
Spark SQL 筆記(1)—— Hive
阿新 • • 發佈:2018-11-06
1 大資料入門
- 學習 Hadoop ,Hive 的使用
- 學習 Spark
- DataFrame 和 DataSet 在 Spark 框架中的核心地位
2 Hive
2.1 hive 產生的背景
- MapReduce 程式設計的不便性;
- HDFS 上的檔案缺少 Schema;
2.2 Hive 是什麼
- 通常用於進行離線資料處理(採用MapReduce)
- 底層支援多種不同的執行引擎(MapReduce,Tez,Spark)
- 支援多種不同的壓縮格式、儲存格式以及自定義函式
- 壓縮:GZIP,LZO,Snappy,BZIP2…
- UDF : 自定義函式
2.3 Hive 體系架構
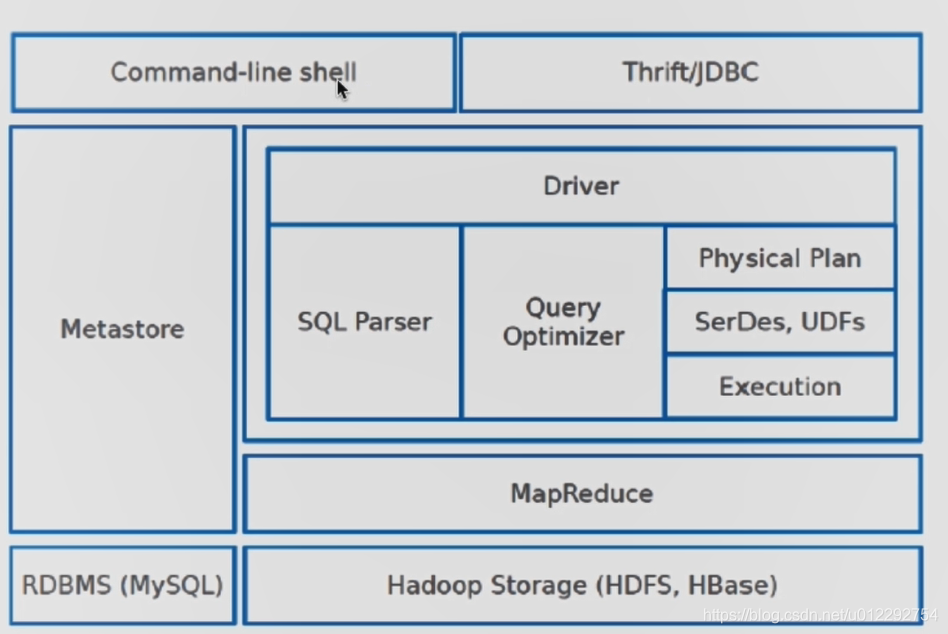
2.4 Hive 測試環境
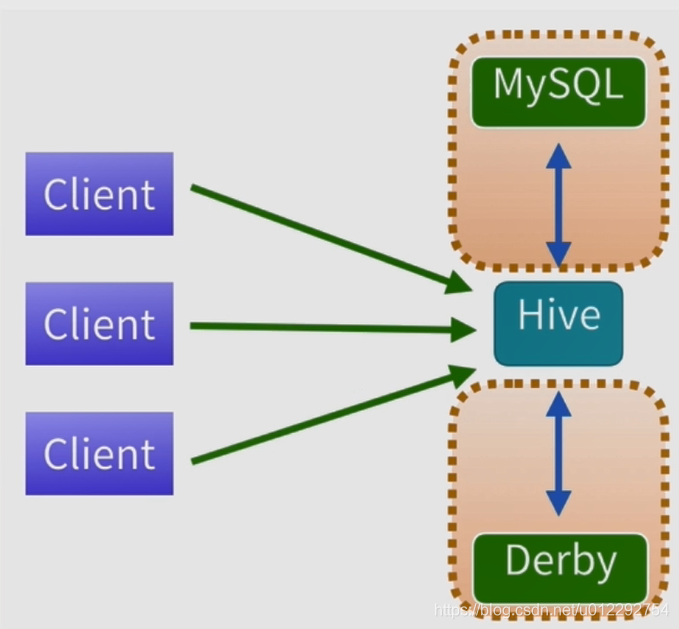
2.5 Hive 生產環境
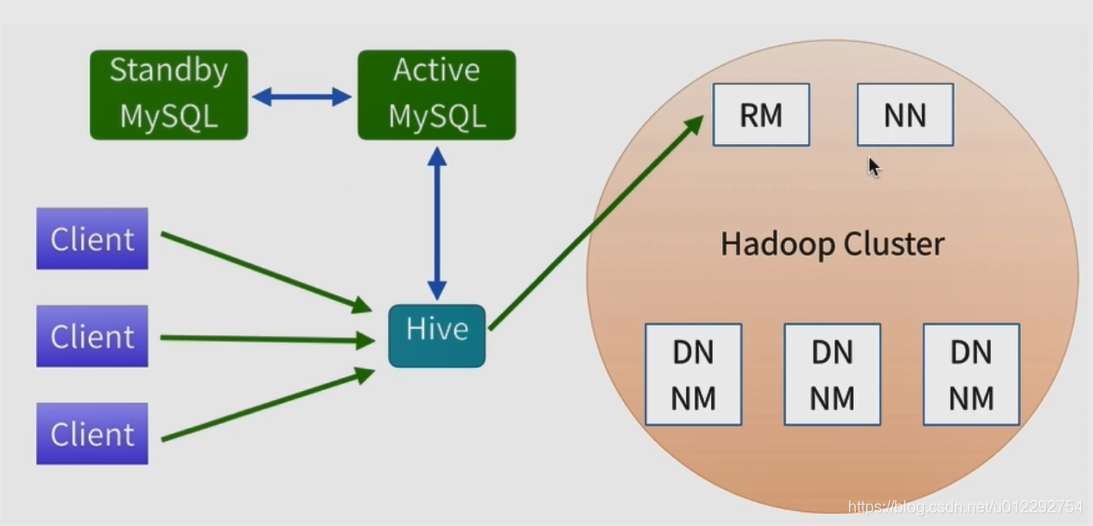
3 Hive 安裝
hive-1.1.0-cdh5.7.0.tar.gz
3.1 解壓
tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C /home/hadoop/apps
3.2 配置 Hive
參考 https://cwiki.apache.org/confluence/display/Hive/GettingStarted
3.2.1 配置環境變數
export HIVE_HOME=/home/hadoop/apps/hive-1.1.0-cdh5.7.0 export PATH=$PATH:$HIVE_HOME/bin
3.2.2 hive-env.sh
/home/hadoop/apps/hive-1.1.0-cdh5.7.0/conf
HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.0-cdh5.7.0
3.2.3 新建一個 hive-site.xml
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/sparksql?createDatabaseIfNotExist=true&useSSL=false</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> </configuration>
3.2.4 將mysql 驅動放到 lib 目錄
下載地址 https://dev.mysql.com/downloads/connector/j/5.1.html
4 測試
4.1 登入 mysql
[[email protected] ~]$ mysql -uroot -proot
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 4
Server version: 5.7.10 MySQL Community Server (GPL)
Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sparksql |
| sys |
+--------------------+
5 rows in set (0.03 sec)
mysql> use sparksql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sparksql |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql> show tables;
+---------------------------+
| Tables_in_sparksql |
+---------------------------+
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| DATABASE_PARAMS |
| DBS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| PART_COL_STATS |
| ROLES |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SKEWED_COL_NAMES |
