
pandas 資料聚合與分組運算
1. GroupBy技術
pandas物件(無論是Series、DataFrame還是其他的)中的資料會根據你所提供的一個或多個鍵被拆分(split)為多組。
拆分操作是在物件的特定軸上執行的。
例如:DataFrame可以在其行(axis=0)或列(axis=1)上進行分組,然後將一個函式應用(apply)到各個分組併產生一個新值。
最後,所有這些函式的執行結果會被合併(combine)到最終的結果物件中。
下圖大致說明了分組聚合的演示:
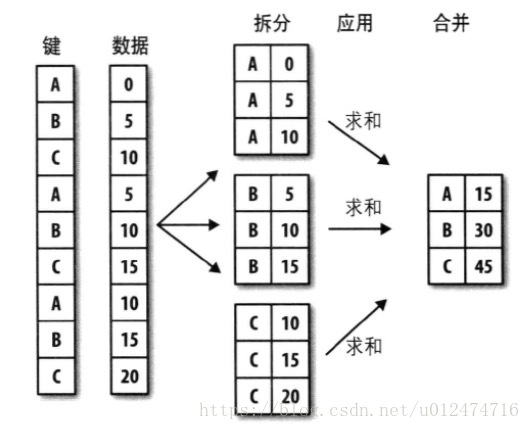
分組鍵可以有多種形式,且型別不必相同:
(1)列表或陣列,其長度與待分組的軸一樣。
(2)表示DataFrame某個列名的值
(3)字典或Series,給出待分組軸上的值與分組名之間的對應關係
(4)函式,用於處理軸索引或索引中的各個標籤
注意,後三種都只是快捷方式而己,其最終目的仍然是產生一組用於拆分物件的值。
import numpy as np from pandas import DataFrame,Series #(1)執行numpy的groupby方法分組 df=DataFrame({'key1':['a','a','b','b','a'], 'key2':['one','two','one','two','one'], 'data1':np.random.randn(5), 'data2':np.random.randn(5)}) print df #輸出結果如下: # data1 data2 key1 key2 # 0 1.605758 1.477281 a one # 1 0.726355 0.724383 a two # 2 2.007510 1.778955 b one # 3 0.543327 -0.057515 b two # 4 -0.351209 -0.518018 a one #假設想要按kye1進行分組,並計算data1列的平均值。訪問data1,並根據key1呼叫groupby: grouped=df['data1'].groupby(df['key1']) #data1資料按key1進行分組 print grouped #輸出結果如下:<pandas.core.groupby.SeriesGroupBy object at 0x1048d8490> #grouped是一個GroupBy物件,它實際上還沒有進行任何計算,只是含有一些有關分組鍵df['key1'] #的中間資料而己。換句話說,該物件已經有了接下來對各分組執行運算所需的一切資訊。 #我們可以呼叫GroupBy的mean方法來計算分組平均值 print grouped.mean() #輸出結果如下: # key1 # a -0.434085 # b -0.375503 # Name: data1, dtype: float64 #注意:資料(Series)根據分組鍵進行了聚合,產生了一個新的Series,其索引為key1列中的唯一值。 #之所以結果中索引的名稱為key1,是因為原始DataFrame的列df['key1']就叫這個名字 #若我們一次傳入多個數組,就會得到不同的結果 means=df['data1'].groupby([df['key1'],df['key2']]).mean() print means #輸出結果如下: # key1 key2 # a one -0.365097 # two -0.381603 # b one -1.403614 # two -2.742555 # Name: data1, dtype: float64 #注意:通過兩個鍵對資料進行了分組,得到的Series具有一個層次化索引(由唯一的鍵對組成) print means.unstack() #unstack和stack行列的轉化 #輸出結果如下: # key2 one two # key1 # a -0.350190 0.480907 # b -0.857794 0.949170 #在上面這些示例中,分組鍵均為Series.實際上,分組鍵可以是任何長度適當的陣列: states=np.array(['Ohio','California','California','Ohio','Ohio']) years=np.array([2005,2005,2006,2005,2006]) print df['data1'].groupby([states,years]).mean() #輸出結果如下: # California 2005 0.449663 # 2006 0.425458 # Ohio 2005 0.537592 # 2006 -0.279219 # Name: data1, dtype: float64 #還可以將列名(可以是字串、數字或其他Python物件)用作分組鍵: print df.groupby('key1').mean() #輸出結果如下: # data1 data2 # key1 # a 0.046327 0.561451 # b -0.085989 0.215877 print df.groupby(['key1','key2']).mean() #輸出結果如下: # key1 key2 # a one -0.540068 -1.080045 # two -0.905713 -0.996828 # b one 2.111136 0.546535 # two 0.648188 -0.498834 #GroupBy的size方法,它可以返回一個含有分組大小的Series: print df.groupby(['key1','key2']).size() #輸出結果如下: # key1 key2 # a one 2 表示a one的有2個數 # two 1 # b one 1 # two 1
對分組進行迭代:
import numpy as np from pandas import DataFrame,Series (1)執行numpy的groupby方法分組 df=DataFrame({'key1':['a','a','b','b','a'], 'key2':['one','two','one','two','one'], 'data1':np.random.randn(5), 'data2':np.random.randn(5)}) print df #輸出結果如下: # data1 data2 key1 key2 # 0 1.605758 1.477281 a one # 1 0.726355 0.724383 a two # 2 2.007510 1.778955 b one # 3 0.543327 -0.057515 b two # 4 -0.351209 -0.518018 a one (2)GroupBy物件支援迭代,可以產生一組二元元組(由分組名和資料塊組成) for name,group in df.groupby('key1'): print name print group #輸出結果如下: #name: # a # data1 data2 key1 key2 # 0 1.891706 -0.492166 a one # 1 1.809804 -0.292517 a two # 4 -1.116779 1.870921 a one #group: # b # data1 data2 key1 key2 # 2 0.737782 -0.521142 b one # 3 -0.854384 1.356374 b two (3)對於多重鍵情況,元組的第一個元素將會是由鍵值組成的元組: for (k1,k2),group in df.groupby(['key1','key2']): print k1,k2 print group #輸出結果如下: #k1,k2 # a one # data1 data2 key1 key2 # 0 -0.767050 -2.596870 a one # 4 0.641077 0.480521 a one # a two # data1 data2 key1 key2 # 1 2.083827 -0.680062 a two #group # b one # data1 data2 key1 key2 # 2 -0.070502 -0.213549 b one # b two # data1 data2 key1 key2 # 3 -0.614806 -0.016378 b two (4)當然,你可以對這些資料片段做任何操作。有一個有用的運算:將這些資料片段做成一個字典:dict(list(df.groupby(''))) pieces=dict(list(df.groupby('key1'))) print pieces #輸出結果如下: # {'a': data1 data2 key1 key2 # 0 -2.860537 -0.139119 a one # 1 1.832103 -0.073315 a two # 4 -0.524176 0.052688 a one, # 'b': data1 data2 key1 key2 # 2 -0.213096 1.076033 b one # 3 0.654225 -0.786246 b two} # print pieces['b'] #輸出結果如下: # data1 data2 key1 key2 # 2 -0.213096 1.076033 b one # 3 0.654225 -0.786246 b two (5)groupby預設是在axis=0(行)上進行分組,通過設定也可以在其他任何軸上進行分組:axis=1(列) #拿上面的例子中的df來說,我們可以根據dtype對列進行分組: print df.dtypes #輸出結果如下: # data1 float64 # data2 float64 # key1 object # key2 object # dtype: object grouped=df.groupby(df.dtypes,axis=1) print dict(list(grouped)) #將其轉化為字典 #輸出結果如下: # {dtype('O'): key1 key2 # 0 a one # 1 a two # 2 b one # 3 b two # 4 a one, # dtype('float64'): data1 data2 # 0 -1.586465 -0.380714 # 1 -1.786134 -0.663670 # 2 0.320359 0.624725 # 3 -0.620432 0.924842 # 4 -0.663463 1.023058}
選取一個或一組列:
對於由DataFrame產生的GroupBy物件,如果一個(單個字串)或一組(字串陣列)列名對其進行索引,
就能實選取部分列進行整合的目的。也就是說:
print df.groupby('key1')['data1']
是下面程式碼的語法糖:
print df['data1'].groupby(df['key1'])尤其對於大資料集,很可能只需要對部分列進行聚合。
import numpy as np
from pandas import DataFrame,Series
# (1)執行numpy的groupby方法分組
df=DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
# print df
#輸出結果如下:
# data1 data2 key1 key2
# 0 1.605758 1.477281 a one
# 1 0.726355 0.724383 a two
# 2 2.007510 1.778955 b one
# 3 0.543327 -0.057515 b two
# 4 -0.351209 -0.518018 a one
#例如,在前面那個資料集中,如果只需計算data2列的平均值並以DataFrame形式得到結果,我們可以編寫:
print df.groupby(['key1','key2'])[['data2']].mean()
#輸出結果如下:
# data2
# key1 key2
# a one -1.329059
# two -0.486441
# b one 0.400199
# two -1.215200
#這種索引操作所返回的物件是一個已分組的DataFrame
s_grouped=df.groupby(['key1','key2'])['data2']
print s_grouped
#輸出結果如下:<pandas.core.groupby.SeriesGroupBy object at 0x103fa0590> 它是一個groupby物件
print s_grouped.mean()通過字典或Series進行分組:
import numpy as np
from pandas import DataFrame,Series
#(1)除陣列以外,分組資訊還可以其他形式存在。
# people=DataFrame(np.random.randn(5,5),
# columns=['a','b','c','d','e'],
# index=['Joe','Steve','Wes','Jim','Travis'])
# # print people
people=DataFrame([[1,0,1,2,1],
[0,2,3,1,0],
[1,2,3,0,1],
[-1,0,-1,2,0],
[2,3,1,-2,0]],
columns=['a','b','c','d','e'],
index=['Joe','Steve','Wes','Jim','Travis'])
people.ix[2:3,['b','c']]=np.nan #ix[2:3]行索引為[2:3],索引切片不包括3,'b','c'列的值為Nan
print people
#輸出結果如下:
# a b c d e
# Joe 1 0.0 1.0 2 1
# Steve 0 2.0 3.0 1 0
# Wes 1 NaN NaN 0 1
# Jim -1 0.0 -1.0 2 0
# Travis 2 3.0 1.0 -2 0
#(2)假設己知列的分組關係,並希望根據分組計算列的總計:
mapping={'a':'red','b':'red','c':'blue',
'd':'blue','e':'red','f':'orange'}
#現在只需將這個字典傳給groupby即可:
by_column=people.groupby(mapping,axis=1)
print by_column.sum()
#輸出結果如下:'c','d'相加存入blue中,其它的相加放入red中
# blue red
# Joe 3.0 2.0
# Steve 4.0 2.0
# Wes 0.0 2.0
# Jim 1.0 -1.0
# Travis -1.0 5.0
#(3) Series也有同樣的功能,它可以被看做一個固定大小的對映。
#對於上面的那個例子,如果用Series作為分組鍵,則pandas會檢查Series以確保其索引跟分組軸是對齊的:
map_series=Series(mapping)
print map_series
#輸出結果如下:
# a red
# b red
# c blue
# d blue
# e red
# f orange
print people.groupby(map_series,axis=1).count()
#輸出結果如下:
# blue red
# Joe 2 3
# Steve 2 3
# Wes 1 2
# Jim 2 3
# Travis 2 3通過函式進行分組:
import numpy as np
from pandas import DataFrame,Series
#前面一小節的示例DataFrame為例,其索引值為人的名字。假設你希望根據人名的長度進行分組,
#雖然可以求取一個字串長度陣列,但其實僅僅傳入len函式就可以了:
people=DataFrame([[1,0,1,2,1],
[0,2,3,1,0],
[1,2,3,0,1],
[-1,0,-1,2,0],
[2,3,1,-2,0]],
columns=['a','b','c','d','e'],
index=['Joe','Steve','Wes','Jim','Travis'])
print people
#輸出結果如下:
# a b c d e
# Joe 1 0 1 2 1
# Steve 0 2 3 1 0
# Wes 1 2 3 0 1
# Jim -1 0 -1 2 0
# Travis 2 3 1 -2 0
print people.groupby(len).sum()
#輸出結果如下:
# a b c d e
# 3 1 2 3 4 2 #3是Joe,wes,Jim 在a,b,c,d,e列相加
# 5 0 2 3 1 0 #5只有steve一個人,故steve的資料抄下來即可
# 6 2 3 1 -2 0
#將函式跟陣列、列表、字典、Series混合使用,因為任何東西最終都會被轉換為陣列:
key_list=['one','one','one','two','two']
print people.groupby([len,key_list]).min()
#輸出結果如下:
# a b c d e
# 3 one 1 0 1 0 1
# two -1 0 -1 2 0
# 5 one 0 2 3 1 0
# 6 two 2 3 1 -2 0根據索引級別分組:
層次化索引資料集就在於它能夠根據索引級別進行聚合。要實現該目的,通過Level關鍵字傳入級別編號或名稱即可:
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
columns=pd.MultiIndex.from_arrays([['US','US','US','JP','JP'],
[1,3,5,1,3]],names=['cty','tenor'])
hier_df=DataFrame(np.random.randn(4,5),columns=columns)
print hier_df
#輸出結果如下:
# cty US JP
# tenor 1 3 5 1 3
# 0 1.189705 2.334732 0.602338 0.650734 1.933684
# 1 -0.011591 1.247894 -1.701154 -0.052255 0.835968
# 2 -0.936263 -0.313018 1.577031 0.108007 0.116402
# 3 -0.032721 0.688506 0.001428 -0.550061 0.525248
print hier_df.groupby(level='cty',axis=1).count() #axis=1列分組,count是取總計的個數
#輸出結果如下:
# cty JP US
# 0 2 3 #US的0的有3個
# 1 2 3
# 2 2 3
# 3 2 32.資料聚合
對於聚合,指的是任何能夠從陣列產生標量值的資料轉換過程。例如:mean,count,min以及sum等。
許多常見的聚合運算都有就地計算資料集統計資訊的優化實現,然而,並不是只能使用這些方法。
可以自己定義聚合運算,還可以呼叫分組物件上已經定義好的任何方法。例如,quantile可以計算
Series或DataFrame列的樣本分位數。
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
df=DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
# print df
#輸出結果如下:
# data1 data2 key1 key2
# 0 -0.065696 0.404059 a one
# 1 -1.202053 -0.303539 a two
# 2 1.963036 0.989266 b one
# 3 0.461733 -0.061501 b two
# 4 1.198864 2.111709 a one
grouped=df.groupby('key1')
print grouped #返回groupby物件
print grouped['data1'].quantile(0.9) #算出按key1分組後的data1的分位數(0.9)的值
#輸出結果如下:
# key1
# a 0.143167
# b 1.407836
#注意:雖然quantile並沒有明確地實現於GroupBy,但它是一個Series方法,所以這裡是能用的。
#實際上,GroupBy會高效地對Series進行切片,然後對各片呼叫piece.quantile(0.9),最後將
#這些結果組裝成最終結果。(1)作用自定義的聚合函式:只需將其傳入aggregate或agg方法即可
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
df=DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
# print df
#輸出結果如下:
# data1 data2 key1 key2
# 0 -0.065696 0.404059 a one
# 1 -1.202053 -0.303539 a two
# 2 1.963036 0.989266 b one
# 3 0.461733 -0.061501 b two
# 4 1.198864 2.111709 a one
grouped=df.groupby('key1')
print grouped #返回groupby物件
def peak_to_peak(arr):
return arr.max()-arr.min()
print grouped.agg(peak_to_peak)
#輸出結果如下:
# data1 data2
# key1
# a 1.672300 1.298854
# b 0.315454 2.404649
#注意:自定義函式要比那些經過優化的函式慢得多,這是因為在構造中間分組資料塊時存在非常大的開銷(函式呼叫/資料重排等)
#有些方法(如describe)也是可以用在這裡的。即使嚴格來講,它並非聚合運算:
print grouped.describe()
經過優化的groupby的方法:
函式名 說明
count 分組中非NA值的數量
sum 非NA值的和
mean 非NA值的平均值
median 非NA值的算術中位數
std、var 無偏(分母為n-1)標準差和方差
min、max 非NA值的最小值、最大值
prod 非NA值的積
first、last 第一個和最後一個非NA值
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
#以餐館小費的資料集為例
#(1)通過read_csv載入之後,添加了一個表示小費比例的列tip_pct
tips=pd.read_csv('ch08/tips.csv')
tips['tip_pct']=tips['tip']/tips['total_bill']
print tips[:6]面向列的多函式應用:
我們已經看到,對Series或DataFrame列的聚合運算其實就是使用aggregate(自定義函式)或呼叫mean,std之類的方法。
你可能希望對不同的列使用不同的聚合函式,或一次應用多個函式。
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
#根據sex和smoker對tips進行分組:
grouped=tips.groupby(['sex','smoker'])
#可以將函式名以字串的形式傳入:
grouped_pct=grouped['tip_pct']
print grouped_pct.agg('mean')
#如果傳入一組函式或函式名,得到的DataFrame的列就會以相應的函式命名
print grouped_pct.agg(['mean','std',peak_to_peak]) #mean,std是優化後的聚合函式,peak_to_peak是前面自定義的函式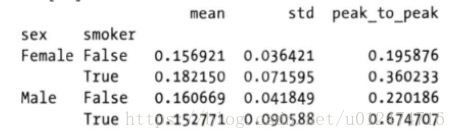
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
