java虛擬機器5.垃圾收集演算法
阿新 • • 發佈:2018-11-06
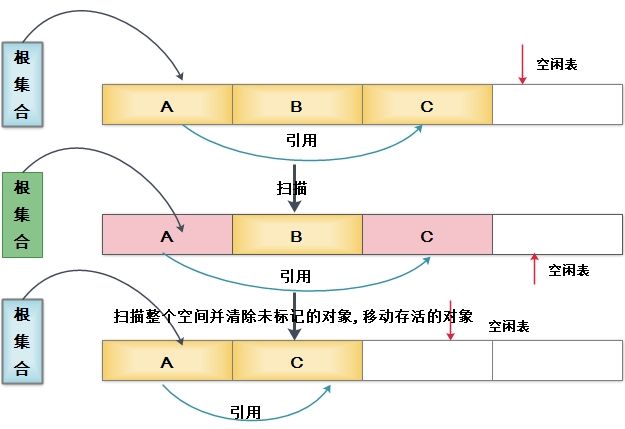
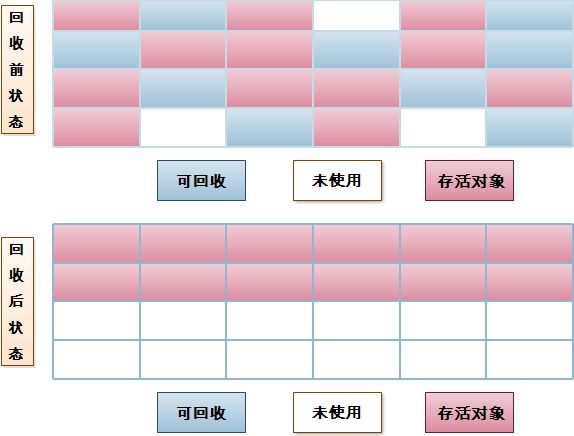
- 1. 標記 - 清除演算法
首先標記出所有需要回收的物件,在標記完成後再統一回收。它的標記過程其實基於上面的可達性分析演算法。之所以說這是最基礎的收集演算法,是因為後續的收集演算法都是基於這種思路並對其不足進行改進而得到的。它的不足有兩個:
- 標記和清除過程效率不高;
- 標記清除之後會產生大量不連續的記憶體碎片,導致後續分配大物件時,無法找到足夠的連續記憶體而不得不提前觸發另一次垃圾收集動作;
- 2. 複製演算法
為了解決效率問題,將可用記憶體容量劃分為大小相等的兩塊,每次只使用其中的一塊。當這一塊用完之後,就將還存活的物件複製到另外一塊上面,然後在把已使用過的記憶體空間一次清理掉
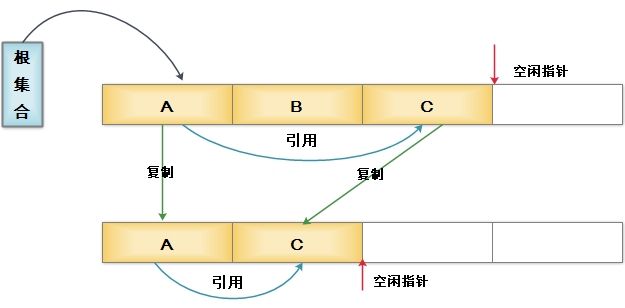
其實在商業虛擬機器中都採用這種收集演算法,統計表明在新生代中98%的物件都是朝生夕死,所以並不需要按照1:1的比例來劃分記憶體空間,而是將記憶體分為一塊較大的Eden空間和兩塊較小的Survivor空間,每次使用Eden和其中一塊Survivor。當回收時,將Eden和Survivor中還存活的物件一次性地複製到另外一塊Survivor空間上,然後清理掉Eden和剛使用過的Survivor。
HotSpot虛擬機器預設Eden和Survivor的大小比例是8:1
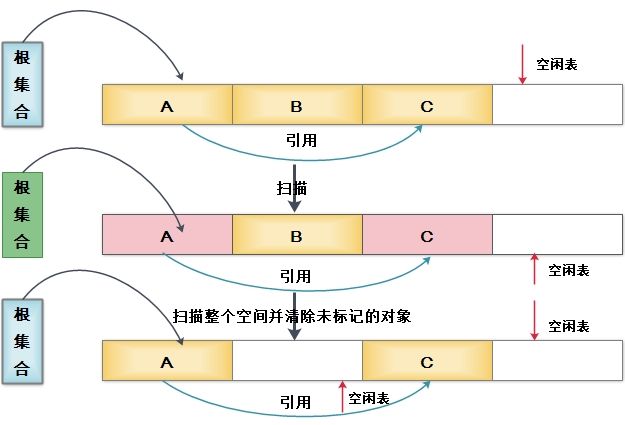
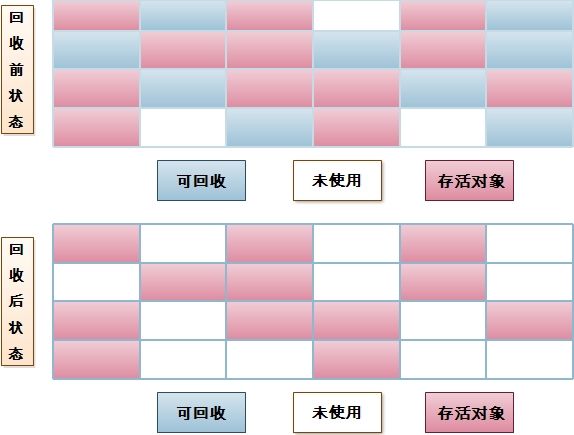
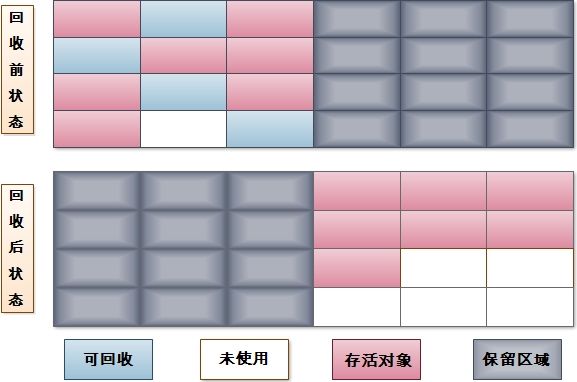
- 3. 標記 - 整理演算法
複製演算法在物件存活率較高時需要進行較多的複製動作,效率將會變低。更關鍵的是,如果不想浪費50%的空間,就需要額外的空間進行分配擔保,以應對被使用的記憶體中所有物件都100%存活的極端情況,所以在在老年代一般不能直接選用複製演算法。所以針對老年代,採用標記-整理演算法,標記操作和“標記-清除”演算法一致,後續操作不只是直接清理物件,而是在清理無用物件完成後讓所有存活的物件都向一端移動,並更新引用其物件的指標