| SKEWED_COL_VALUE_LOC_MAP |
| SKEWED_STRING_LIST |
| SKEWED_STRING_LIST_VALUES |
| SKEWED_VALUES |
| SORT_COLS |
| TABLE_PARAMS |
| TAB_COL_STATS |
| TBLS |
| VERSION |
+---------------------------+
28 rows in set (0.00 sec)
mysql> select * from TBLS;
Empty set (0.00 sec)
5 練習
先啟動 hadoop 叢集
啟動hive ,命令列輸入 hive
5.1 建立表
hive> create table hive_wordcount(context string);
OK
Time taken: 0.593 seconds
hive> show tables;
OK
hive_wordcount
Time taken: 0.114 seconds, Fetched: 1 row(s)
hive>
切換到 mysql 資料庫檢視
[[email protected] ~]$ mysql -uroot -proot
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 54
Server version: 5.7.10 MySQL Community Server (GPL)
Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sparksql |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql> use sparksql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+---------------------------+
| Tables_in_sparksql |
+---------------------------+
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| DATABASE_PARAMS |
| DBS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| PARTITIONS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| PART_COL_STATS |
| ROLES |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SKEWED_COL_NAMES |
| SKEWED_COL_VALUE_LOC_MAP |
| SKEWED_STRING_LIST |
| SKEWED_STRING_LIST_VALUES |
| SKEWED_VALUES |
| SORT_COLS |
| TABLE_PARAMS |
| TAB_COL_STATS |
| TBLS |
| VERSION |
+---------------------------+
29 rows in set (0.00 sec)
mysql> select * from TBLS;
+--------+-------------+-------+------------------+--------+-----------+-------+----------------+---------------+--------------------+--------------------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT |
+--------+-------------+-------+------------------+--------+-----------+-------+----------------+---------------+--------------------+--------------------+
| 1 | 1540994772 | 1 | 0 | hadoop | 0 | 1 | hive_wordcount | MANAGED_TABLE | NULL | NULL |