#(1)如果傳入的是一個由(name,function)元組組成的列表,則各元組的第一個元素就會被用作DataFrame的列名
print grouped_pct.agg([('foo','mean'),('bar',np.std)])
#輸出結果如下:
# foo bar
# sex smoker
# Female False 0.15 0.03
# True 0.18 0.07
# Male False 0.16 0.04
# True 0.15 0.09
#(2)對於DataFrame,還可以定義一組應用於全部列的函式,或不同的列應用不同的函式。
#我們想要對tip_pct和total_bill列計算三個統計資訊
functions=['count','mean','max']
result=grouped['tip_pct','total_bill'].agg(functions)
print result
#輸出結果如下:
# tip_pct total_bill
# count mean max count mean max
# sex smoker
# Female False 54 0.15 0.25 54 18.1 35.8
# True 33 0.18 0.41 33 17.9 44.3
# Male False 97 0.16 0.29 97 19.7 48.3
# True 60 0.15 0.71 60 22.2 50.8
#如上所見,結果DataFrame擁有層次化的列,這相當於分別對各列進行聚合,然後用concat將結果組裝到一起(列名用作keys引數)。
print result['tip_pct'] #取出tip_pct的資料
#(3)跟前面一樣,這裡也可以傳入帶有自定義名稱的元組列表:
ftuples=[('Durchschnitt','mean'),('Abweichung',np.var)] #Durchschnitt自定義名,mean該列要用到的方法
print grouped['tip_pct','total_bill'].agg(ftuples)
#輸出結果如下:
# tip_pct total_bill
# # Durchschnitt Abweichung Durchschnitt Abweichung
# # sex smoker
# # Female False 0.15 0.03 18.1 53.0
# # True 0.18 0.07 17.9 84.4
# # Male False 0.16 0.04 19.7 76.1
# # True 0.15 0.09 22 98
#(4)假設你想要對不同的列應用不同的函式。具體的辦法是向agg傳入一個從列名對映到函式的字典:
grouped.agg({'tip':np.max,'size':'sum'}) #tip是列名,np.max是方法
#輸出結果如下:
# size tip
# sex smoker
# Female False 140 5.2
# True 74 0.07
# Male False 263 0.04
# True 150 0.09
grouped.agg({'tip_pct':['min','max','mean','std'],
'size':'sum'}) #tip_pct有min,max,mean,std方法,size有sum方法
#輸出結果如下:
# tip_pct size
# min mean max std sum
# sex smoker
# Female False 0.05 0.15 0.25 0.03 140
# True 0.06 0.18 0.41 0.07 74
# Male False 0.07 0.16 0.29 0.04 263
# True 0.03 0.15 0.71 0.08 150
#只有將多個函式應用到至少一列時,DataFrame才會擁有層次化的列以“無索引”的形式返回聚合資料:
到目前為止,所有示例中的聚合資料都有由唯一的分組鍵組成的索引(可能還是層次化的)。由於並不總是需要如此,
所以你可以向groupby傳入as_index=False以禁用該功能:
print tips.groupby(['sex','smoker'],as_index=False).mean()
#輸出結果如下:
#
# sex smoker total_bill tip size tip_pct
# Female False 18.1 2.77 2.58 0.15
# True 17.1 2.93 2.41 0.18
# Male False 19.07 3.16 2.29 0.16
# True 22.03 3.15 2.51 0.15
#當然,對結果呼叫reset_index也能得到這種形式的結果。3.分組級運算和轉換
聚合只不過是分組運算的其中一種而己。它是資料轉換的一個特例。下面將介紹transform和apply方法,它們能
夠執行更多其他的分組運算。
(1)transform:會將一個函式應用到各個分組,然後將結果放置到各個分組的適當的位置上。
假設我們想要為一個DataFrame新增一個用於存放各索引分組平均值的例。一個辦法是先聚合再合併:df=DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
print df
#輸出結果如下:
# data1 data2 key1 key2
# 0 0.999322 0.005281 a one
# 1 1.057139 -0.322877 a two
# 2 1.130281 -0.272296 b one
# 3 2.328475 -0.497984 b two
# 4 -0.364299 -0.701872 a one
#(1)按key1分組後取mean計算。因為k1可分為a,b兩組,a,b兩組中各有data1,data2
k1_means=df.groupby('key1').mean().add_prefix('mean_') #因為按key1分組,新增mean_
print k1_means
#輸出結果如下:
