手勢識別論文解讀
- Learning to Estimate 3D Hand Pose from Single RGB Images20173
- Two-Stream Convolutional Networks for Action Recognition in Videos2014
- Convolutional Two-Stream Network Fusion for Video Action Recognition2015
- Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D Convolutional Neural Networks201611
- Realtime Multi-Person 2D Human Pose Estimation using Part Affinity Fields20166
- Convolutional Pose Machines2016
- Model-based Deep Hand Pose Estimation2016
- Multimodal Gesture Recognition Using 3D Convolution and Convolutional LSTM20173
- VideoLSTM Convolves Attends and Flows for Action Recognition20167
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition20146
- Gesture Recognition with a Convolutional Long Short-Term Memory Recurrent Neural Network2016
- Real time gesture recognition using Continuous Time Recurrent Neural Networks
《Learning to Estimate 3D Hand Pose from Single RGB Images》2017.3
本文介紹了從2D彩色影象進行3D hand pose estimation的一種方法,總體來說方法很直觀
project page
主要流程
如圖所示,依次有以下幾個環節:
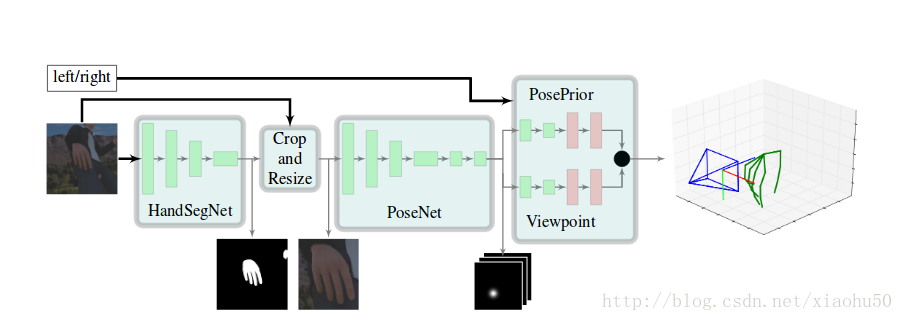
- 1)HandSegNet, 輸入256x256x3, 輸出256x256x1的一個hand mask。用一個FCN網路進行手的語義分割,分割之後的結果用來對手附近區域進行截圖,以減少計算量及提高準確性
- 2)PoseNet,用來計算手的21個keypoint, 輸入256x256x3,輸出32x32x21, 即21張不同keypoint的score map
- 3)PosePrior,有兩個子stream,每個的網路結構除了最後一層不一樣其他都一樣,輸入32x32x21,輸出兩個層。一個是正則化的手的座標,以手掌的點為原點,且長度進行了normalize, 即維度為21x3。另一個是相對於實際圖片的空間的變換關係,即維度為3
在論文中還用這個結構進行了手語識別,手語識別的網路直接根據手的指示來, 是一個3層的全連線網路,輸入維度63, 輸出維度35
程式碼細節解讀
使用自帶的工具tfprof進行效能分析,發現主要的耗時在於, 2/3耗時在single_obj_scoremap中的tf.nn.dilation2d操作, 1/6耗時在HandSegNet,1/6耗時在PoseNet2D。
同時,為了複用前人訓練好的網路引數,將手部截圖重新上取樣到256x256來使用PoseNet。可見整個網路還有很大的優化空間。cpu上做到實時也不是沒有希望。
訓練流程解讀
《Two-Stream Convolutional Networks for Action Recognition in Videos》2014