+--------+-------------+-------+------------------+--------+-----------+-------+----------------+---------------+--------------------+--------------------+
1 row in set (0.00 sec)
mysql>
mysql> select * from COLUMNS_V2;
+-------+---------+-------------+-----------+-------------+
| CD_ID | COMMENT | COLUMN_NAME | TYPE_NAME | INTEGER_IDX |
+-------+---------+-------------+-----------+-------------+
| 1 | NULL | context | string | 0 |
+-------+---------+-------------+-----------+-------------+
1 row in set (0.00 sec)
5.2 資料匯入表
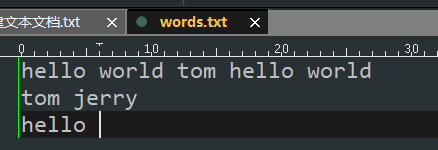
hive> load data local inpath '/home/hadoop/words.txt' into table hive_wordcount;
Loading data to table default.hive_wordcount
Table default.hive_wordcount stats: [numFiles=1, totalSize=46]
OK
Time taken: 1.223 seconds
檢視匯入結果
hive> select * from hive_wordcount;
OK
hello world tom hello world
tom jerry
hello
Time taken: 0.293 seconds, Fetched: 3 row(s)
5.3 統計
lateral view explode() ------ 每行記錄按照指定的分隔符拆解
hive> select word,count(1) from hive_wordcount lateral view explode(split(context,' ')) wc as word group by word;
Query ID = hadoop_20181031220606_a8bd43d1-8706-408f-a293-8d65428fcd43
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1540991507430_0001, Tracking URL = http://node1:8088/proxy/application_1540991507430_0001/
Kill Command = /home/hadoop/apps/hadoop-2.6.0-cdh5.7.0/bin/hadoop job -kill job_1540991507430_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-10-31 22:21:58,691 Stage-1 map = 0%, reduce = 0%
2018-10-31 22:22:08,281 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.79 sec
2018-10-31 22:22:15,572 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.94 sec
MapReduce Total cumulative CPU time: 2 seconds 940 msec
Ended Job = job_1540991507430_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.94 sec HDFS Read: 8788 HDFS Write: 33 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 940 msec
OK
1
hello 3
jerry 1
tom 2
world 2
Time taken: 30.297 seconds, Fetched: 5 row(s)