
redis學習筆記——主從同步(複製)
在Redis中,使用者可以通過執行SLAVEOF命令或者設定slaveof選項,讓一個伺服器去複製(replicate)另一個伺服器,我們稱呼被複制的伺服器為主伺服器(master),而對主伺服器進行復制的伺服器則被稱為從伺服器(slave),如圖所示。
![]()
假設現在有兩個Redis伺服器,地址分別為127.0.0.1:6379和127.0.0.1:12345,如果我們向伺服器127.0.0.1:12345傳送以下命令:
127.0.0.1:12345> SLAVEOF 127.0.0.1 6379
OK
那麼伺服器127.0.0.1:12345將成為127.0.0.1:6379的從伺服器,而伺服器127.0.0.1:6379則會成為127.0.0.1:12345的主伺服器。
(記得去http://redisdoc.com/topic/replication.html上將一些操作進行補充)
本文是按照《Redis設計與實現》一書所整理的,感覺原書講的非常棒,所以下面的這部分的知識將按照原書的邏輯進行介紹:
先介紹舊版複製功能在處理斷線後重新連線的從伺服器時,會遇上怎樣的低效情況。新版複製功能是如何通過部分重同步來解決舊版複製功能的低效問題的,並說明部分重同步的實現原理。
舊版複製功能的實現
Redis的複製功能分為同步(sync)和命令傳播(command propagate)兩個操作:
- 同步操作用於將從伺服器的資料庫狀態更新至主伺服器當前所處的資料庫狀態;
- 命令傳播操作則用於在主伺服器的資料庫狀態被修改,導致主從伺服器的資料庫狀態出現不一致時,讓主從伺服器的資料庫重新回到一致狀態。
同步
當客戶端向從伺服器傳送SLAVEOF命令,要求從伺服器複製主伺服器時,從伺服器首先需要執行同步操作,也即是,將從伺服器的資料庫狀態更新至主伺服器當前所處的資料庫狀態。
從伺服器對主伺服器的同步操作需要通過向主伺服器傳送SYNC命令來完成,以下是SYNC命令的執行步驟:
- 從伺服器向主伺服器傳送SYNC命令;
- 收到SYNC命令的主伺服器執行BGSAVE命令,在後臺生成一個RDB檔案,並使用一個緩衝區記錄從現在開始執行的所有寫命令;
- 當主伺服器的BGSAVE命令執行完畢時,主伺服器會將BGSAVE命令生成的RDB檔案傳送給從伺服器,從伺服器接收並載入這個RDB檔案,將自己的資料庫狀態更新至主伺服器執行BGSAVE命令時的資料庫狀態。
- 主伺服器將記錄在緩衝區裡面的所有寫命令傳送給從伺服器,從伺服器執行這些寫命令,將自己的資料庫狀態更新至主伺服器資料庫當前所處的狀態。
命令傳播
在執行完同步操作之後,主從伺服器之間資料庫狀態已經相同了。但這個狀態並非一成不變,如果主伺服器執行了寫操作,那麼主伺服器的資料庫狀態就會修改,並導致主從伺服器狀態不再一致。
所以為了讓主從伺服器再次回到一致狀態,主伺服器需要對從伺服器執行命令傳播操作:主伺服器會將自己執行的寫命令,也即是造成主從伺服器不一致的那條寫命令,傳送給從伺服器執行,當從伺服器執行了相同的寫命令之後,主從伺服器將再次回到一致狀態。
舊版複製功能的缺陷
在Redis中,從伺服器對主伺服器的複製可以分為以下兩種情況:
- 初次複製:從伺服器以前沒有複製過任何主伺服器,或者從伺服器當前要複製的主伺服器和上一次複製的主伺服器不同;
- 斷線後重複製:處於命令傳播階段的主從伺服器因為網路原因而中斷了複製,但從伺服器通過自動重連線重新連上了主伺服器,並繼續複製主伺服器。
對於初次複製來說,舊版複製功能能夠很好地完成任務,但對於斷線後重複製來說,舊版複製功能雖然也能讓主從伺服器重新回到一致狀態,但效率卻非常低。
我們給出一個例子進行說明:
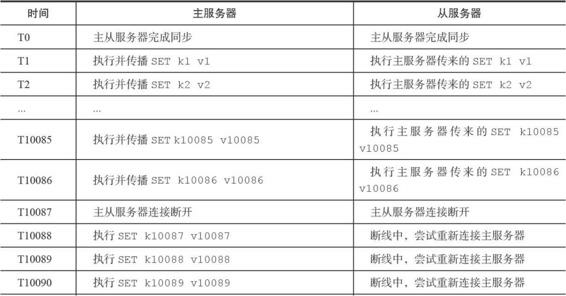
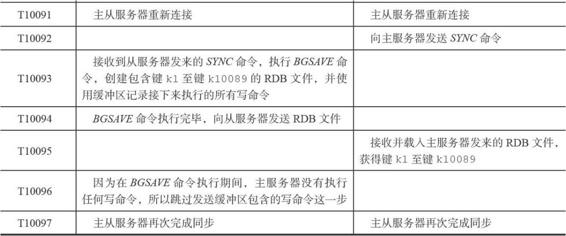
從伺服器終於重新連線上主伺服器,因為這時主從伺服器的狀態已經不再一致,所以從伺服器將向主伺服器傳送SYNC命令,而主伺服器會將包含鍵k1至鍵k10089的RDB檔案傳送給從伺服器,從伺服器通過接收和載入這個RDB檔案來將自己的資料庫更新至主伺服器資料庫當前所處的狀態。
上面給出的例子可能有一點理想化,因為在主從伺服器斷線期間,主伺服器執行的寫命令可能會有成百上千個之多,而不僅僅是兩三個寫命令。但總的來說,主從伺服器斷開的時間越短,主伺服器在斷線期間執行的寫命令就越少,而執行少量寫命令所產生的資料量通常比整個資料庫的資料量要少得多,在這種情況下,為了讓從伺服器補足一小部分缺失的資料,卻要讓主從伺服器重新執行一次SYNC命令,這種做法無疑是非常低效的。
SYNC命令是一個非常耗費資源的操作
SYNC命令是非常消耗資源的,因為每次執行SYNC命令,主從伺服器需要執行一下操作:
- 主伺服器需要執行BGSAVE命令來生成RDB檔案,這個生成操作會耗費主伺服器大量的CPU、記憶體和磁碟I/O資源;
- 主伺服器需要將自己生成的RDB檔案傳送給從伺服器,這個傳送操作會耗費主從伺服器大量的網路資源(頻寬和流量),並對主伺服器響應命令請求的時間產生影響;
- 接收到RDB檔案的從伺服器需要載入主伺服器發來的RDB檔案,並且在載入期間,從伺服器會因為阻塞而沒辦法處理命令請求。
SYNC是一個如此消耗資源的命令,所以Redis最好在真需要的時候才需要執行SYNC命令。
新版複製功能的實現
為了解決舊版複製功能在處理斷線重複制情況時的低效問題,Redis從2.8版本開始,使用PSYNC命令代替SYNC命令來執行復制時的同步操作。
PSYNC命令具有完整重同步(full resynchronization)和部分重同步(partial resynchronization)兩種模式:
- 其中完整重同步用於處理初次複製情況:完整重同步的執行步驟和SYNC命令的執行步驟基本一樣,它們都是通過讓主伺服器建立併發送RDB檔案,以及向從伺服器傳送儲存在緩衝區裡面的寫命令來進行同步;
