536833179076_0002
18/09/13 18:13:13 INFO mapreduce.Job: Job job_1536833179076_0002 running in uber mode : false
18/09/13 18:13:13 INFO mapreduce.Job: map 0% reduce 0%
18/09/13 18:13:49 INFO mapreduce.Job: map 100% reduce 0%
18/09/13 18:14:13 INFO mapreduce.Job: map 100% reduce 100%
18/09/13 18:18:55 INFO mapreduce.Job: Job job_1536833179076_0002 completed successfully
18/09/13 18:18:56 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=106
FILE: Number of bytes written=315145
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=194
HDFS: Number of bytes written=68
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Rack-local map tasks=1
Total time spent by all maps in occupied slots (ms)=32367
Total time spent by all reduces in occupied slots (ms)=76224
Total time spent by all map tasks (ms)=32367
Total time spent by all reduce tasks (ms)=76224
Total vcore-milliseconds taken by all map tasks=32367
Total vcore-milliseconds taken by all reduce tasks=76224
Total megabyte-milliseconds taken by all map tasks=33143808
Total megabyte-milliseconds taken by all reduce tasks=78053376
Map-Reduce Framework
Map input records=7
Map output records=16
Map output bytes=162
Map output materialized bytes=106
Input split bytes=96
Combine input records=16
Combine output records=8
Reduce input groups=8
Reduce shuffle bytes=106
Reduce input records=8
Reduce output records=8
Spilled Records=16
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=275
CPU time spent (ms)=1360
Physical memory (bytes) snapshot=387411968
Virtual memory (bytes) snapshot=4232626176
Total committed heap usage (bytes)=226557952
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=98
File Output Format Counters
Bytes Written=68
結果:
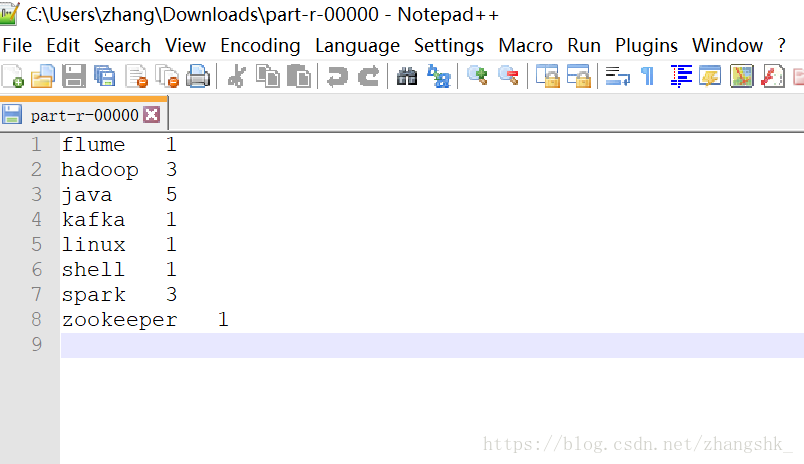
日誌聚集也正常: