
Java虛擬機器5大核心知識點
1、JVM的基本特性
1.1 基於棧(Stack-based): 不同於Intel x86和ARM等比較流行的計算機處理器都是基於暫存器(register)架構,JVM是基於棧執行的。
1.2 符號引用(Symbolic reference): 編譯後的.class檔案中,除基本型別外的所有Java型別都是通過符號引用取得關聯的,而非顯式的基於記憶體地址的引用。
【符號引用以一組符號來描述所引用的目標,符號可以是任何形式的字面量。例如,在Class檔案中它以CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info等型別的常量出現。
在編譯時,java類還沒有被載入到記憶體中,所以並不知道所引用的類的實際地址,因此只能使用符號引用來代替;在解析階段,Java虛擬機器會把類的二進位制資料中的符號引用替換為直接引用(指向記憶體地址)】
1.3 垃圾回收機制: 類的例項通過使用者程式碼進行顯式建立,但卻通過垃圾回收機制自動銷燬。
1.4 通過明確清晰基本型別確保平臺無關性: 像C/C++等傳統程式語言對於int型別資料在同平臺上會有不同的位元組長度。JVM卻通過明確的定義基本型別的位元組長度來維持程式碼的平臺相容性,從而做到平臺無關。
1.5 網路位元組序(Network byte order): 是TCP/IP中規定好的一種資料表示格式。Java class檔案的二進位制表示使用的是網路位元組序,即基於big endian的位元組序。
【位元組序,即位元組在電腦中存放時的序列與輸入(輸出)時的序列是先到的在前還是後到的在前。 Little endian:將低序位元組儲存在起始地址; Big endian:將高序位元組儲存在起始地址】
2、Java位元組碼在JVM中的執行
2.1 編譯機制
Java位元組碼無法直接直接,需要JVM將其翻譯成機器碼。
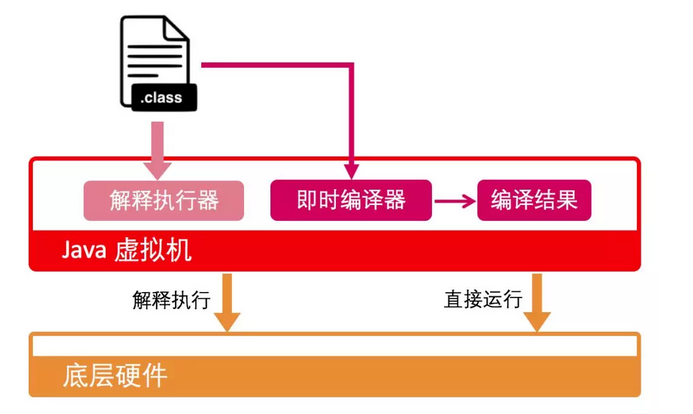
在 HotSpot 裡面,翻譯過程有兩種形式:第一種是解釋執行,相當於同聲傳譯,即每解析一條位元組碼,便翻譯成機器碼並執行;第二種是即時編譯(Just-In-Time compilation,JIT),則相當於線下翻譯,即將整個方法中所包含的位元組碼統一翻譯成機器碼後在執行。前者的優勢在於無需等待編譯,而後者的優勢在於實際執行速度更快。
HotSpot 預設採用混合模式,綜合瞭解釋執行和即時編譯兩者的優點。它會先解釋執行位元組碼,而後將其中反覆執行的熱點程式碼,以方法為單位進行即時編譯。
2.2 載入流程

執行 Java 程式碼首先需要將它編譯而成的 class 檔案載入到 Java 虛擬機器的方法區中。實際執行時,執行引擎會執行方法區內的程式碼。每當呼叫一個 Java 方法,Java 虛擬機器會在當前執行緒的 Java 方法棧中生成一個棧幀,用以存放區域性變數以及位元組碼的運算元。這個棧幀的大小是提前計算好的,而且 Java 虛擬機器不要求棧幀在記憶體空間裡連續分佈。當退出當前執行的方法時,不管是正常返回還是異常返回,JVM均會彈出當前棧幀,並將之捨棄。
3、載入Java類
JVM載入 Java 類的過程可分為三大步驟:載入、連結以及初始化。
3.1 載入
指通過類載入器查詢位元組流,建立類的過程。類載入器使用雙親委派模型,即接收到載入請求時,會先將請求轉發給父類載入器。
3.2 連結
指將建立成的類合併至 JVM中,使之能夠執行的過程。
連結還分驗證(驗證被載入類是否滿足 JVM約束)、準備(為被載入類靜態欄位分配記憶體)和解析(將被載入類中的符號引用解析成為實際引用)三個階段。其中,JVM規範並不要求解析階段一定要在連結步驟中完成。
3.3 初始化
為常量賦值,以及執行 <clinit> 方法的過程。類的初始化僅會被執行一次,這個特性被用來實現單例的延遲初始化。
4、垃圾回收
垃圾回收器採用可達性分析來探索所有存活的物件。它從一系列根物件出發,標記所有被引用的物件。為了防止在標記過程中堆疊的狀態發生改變,JVM採取STW(Stop-The-World) 操作,暫停其他非垃圾回收執行緒。
通常來說,JVM採用分代回收的思想,將堆劃分為新生代和老年代,並且在不同代中應用不同的垃圾回收演算法。新生代再劃分為 Eden 區和兩個大小一致的 Survivor 區。在Minor GC 中,Eden 區和非空 Survivor 區的存活物件會被複制到空的 Survivor 區中,當 Survivor 區中的存活物件複製次數超過一定數值時,它將被晉升至老年代。因為 Minor GC 只針對新生代進行垃圾回收,所以需要考慮從老年代到新生代的引用。為了避免掃描整個老年代,Java 虛擬機器引入了名為卡表的技術,標出老年代對新生代引用的記憶體區域。
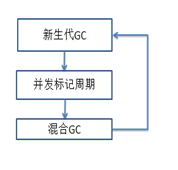
G1 垃圾回收器包含三個階段(新生代GC、併發標記週期、混合GC);G1將堆劃分為多個等大的區域,優先收集垃圾最多的區域,從而最大化垃圾回收的效益。
Java 11 中引入的實驗性垃圾回收器 ZGC,僅在掃描可達物件時請求 Stop-The-World,暫停應用執行緒。因此,它宣稱可將 GC 暫停時間控制在 10ms 以下。ZGC 暫時沒有應用分代回收的思路,將整個堆空間看成一塊,其代價是垃圾回收 CPU 消耗較高。
5、Java記憶體模式
在現代計算機系統中,程式碼通常不會按照書寫順序執行。造成這一情況的原因有三個,分別為編譯器的重排序,處理器的亂序執行,以及記憶體系統的重排序。
以記憶體系統重排序為例,在多處理器體系架構下,每個處理器都可能快取了一部分資料。由於時刻保持快取資料與記憶體資料同步的效能代價太大,因此部分體系架構可能允許快取資料與記憶體資料不同步。這對 Java 程式的影響便是,兩個不同的 Java 執行緒在同一時間內看到的同一塊記憶體地址中的值可能不同。
Java 記憶體模型是針對上述問題而提出的一套規範,用以允許 Java 程式設計師更為細緻地定義 Java 程式的記憶體行為。它通過定義了一系列的 happens-before 操作,讓應用程式開發者能夠輕易地表達不同執行緒的操作之間的記憶體可見性。
在遵守 Java 記憶體模型的前提下,即時編譯器以及底層體系架構能夠調整記憶體訪問操作,以達到效能優化的效果。如果開發者沒有正確地利用 happens-before 規則,那麼將可能導致資料競爭。
Java 記憶體模型是通過記憶體屏障來禁止重排序的。對於即時編譯器來說,記憶體屏障將限制它所能做的重排序優化。對於處理器來說,記憶體屏障會導致快取的重新整理操作。
我有一個微信公眾號,經常會分享一些Java技術相關的乾貨;如果你喜歡我的分享,可以用微信搜尋“Java團長”或者“javatuanzhang”關注。