- 而部分重同步則用於處理斷線後重複製情況:當從伺服器在斷線後重新連線主伺服器時,如果條件允許,主伺服器可以將主從伺服器連線斷開期間執行的寫命令傳送給從伺服器,從伺服器只要接收並執行這些寫命令,就可以將資料庫更新至主伺服器當前所處的狀態。
我們現在試舉一例來看看使用PSYNC處理斷線後情況:
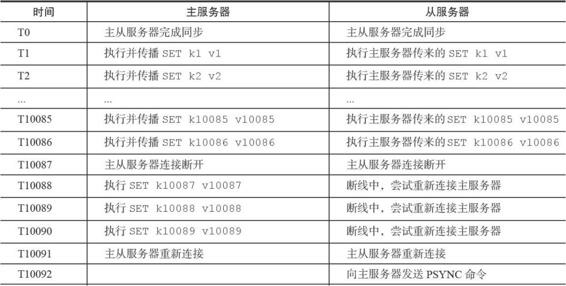
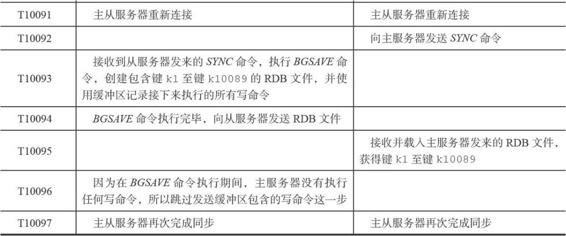
下圖展示了主從伺服器在執行部分重同步時的通訊過程。

其實看到這裡的時候心裡還是有一個疑問的:如果上面的例子是T3時候從伺服器掉線,然後在T10093的時候才連線上或者更長的時間呢!!!你這樣一條指令一條指令地傳輸過去還不如直接來一個SYNC命令快一些。所以在我看來使用PSYNC進行操作時,什麼時候部分重同步,什麼時候全部重同步是一個策略問題。當然Redis會解決這個問題,所以大家繼續看0_0
部分重同步的實現
部分重同步功能由以下三個部分構成:
- 主伺服器的複製偏移量(replication offset)和從伺服器的複製偏移量;
- 主伺服器的複製積壓緩衝區(replication backlog);
- 伺服器的執行ID(run ID)。
複製偏移量
執行復制的雙方——主伺服器和從伺服器會分別維護一個複製偏移量:
- 主伺服器每次向從伺服器傳播N個位元組的資料時,就將自己的複製偏移量的值加上N;
- 從伺服器每次收到主伺服器傳播來的N個位元組的資料時,就將自己的複製偏移量的值加上N;
(我靠!!難道從伺服器沒有反饋嗎?丟包了怎麼辦?難道是用TCP?大家繼續看,我只是想穿插一些我的思路)
通過對比主從伺服器的複製偏移量,程式可以很容易地知道主從伺服器是否處於一致狀態:
- 如果主從伺服器處於一致狀態,那麼主從伺服器兩者的偏移量總是相同的;
- 相反,如果主從伺服器兩者的偏移量並不相同,那麼說明主從伺服器並未處於一致狀態。
如下面的情況:

假設從伺服器A在斷線之後就立即重新連線主伺服器,並且成功,那麼接下來,從伺服器將向主伺服器傳送PSYNC命令,報告從伺服器A當前的複製偏移量為10086,那麼這時,主伺服器應該對從伺服器執行完整重同步還是部分重同步呢?如果執行部分重同步的話,主伺服器又如何補償從伺服器A在斷線期間丟失的那部分資料呢?以上問題的答案都和複製積壓緩衝區有關。
複製積壓緩衝區
複製積壓緩衝區是由主伺服器維護的一個固定長度(fixed-size)先進先出(FIFO)佇列,預設大小為1MB。
和普通先進先出佇列隨著元素的增加和減少而動態調整長度不同,固定長度先進先出佇列的長度是固定的,當入隊元素的數量大於佇列長度時,最先入隊的元素會被彈出,而新元素會被放入佇列。
當主伺服器進行命令傳播時,它不僅會將寫命令傳送給所有從伺服器,還會將寫命令入隊到複製積壓緩衝區裡面,如圖所示。

因此,主伺服器的複製積壓緩衝區裡面會儲存著一部分最近傳播的寫命令,並且複製積壓緩衝區會為佇列中的每個位元組記錄相應的複製偏移量,就像下表所示的那樣。

當從伺服器重新連上主伺服器時,從伺服器會通過PSYNC命令將自己的複製偏移量offset傳送給主伺服器,主伺服器會根據這個複製偏移量來決定對從伺服器執行何種同步操作:
- 如果offset偏移量之後的資料(也即是偏移量offset+1開始的資料)仍然存在於複製積壓緩衝區裡面,那麼主伺服器將對從伺服器執行部分重同步操作;
- 相反,如果offset偏移量之後的資料已經不存在於複製積壓緩衝區,那麼主伺服器將對從伺服器執行完整重同步操作。
根據需要調整複製積壓緩衝區的大小
Redis為複製積壓緩衝區設定的預設大小為1MB,如果主伺服器需要執行大量寫命令,又或者主從伺服器斷線後重連線所需的時間比較長,那麼這個大小也許並不合適。如果複製積壓緩衝區的大小設定得不恰當,那麼PSYNC命令的複製重同步模式就不能正常發揮作用,因此,正確估算和設定複製積壓緩衝區的大小非常重要。
複製積壓緩衝區的最小大小可以根據公式second*write_size_per_second來估算:
- 其中second為從伺服器斷線後重新連線上主伺服器所需的平均時間(以秒計算);
- 而write_size_per_second則是主伺服器平均每秒產生的寫命令資料量(協議格式的寫命令的長度總和);
例如,如果主伺服器平均每秒產生1 MB的寫資料,而從伺服器斷線之後平均要5秒才能重新連線上主伺服器,那麼複製積壓緩衝區的大小就不能低於5MB。
為了安全起見,可以將復制積壓緩衝區的大小設為2*second*write_size_per_second,這樣可以保證絕大部分斷線情況都能用部分重同步來處理。
至於複製積壓緩衝區大小的修改方法,可以參考配置檔案中關於repl-backlog-size選項的說明。
伺服器執行ID
除了複製偏移量和複製積壓緩衝區之外,實現部分重同步還需要用到伺服器執行ID(run ID):
- 每個Redis伺服器,不論主伺服器還是從服務,都會有自己的執行ID;
- 執行ID在伺服器啟動時自動生成,由40個隨機的十六進位制字元組成,例如53b9b28df8042fdc9ab5e3fcbbbabff1d5dce2b3;
當從伺服器對主伺服器進行初次複製時,主伺服器會將自己的執行ID傳送給從伺服器,而從伺服器則會將這個執行ID儲存起來(注意哦,是從伺服器儲存了主伺服器的ID)。
當從伺服器斷線並重新連上一個主伺服器時,從伺服器將向當前連線的主伺服器傳送之前儲存的執行ID:
- 如果從伺服器儲存的執行ID和當前連線的主伺服器的執行ID相同,那麼說明從伺服器斷線之前複製的就是當前連線的這個主伺服器,主伺服器可以繼續嘗試執行部分重同步操作;
- 相反地,如果從伺服器儲存的執行ID和當前連線的主伺服器的執行ID並不相同,那麼說明從伺服器斷線之前複製的主伺服器並不是當前連線的這個主伺服器,主伺服器將對從伺服器執行完整重同步操作。
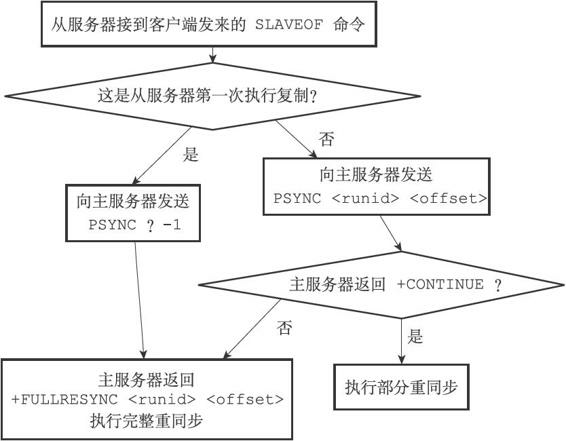
PSYNC命令的實現
PSYNC命令的呼叫方法有兩種:
- 如果從伺服器以前沒有複製過任何主伺服器,或者之前執行過SLAVEOF no one命令,那麼從伺服器在開始一次新的複製時將向主伺服器傳送PSYNC ? -1命令,主動請求主伺服器進行完整重同步(因為這時不可能執行部分重同步);
- 相反地,如果從伺服器已經複製過某個主伺服器,那麼從伺服器在開始一次新的複製時將向主伺服器傳送PSYNC <runid> <offset>命令:其中runid是上一次複製的主伺服器的執行ID,而offset則是從伺服器當前的複製偏移量,接收到這個命令的主伺服器會通過這兩個引數來判斷應該對從伺服器執行哪種同步操作。
根據情況,接收到PSYNC命令的主伺服器會向從伺服器返回以下三種回覆的其中一種:
- 如果主伺服器返回+FULLRESYNC <runid> <offset>回覆,那麼表示主伺服器將與從伺服器執行完整重同步操作:其中runid是這個主伺服器的執行ID,從伺服器會將這個ID儲存起來,在下一次傳送PSYNC命令時使用;而offset則是主伺服器當前的複製偏移量,從伺服器會將這個值作為自己的初始化偏移量;
- 如果主伺服器返回+CONTINUE回覆,那麼表示主伺服器將與從伺服器執行部分重同步操作,從伺服器只要等著主伺服器將自己缺少的那部分資料傳送過來就可以了;
- 如果主伺服器返回-ERR回覆,那麼表示主伺服器的版本低於Redis 2.8,它識別不了PSYNC命令,從伺服器將向主伺服器傳送SYNC命令,並與主伺服器執行完整同步操作。
複製的實現
步驟1:設定主伺服器的地址和埠
當客戶端向從伺服器傳送以下命令時:
127.0.0.1:12345> SLAVEOF 127.0.0.1 6379
OK
從伺服器首先要做的就是將客戶端給定的主伺服器IP地址127.0.0.1以及埠6379儲存到伺服器狀態的masterhost屬性和masterport屬性裡面:
struct redisServer {
// ...
// 主伺服器的地址
char *masterhost;
// 主伺服器的埠
int masterport;
// ...
};
SLAVEOF命令是一個非同步命令,在完成masterhost屬性和masterport屬性的設定工作之後,從伺服器將向傳送SLAVEOF命令的客戶端返回OK,表示複製指令已經被接收,而實際的複製工作將在OK返回之後才真正開始執行。
步驟2:建立套接字連線
在SLAVEOF命令執行之後,從伺服器將根據命令所設定的IP地址和埠,建立連向主伺服器的套接字連線,如圖15-14所示。

如果從伺服器建立的套接字能成功連線(connect)到主伺服器,那麼從伺服器將為這個套接字關聯一個專門用於處理複製工作的檔案事件處理器,這個處理器將負責執行後續的複製工作,比如接收RDB檔案,以及接收主伺服器傳播來的寫命令,諸如此類。
而主伺服器在接受(accept)從伺服器的套接字連線之後,將為該套接字建立相應的客戶端狀態,並將從伺服器看作是一個連線到主伺服器的客戶端來對待,這時從伺服器將同時具有伺服器(server)和客戶端(client)兩個身份:從伺服器可以向主伺服器傳送命令請求,而主伺服器則會向從伺服器返回命令回覆。
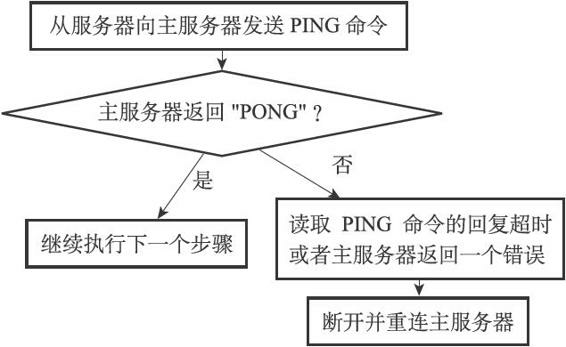
步驟3:傳送PING命令
從伺服器成為主伺服器的客戶端之後,做的第一件事就是向主伺服器傳送一個PING命令。
這個PING命令主要是為了:
- 通過傳送PING命令檢查套接字的讀寫狀態;
- 通過PING命令可以檢查主伺服器能否正常處理命令。
從伺服器在傳送PING命令之後可能遇到以下三種情況:
- 主伺服器向從伺服器返回了一個命令回覆,但從伺服器卻不能在規定的時限內讀取命令回覆的內容(timeout),說明網路連線狀態不佳,從伺服器將斷開並重新建立連向主伺服器的套接字;
- 如果主伺服器返回一個錯誤,那麼表示主伺服器暫時沒有辦法處理從伺服器的命令請求,,從伺服器也將斷開並重新建立連向主伺服器的套接字;
- 如果從伺服器讀取到"PONG"回覆,那麼表示主從伺服器之間的網路連線狀態正常,那就繼續執行下面的複製步驟。
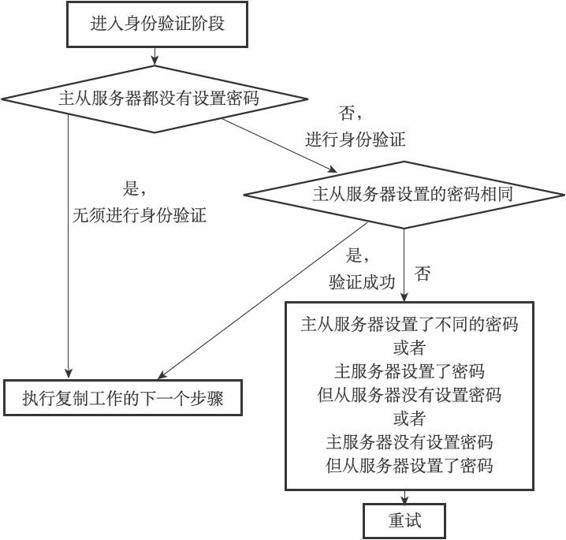
步驟4:身份驗證
從伺服器在收到主伺服器返回的"PONG"回覆之後,下一步要做的就是決定是否進行身份驗證:
- 如果從伺服器設定了masterauth選項,那麼進行身份驗證。否則不進行身份認證;
在需要進行身份驗證的情況下,從伺服器將向主伺服器傳送一條AUTH命令,命令的引數為從伺服器masterauth選項的值。
從伺服器在身份驗證階段可能遇到的情況有以下幾種:
- 主伺服器沒有設定requirepass選項,從伺服器沒有設定masterauth,那麼就繼續後面的複製工作;
- 如果從伺服器的通過AUTH命令傳送的密碼和主伺服器requirepass選項所設定的密碼相同,那麼也繼續後面的工作,否則返回錯誤invaild password;
- 如果主伺服器設定了requireoass選項,但從伺服器沒有設定masterauth選項,那麼伺服器將返回NOAUTH錯誤。反過來如果主伺服器沒有設定requirepass選項,但是從伺服器卻設定了materauth選項,那麼主伺服器返回no password is set錯誤;
所有錯誤到只有一個結果:中止目前的複製工作,並從建立套接字開始重新執行復制,直到身份驗證通過,或者從伺服器放棄執行復製為止。
步驟5:傳送埠資訊
身份驗證步驟之後,從伺服器將執行命令REPLCONF listening-port <port-number>,向主伺服器傳送從伺服器的監聽埠號。
主伺服器在接收到這個命令之後,會將埠號記錄在從伺服器所對應的客戶端狀態的slave_listening_port屬性中:
typedef struct redisClient {
// ...
// 從伺服器的監聽埠號
int slave_listening_port;
// ...
}redisClient;
slave_listening_port屬性目前唯一的作用就是在主伺服器執行INFO replication命令時打印出從伺服器的埠號。
步驟6:同步
在這一步,從伺服器將向主伺服器傳送PSYNC命令,執行同步操作,並將自己的資料庫更新至主伺服器資料庫當前所處的狀態。
需要注意的是在執行同步操作前,只有從伺服器是主伺服器的客戶端。但是執行從不操作之後,主伺服器也會稱為從伺服器的客戶端:
- 如果PSYNC命令執行的是完整同步操作,那麼主伺服器只有成為了從伺服器的客戶端才能將儲存在緩衝區中的寫命令傳送給從伺服器執行;
- 如果PSYNC命令執行的是部分同步操作,那麼主伺服器只有成為了從伺服器的客戶端才能將儲存在複製積壓緩衝區中的寫命令傳送給從伺服器執行;
步驟7:命令傳播
當完成了同步之後,主從伺服器就會進入命令傳播階段,這時主伺服器只要一直將自己執行的寫命令傳送給從伺服器,而從伺服器只要一直接收並執行主伺服器發來的寫命令,就可以保證主從伺服器一直保持一致了。
心跳檢測
在命令傳播階段,從伺服器預設會以每秒一次的頻率,向主伺服器傳送命令:REPLCONF ACK <replication_offset>
其中replication_offset是從伺服器當前的複製偏移量。
傳送REPLCONF ACK命令對於主從伺服器有三個作用:
- 檢測主從伺服器的網路連線狀態;
- 輔助實現min-slaves選項;
- 檢測命令丟失。
檢測主從伺服器的網路連線狀態
如果主伺服器超過一秒鐘沒有收到從伺服器發來的REPLCONF ACK命令,那麼主伺服器就知道主從伺服器之間的連接出現問題了。
通過向主伺服器傳送INFO replication命令,在列出的從伺服器列表的lag一欄中,我們可以看到相應從伺服器最後一次向主伺服器傳送REPLCONF ACK命令距離現在過了多少秒:
127.0.0.1:6379> INFO replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=12345,state=online,offset=211,lag=0
#剛剛傳送過 REPLCONF ACK命令
slave1:ip=127.0.0.1,port=56789,state=online,offset=197,lag=15
#15秒之前傳送過REPLCONF ACK命令
master_repl_offset:211
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:210
在一般情況下,lag的值應該在0秒或者1秒之間跳動,如果超過1秒的話,那麼說明主從伺服器之間的連接出現了故障。
輔助實現min-slaves配置選項
Redis的min-slaves-to-write和min-slaves-max-lag兩個選項可以防止主伺服器在不安全的情況下執行寫命令。
舉個例子,如果我們向主伺服器提供以下設定:
min-slaves-to-write 3
min-slaves-max-lag 10
那麼在從伺服器的數量少於3個,或者三個從伺服器的延遲(lag)值都大於或等於10秒時,主伺服器將拒絕執行寫命令,這裡的延遲值就是上面提到的INFO replication命令的lag值。
檢測命令丟失
我們從命令:REPLCONF ACK <replication_offset>就可以知道,每傳送一次這個命令從伺服器都會向主伺服器報告一次自己的複製偏移量。那此時儘管主伺服器傳送給從伺服器的SET key value丟失了。也無所謂,主伺服器馬上就知道了。