框架
如上圖所示,採用兩個stream,一個用靜態的單張圖片來分類,另一個stream用累積的多張圖片的資訊來分類
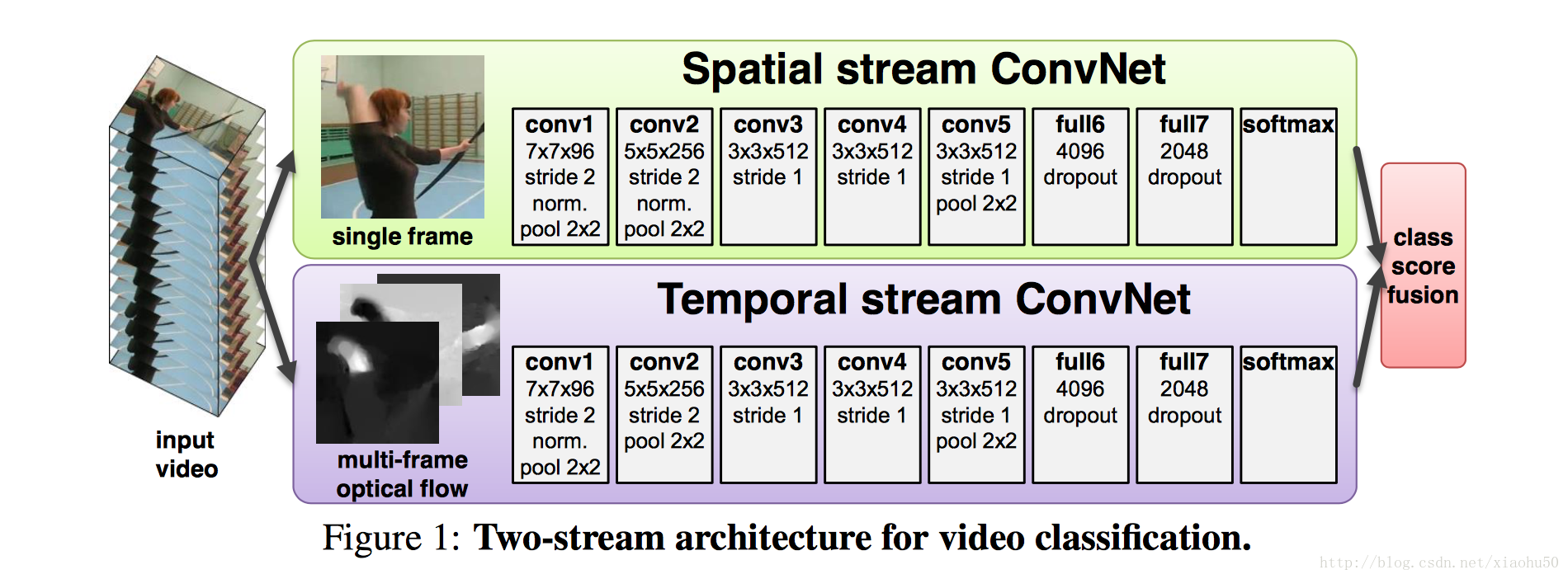
兩個stream
Spatial stream ConvNet
非常直觀,直接用每張圖片過cnn
Optical flow ConvNets
文中提到了兩種方法,一種是光流Optical flow stacking,一種是軌跡Trajectory stacking
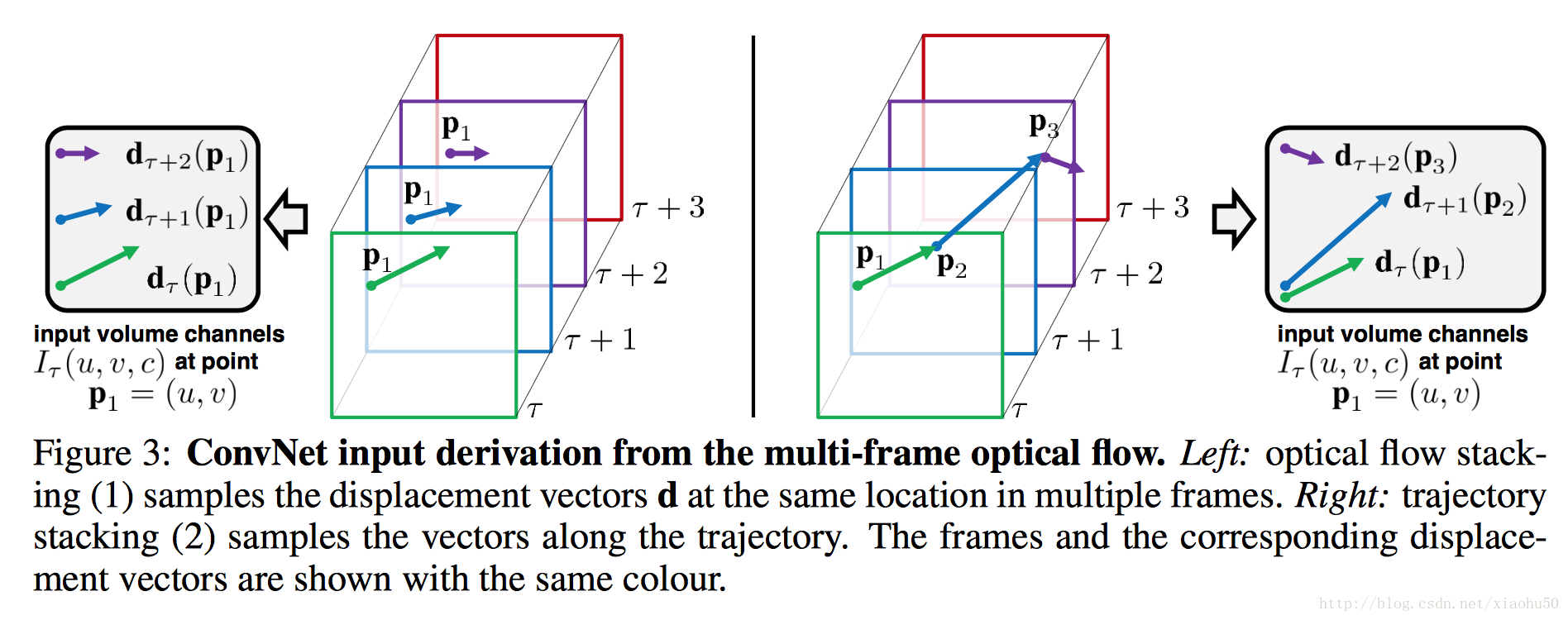
- 光流採用x,y兩個方向的光流,顧如果stack一共L張圖片的資訊,則有2L張的光流圖
- 軌跡也分x,y的兩張圖,但是區別是軌跡追蹤的是同個點在不同幀上的位移,個人感覺沒啥區別,對框架沒有影響。
文中還討論了一些方便用在學習中的特徵,可以參考一下
train要點
- 對於Spatial stream ConvNet, 可以在imageNet等大資料集上進行訓練
- 對於Optical flow ConvNets, 需要在video資料集上訓練,文中用了UCF-101 ,HMDB-51這兩個,如果你直接採用著兩個資料集,需要手工去重,防止某些動作特別多照成過擬合, 文中提到了multi-task learning這種方法。參考《A unified architecture for natural language processing: deep neural networks with multitask learning》
《Convolutional Two-Stream Network Fusion for Video Action Recognition》2015
code
這篇文章主要是在《Two-Stream Convolutional Networks for Action Recognition in Videos》的基礎上進行改進。主要針對其中的兩個缺點:
* spatial 和 temporal 的feature沒有在pixel層面上進行合作,只用了最後的score
* temporal的操作基本還是基於2d的conv
核心在於引入3d-conv , 3d-pooling,以及對網路結構進行fusion
框架
TODO
《Online Detection and Classification of Dynamic Hand Gestures with Recurrent 3D Convolutional Neural Networks》2016.11
這篇文章的思路就不一樣,它主要在於訓練一個end-to-end的手勢識別結果,不進行具體的hand pose estimation。從視訊效果來看也不錯
大道至簡,對於近距離的手勢識別,覺得這個方案應該是目前比較靠譜的。
project page
框架
如上圖所示基本框架很簡單
3D-CNN + RNN + Softmax + CTC loss
文中採用了多模態資料,比如RGB,深度,紅外,光流,但本身基於單資料來源也效果很好
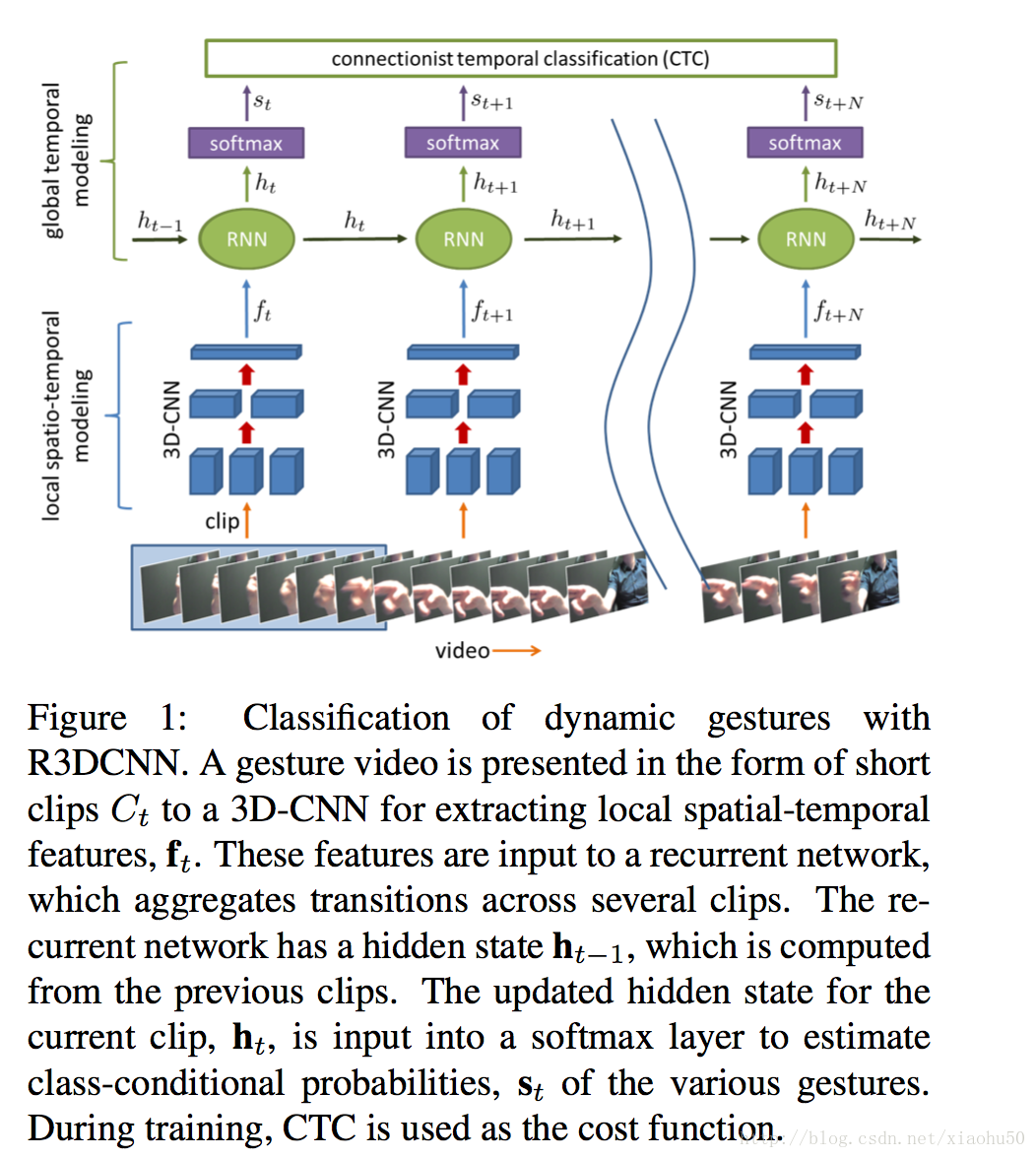
細節
資料來源
在 project page上,有他們自制的訓練資料,大概30G,包含25個預定義動作,20個訓練人員,10秒不到的短視訊,每個視訊一個動作,視訊中包含無動作開始+動作+無動作結尾。除此之外,在訓練過程中還做了data augment,比如從120x160的尺寸中隨機取112x112大小的資料,還有random spatial rotation (±15◦) and scal- ing (±20%), temporal scaling (±20%), and jittering (±3 frames).
3D-CNN
經過測試他們選取了一個clip 8幀來兼顧效能和速度,3D-CNN使用pretrain自C3D的一個比較大的運動資料集。然後在pretrain的weights的基礎上直接加softmax算cross entropy的loss來fine tune 3D-CNN的引數。
用了8層conv和2層的全連線。
RNN
在準備好3D-CNN之後,加上RNN,用back-propagation-through-time(BPTT)來做gradient descent就行了。需要注意的是,在訓練的過程中,我們主要考慮兩個loss
- cross entropy的loss, 用在entire video上,每段視訊按照其中的概率的平均來算
- CTC(Connectionist temporal classification)的loss,用在online sequence。由於需要在分類結果中新增一個{no gesture}的類別,如果用在segmented video的分類時,需要去掉這歌類(因為視訊總屬於某個類)
CTC常用在NLP當中,解決的問題是連續訓練的時候不好標資料的問題。比如一段”This is a new world”的語音辨識訓練樣本,往往不能或者代價太大去辨識出具體哪個字母或者音素在什麼位置出現或者終結,CTC提供了一種統計方法,只需要給整體進行標註,並不需要對具體的字母進行標註。
文中使用了CTC forward algorithm(當然對應的,也有backward的方法),具體演算法可以看相關論文,主要在於動態規劃圖的理解。
在添加了CTC之後,給原先的類別新增一個{no gesture}的類別,這樣子,CTC就能對連續的動作進行標註,其loss為
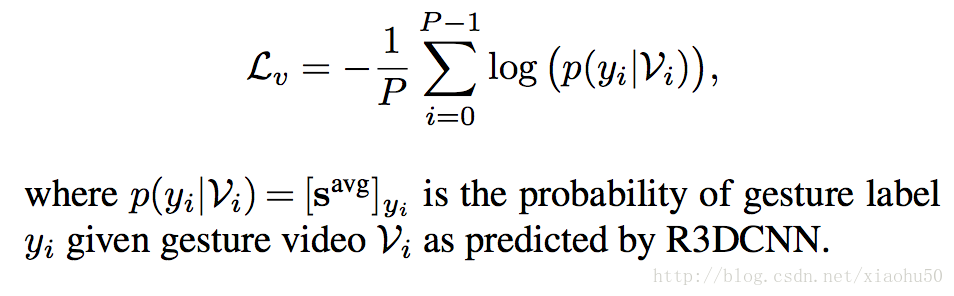
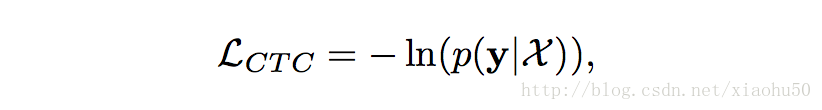
實現
先說下最終test的效果,112x112x3的大小,在nvidia TitanX上面但clip 8幀的情況下,單次耗時30ms左右。可以說,還不錯,但是conv感覺太深,可能沒有必要。
具體流程如下
- 16 epoch對3D-CNN進行fine tune
- 100 epoch加上RNN,用CTC的loss來訓練就可以
《Realtime Multi-Person 2D Human Pose Estimation using Part Affinity Fields》2016.6
目標
多人同時Pose Estimation, 如下圖所示

框架
分兩個部分,檢測部分和匹配部分,如下圖所示
(b)關鍵點檢測,(c)part affinity fields即四肢關係檢測,(d)二分圖匹配

檢測部分
如下圖所示,上下分為兩個brach,分別用來檢測關鍵點 Part Confidence Maps 以及 四肢關係Part Affinity Fields
分stage的思路和《Convolutional Pose Machines》一致(畢竟是一個團隊)。其中的F來自於VGG-19的前十層finetuned的結果,對於stages t>=2, 每個branch的輸入都是
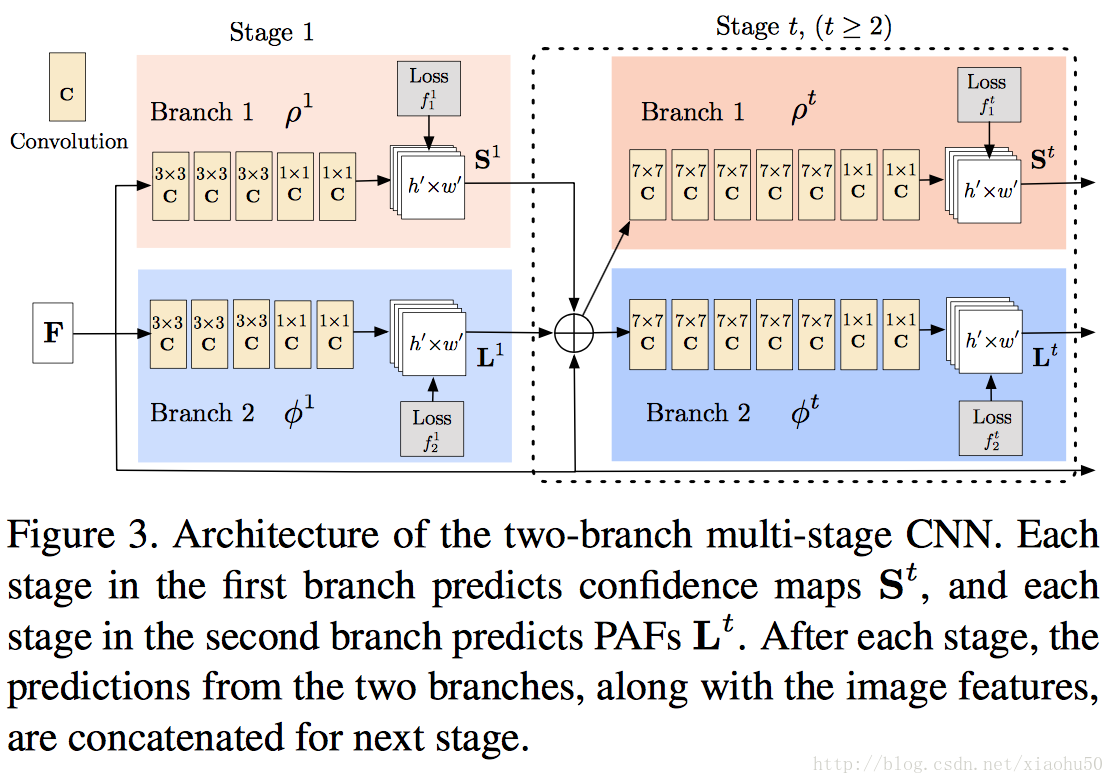
F,St−1,Lt−1
的聯合,即
類似於《Convolutional Pose Machines》,計算每層的loss為
其中的W(p)代表本該存在的單位是否在groud true中存在(有些關節或者四肢沒有標註)。而對應的total loss為
注意Part Affinity Fields(PAF)是一些向量區域,可以通過指定四肢粗細然後在訓練資料中根據關節點來標註。
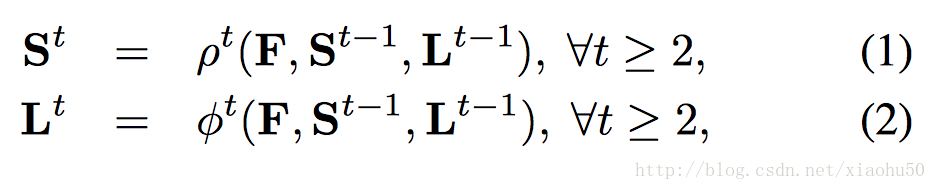
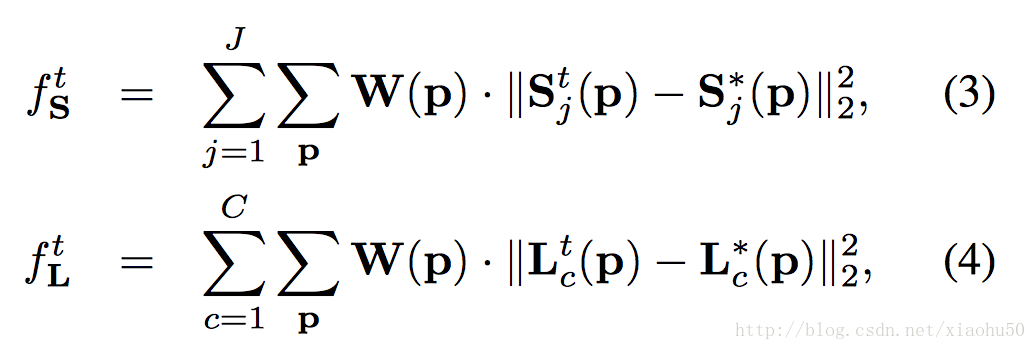
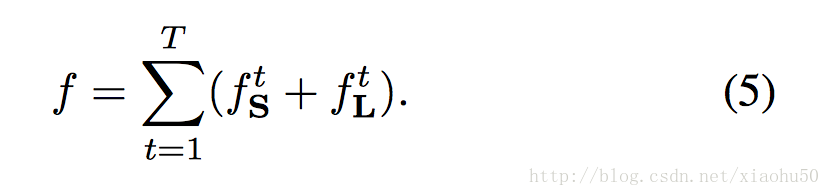
匹配部分
這裡首先要明確 Part Confidence Maps和PAF是如何協同確定四肢和關節的預測的
如上圖,對於圖中的任意點P,在PAF的對應點的投影可以用來表示該點在四肢上的相關性。對於 Part Confidence Maps中任意的兩個極值點A,B,可以通過插值A,B中的幾個點p0, p1, p2, p3, p4…求這些點在PAF上的投影的積分來確定A,B兩點作為同肢節的關節點的可能性,如下圖
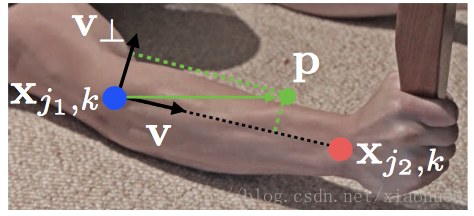
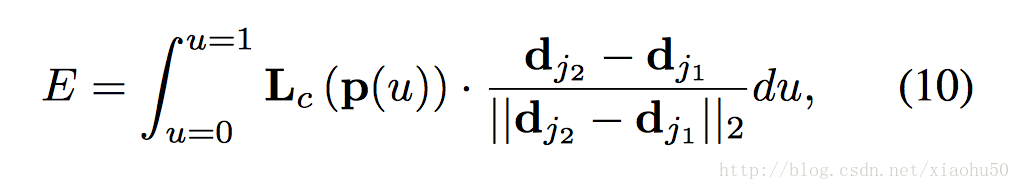
有了上面的兩點同肢節判定的方法,我們就可以通過匹配每組能相連的點來決定連線與點的有效性。即通過右手腕的confidence map 和右手肘的confidence map的極值點之間的二分圖匹配問題
其中
用來表示兩個關節點是否相連。這個問題可以用Hungarian algorithm來解決,相對的總體的error,可以通過簡單的相加來衡量
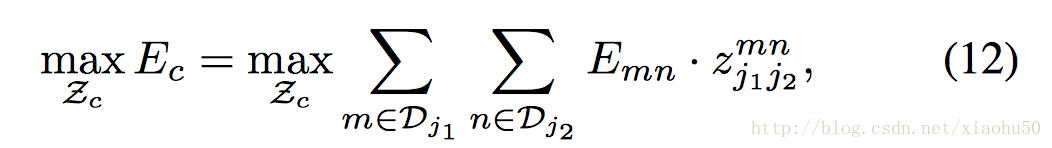
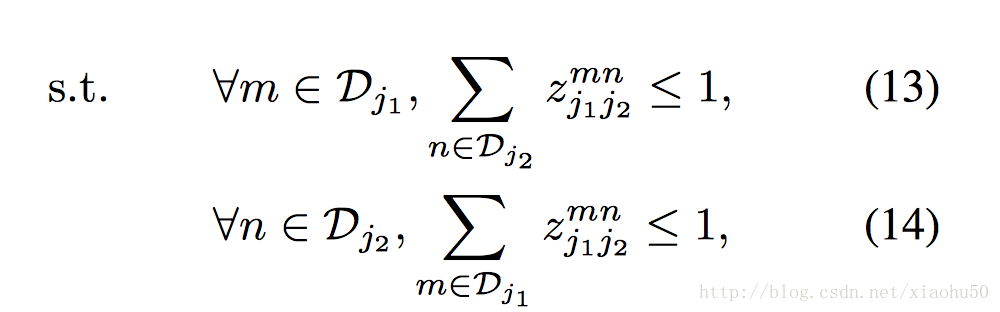
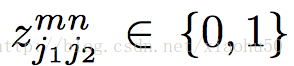

兩個子問題:
-
non-maximum suppression非極大值抑制
定義:處理一份資料,講非極大值的部分設定為0,是不是非常直觀^^
實現:常見的高效演算法可以參見 ICPR2006-《Efficient Non-Maximum Suppression》,核心是減少重複比較
應用:檢測演算法中常見,本質是從眾多的滑動視窗的sore中找到區域性極值作為檢測結果。參見很不錯的人臉檢測的NMS例子 -
Hungarian algorithm
目標:解決二分圖的最大匹配問題 or 任務分配問題,用在文中是解決不同關鍵點之間的同肢體匹配問題
《Convolutional Pose Machines》2016
目標
實現關鍵部位的檢測,生成scoremap,如下圖所示

框架
常規的思路類似FCN,但是由於網路層數變深會有不好訓練的問題。文章的重點在於分stage來訓練,每個stage的結果目標都是最終的score map,通過把原圖的feature和上一個stage的輸出一起傳遞到下個stage作為輸入,來實現迭代。注意下圖中的x’這個網路的權重在所有的stages t>=2中都是共享的,用來提取影象的feature
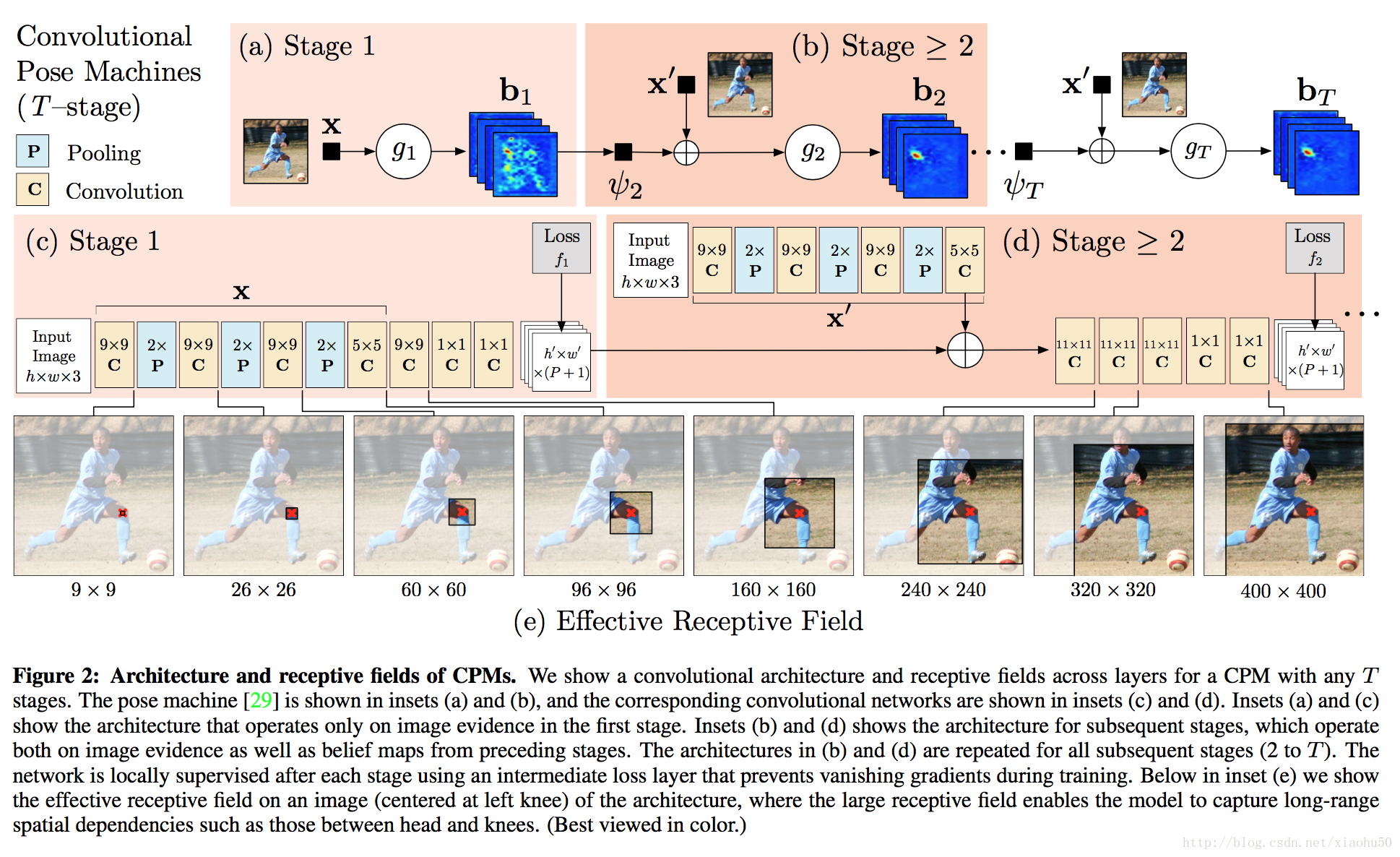
要點
- 通過分階段stage的方式,用來迭代並擴大receptive field,每個stage都可量化以及視覺化
- 由於總體網路層數教深,很容易出現gradient vanish的問題, 由於每個stage的輸出都可以計算loss,如下,ground true未真實位置點的高斯分佈的max
, 同時,total loss 為每層loss的和
。即文中所謂的Intermediate supervision,每層的gradient都有部份來自於當層的loss。End-to-end learning。
TODO: 不懂如果用了上面的loss卻不intermediate supervision的方法
《Model-based Deep Hand Pose Estimation》2016
model-based的方法可以有效的利用手的先驗知識,如下圖所示:  注:上圖中的拇指部分的關節標錯了,下移一節應該才正確
主要流程
- 應用於深度圖首先用檢測演算法截圖,使手在影象中間並resize到128x128
- CNN網路用來學習關節26個角度值,這裡將會計算一個loss
- 通過Hand Model layer將角度值變換成關節點的座標,座標也會計算一個loss
流程圖如下: 
Loss
Loss分為兩部分: 一個是最終的Joint Locations的一個Loss  另一個是在計算關節角度值之後根據生理學模型或者統計求得的每個角度的角度範圍,然後用這個合理範圍作一個penalty  Total loss就是上面兩個loss的係數相加 
要點與改進點
- 上面第一個loss是joint locations的一個loss,其實還可以直接對關節角度進行regression的loss的比較,效果在文中沒有比較。從我的理解來看可能會稍微好一點。因為joint locations的loss雖然GT的location本身是獨立的,但是prediect的資料卻是有關節角度累計變換來的。而如果採用關節角度regression的loss的話,predict的角度值是互相獨立的。
- 對於Joint Locations的loss其實更大的依賴全域性的變換(即手掌相對於影象原點的平移和旋轉),以及手指的骨長等引數。全域性變換在演算法中不予考慮,全當隨機誤差應該會顯著影響學習,手指的骨長這裡是通過測試資料來統計並固定的,實際上的誤差可能很大
- 上面的問題中,全域性變換可以通過一個joint locations的中心來歸一化,手指的骨長則可能需要產品話的時候需要像錄入指紋一樣對骨長資料進行調整。
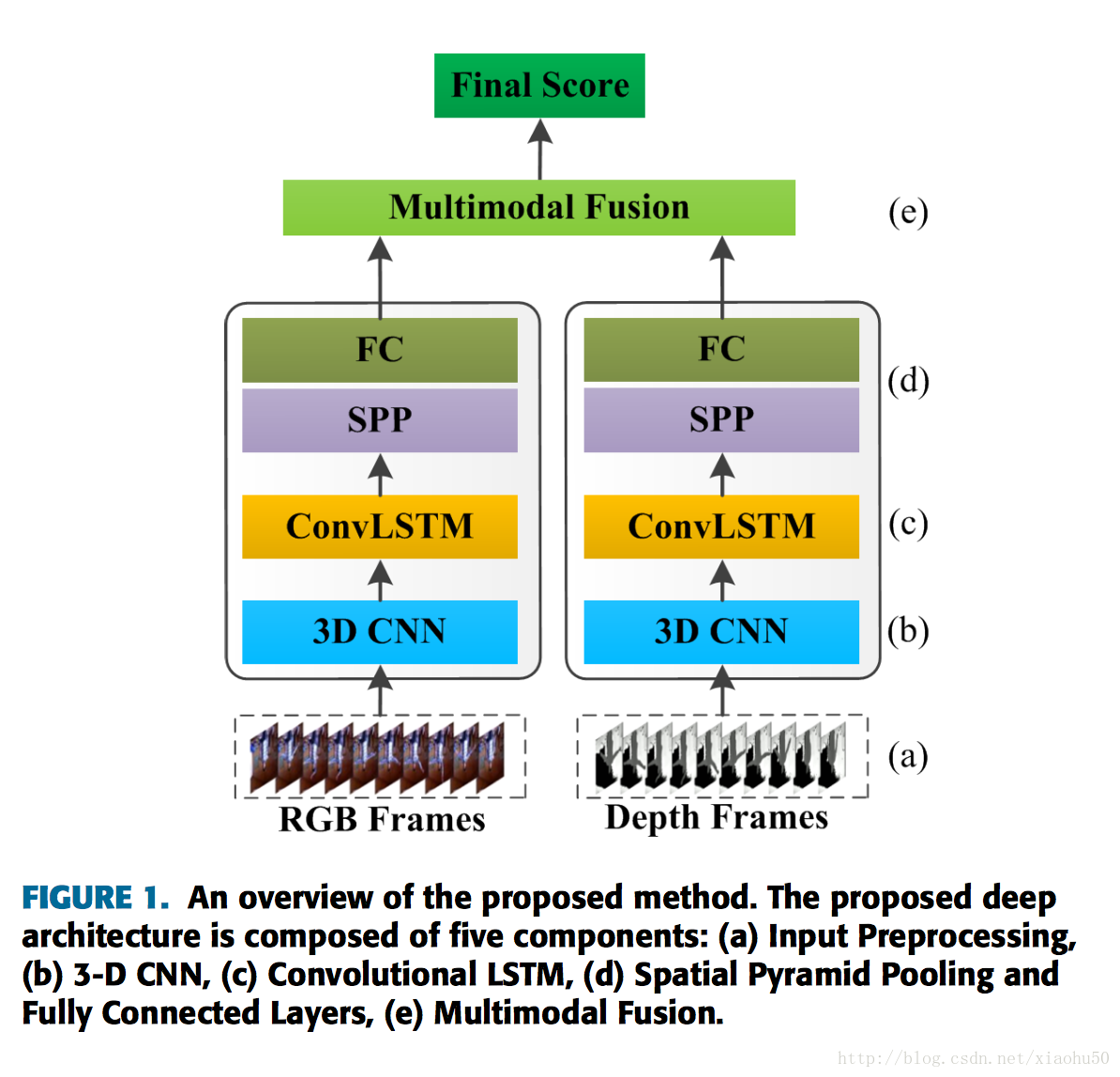
《Multimodal Gesture Recognition Using 3D Convolution and Convolutional LSTM》2017.3
這文章其實沒有啥新意,不過有程式碼,而且引用了一些不錯的文章。這篇文章是採用將動作序列取樣到標準長度,更好的替代方法是採用ctc
框架
兩個steam,分別處理RGB的影象和Depth影象
其中每個子stream的框架如下:
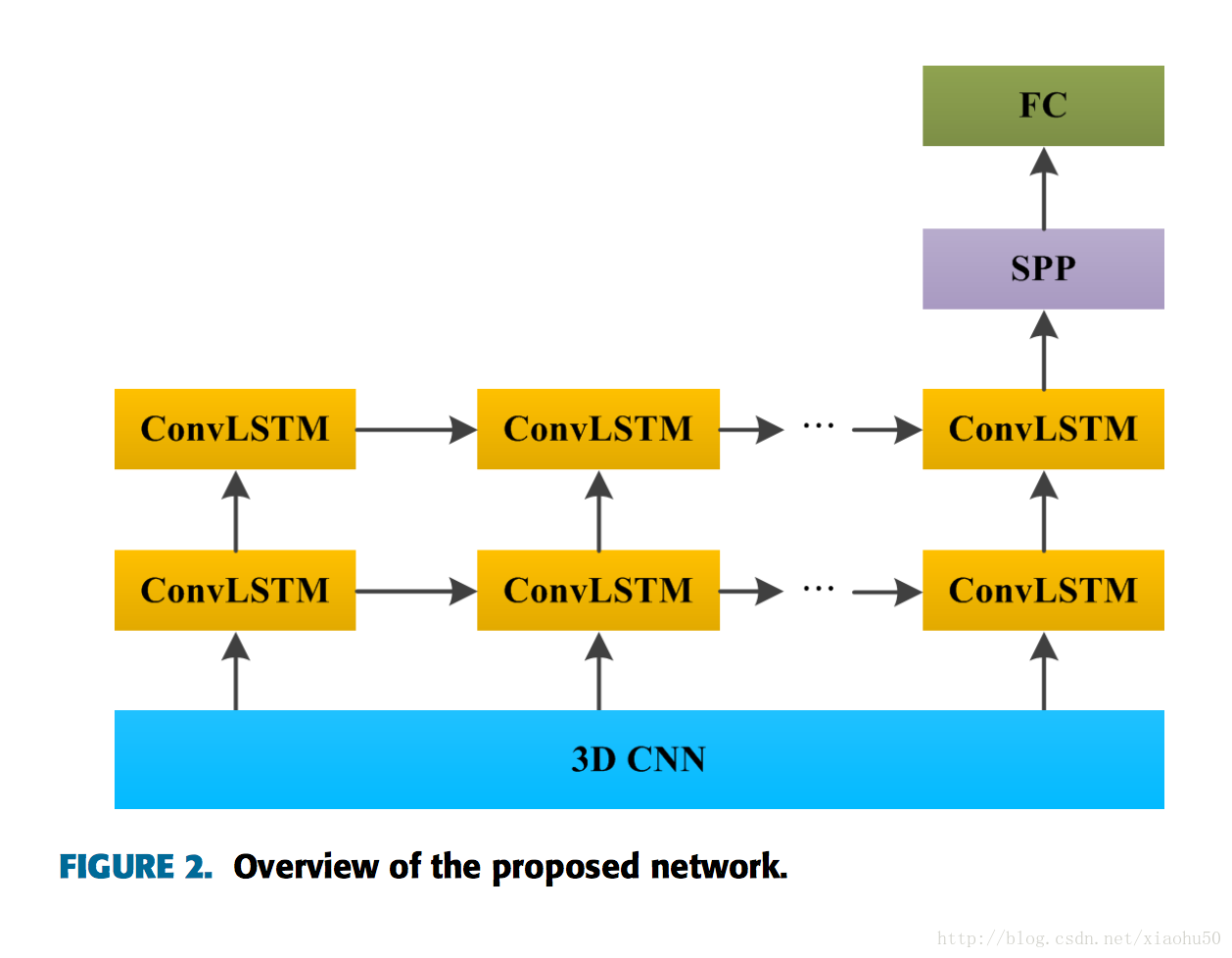
值得一提的子模組
convolutional LSTM
在常規的LSTM中,上面的 * 是矩陣乘法,而convolutional LSTM中,上面的X,H都是二維資料(類似影象),* 也變成了convolution操作
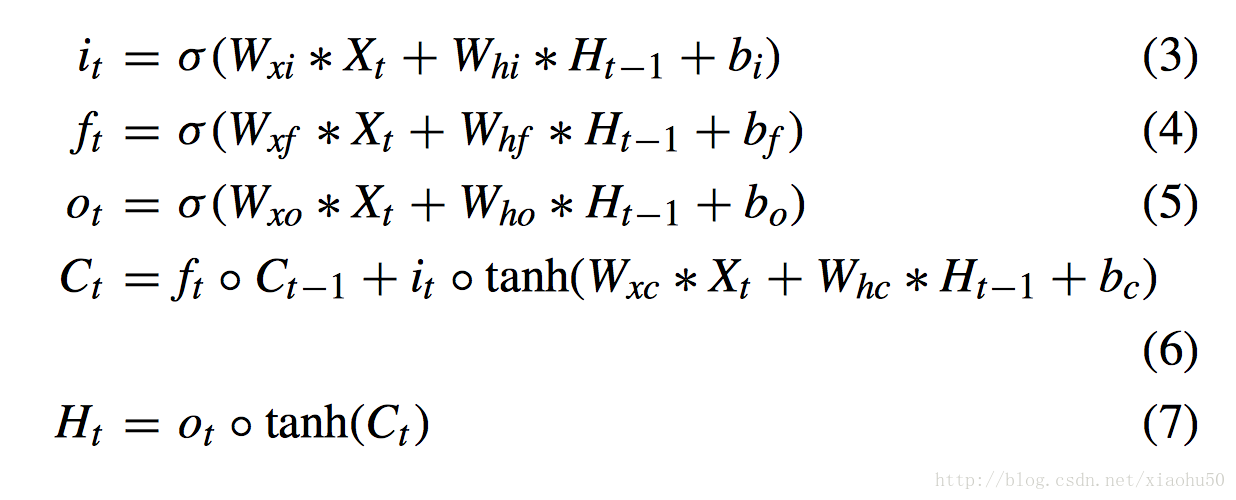
Spatial Pyramid Pooling
參看下面的文章《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
《VideoLSTM Convolves, Attends and Flows for Action Recognition》2016.7
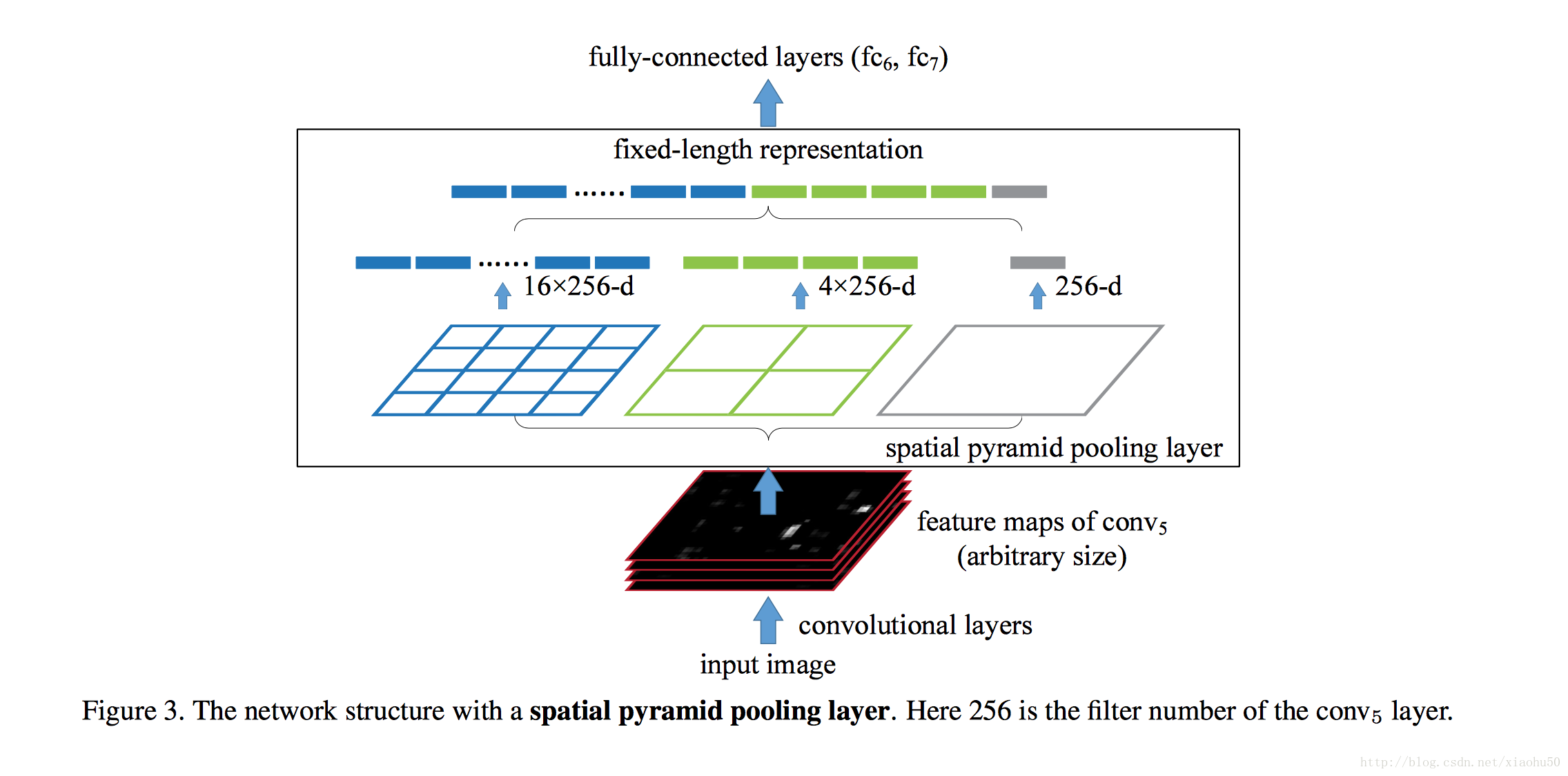
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》2014.6
目標
影象金字塔方法,多尺度。解決兩個問題
- 彌補傳統的分類網路中影象要求固定的缺點
- 提供多尺度的資訊(傳統的cnn通過層數的增加確實能增加perceptive field,但是CNN的視野基本像放大鏡一樣中間的顯著,邊緣模糊,這個時候金字塔方法能夠提供一個全域性資訊)
框架
非常直觀,如下圖
採用多個尺度的pooling(比如Max pooling),與傳統的pooling不同的是,視窗大小不固定,而是依據輸入來變化,比如輸入是一個100x100x5的feature map,現在我們需要對其作左邊藍色的SPP,則直接將100劃分成四段,對每個bin中的25x25作Max pooling, 得到的結果就是16x5的一個vector,這樣每層出來的結果都是定長的。
train方法
如何利用現有框架的方法來訓練是個問題
single-size training
對於傳統的固定大小的輸入,使用金字塔方法也能獲得多尺度資訊來提升準確性,這個時候可以簡單的用傳統的pooling的方法來拼接就可以(根據bin的數目來算出所需要的size和stride),如下圖所示

multi-size training
要像訓練得到一些變尺度的資訊,比如一個數據集原先圖片的尺寸都是224x224,可以通過resize所有資料到180x180,這樣,我們用224x224可以訓練一個網路,用180x180也訓練一個網路,都採用上面single-size training的方法。而兩個網路中的引數數目是相同的,我們share兩個網路中的引數,這樣tain出來的引數更加符合多尺度特徵。
在test的時候,則不論尺寸大小,這個時候poolling的size和stride需要根據資料確定。
《Gesture Recognition with a Convolutional Long Short-Term Memory Recurrent Neural Network》2016
水文,簡單的cnn+lstm。唯一的收穫是可以使用影象差來做輸入,即
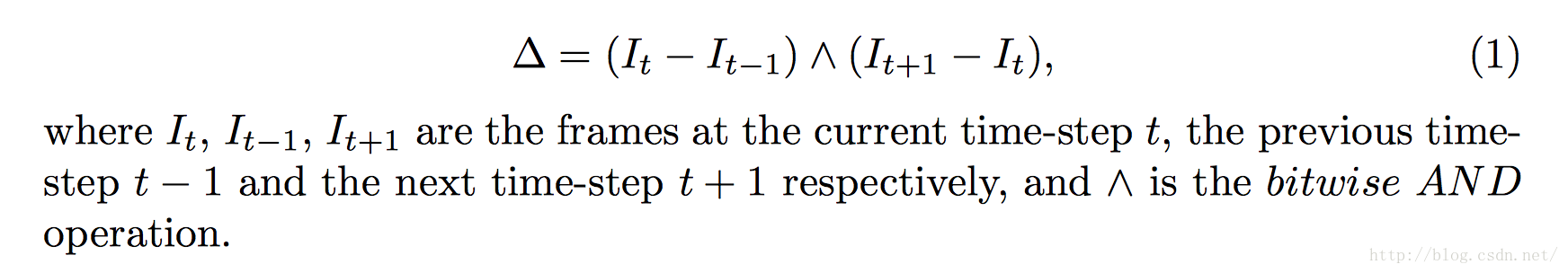
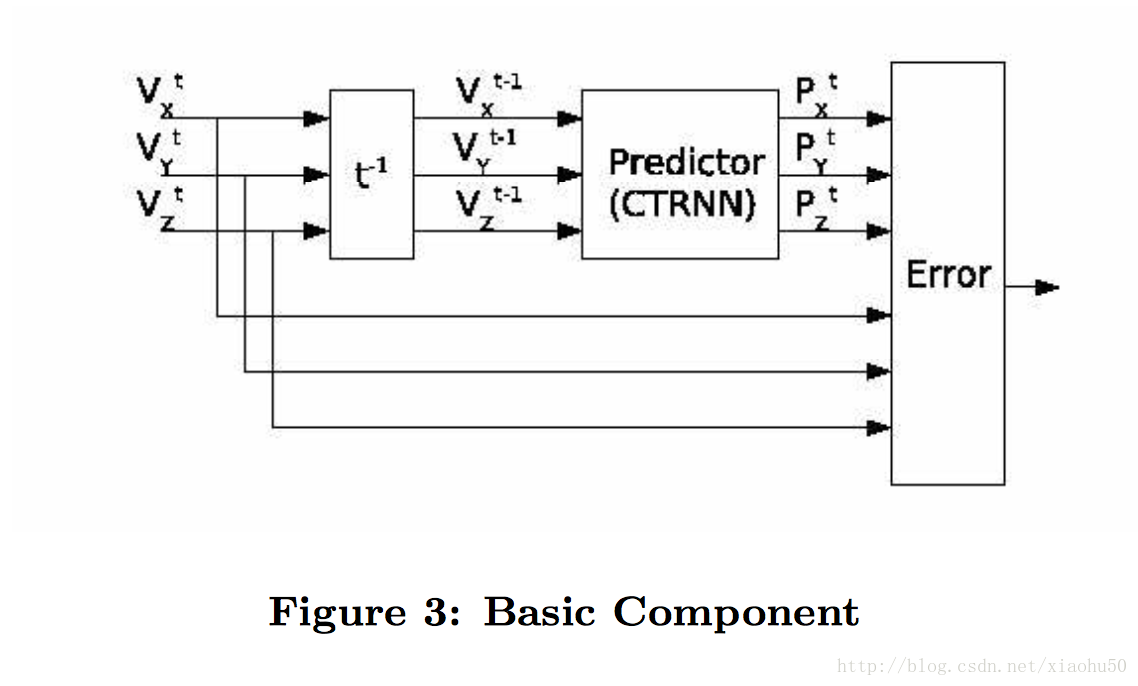
《Real time gesture recognition using Continuous Time Recurrent Neural Networks》
思路很有意思,不直接recognize,而是去predict下一步來recognize
有意思的亮點
首先採用的是三軸加速度計的輸出,這一點本身比較適合predict next。
核心思路就是,對於每個gesture,訓練一個下面的預測器:
即根據t-1時刻的值來預測t時刻的x,y,z三個感測器輸出。
學習好之後,對於recognize過程,輸入是一個序列,可以將輸入放到所有的gesture的predict當中,比較輸出的predict error的大小,最小的即為預測值。