# mean_data1 mean_data2
# key1
# a 1.685305 0.720963
# b -0.671712 -0.444973
#(2)聚合
print pd.merge(df,k1_means,left_on='key1',right_index=True) #df,k1_means左連線
#輸出結果如下:
# data1 data2 key1 key2 mean_data1 mean_data2
# 0 1.300802 1.159461 a one 0.851929 0.649493
# 1 1.542113 0.605346 a two 0.851929 0.649493
# 4 -0.287129 0.183673 a one 0.851929 0.649493
# 2 -0.923089 -0.248955 b one -0.507969 -0.464783
# 3 -0.092848 -0.680611 b two -0.507969 -0.464783
#注意:雖然這樣也行,但是不太靈活,你可以將該過程看做利用np.mean函式對兩個資料列進行轉換。
#(3)這次我們在GroupBy上使用transform方法。
# 不難看出,transform會將一個函式應用到各個分組,然後將結果放置到適當的位置上。
# 如果各分組產生的是一個標量值,則該值就會被廣播出去。
key=['one','two','one','two','one']
print df.groupby(key).mean()
#輸出結果如下:
# data1 data2
# one -0.860574 -0.130721
# two -0.563933 0.581333
print df.groupby(key).transform(np.mean)
#輸出結果如下:
# data1 data2
# 0 0.174402 -0.123673
# 1 0.704685 0.599223
# 2 0.174402 -0.123673
# 3 0.704685 0.599223
# 4 0.174402 -0.123673
def demean(arr):
return arr-arr.mean()
demeaned=df.groupby(key).transform(demean)
print demeaned
#輸出結果如下:
# data1 data2
# 0 -0.600930 -0.755259
# 1 -0.960131 0.548909
# 2 0.067299 0.460494
# 3 0.960131 -0.548909
# 4 0.533631 0.294765
#檢查一下demeaned現在的分組平均值是否是0:
print demeaned.groupby(key).mean()
#輸出結果如下:
# data1 data2
# one -3.700743e-17 -1.850372e-17
# two 0.000000e+00 -1.387779e-17(2)apply:一般性的“拆分-應用-合併”
跟aggregate一樣,transform也是一個有著嚴格條件的特殊函式:傳入的函式只能產生兩種結果,要麼產生
一個可以廣播的標量值(np.mean),要麼產生一個相同大小的結果陣列。apply會將待處理的物件拆分成多個片段,
然後對各片段呼叫傳入的函式,最後將各片段組合到一起。
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
#原先那個小費資料集,假設你想要根據分組選出最高的5個tip_pct值。
#(1)編寫一個選取指定列具有最大值的行的函式
def top(df,n=5,column='tip_pct'):
#在批定列找出最大值,然後把這個值所在的行選取出來
return df.sort_index(by=column)[-n:] #按列排序,取[-n:]倒數第n個取出後面n個數
print top(tips,n=6)
#輸出結果如下:
# total_bill tip sex smoker day time size tip_pct
# 109 14 4 Female True Sat Dinner 2 0.27
# 183 23 6.5 Male True Sun Dinner 4 0.28
# 232 11 3.3 Male False Sat Dinner 2 0.29
# 67 3 1 Female True Sat Dinner 1 0.32
# 178 9.6 4 Female True Sun Dinner 2 0.41
# 172 7.25 5.15 Male True Sun Dinner 2 0.71
(2)現在,如果對smoker分組並用該函式呼叫apply,就會得到:
tips.groupby('smoker').apply(top)
#返回結果如下:
# total_bill tip sex smoker day time size tip_pct
# smoker
# No 88 24.71 5.85 Male False Thur Lunch 2 0.23
# 185 20.69 5 Male False Sun Dinner 5 0.24
# 185 20.69 5 Male False Sun Dinner 5 0.24
# 185 20.69 5 Male False Sun Dinner 5 0.24
# Yes 109 14.3 4 FeMale True Sat Dinner 4 0.28
# 109 14.3 4 FeMale True Sat Dinner 4 0.28
# 109 14.3 4 FeMale True Sat Dinner 4 0.28
# 109 14.3 4 FeMale True Sat Dinner 4 0.28
#(3)top函式在DataFrame的各個片段上呼叫,然後結果由pandas.concat組裝到一起,並以分組名稱進行了標記。
#於是,最終結果就有了一個層次化索引,其內層索引值來自DataFrame.
print tips.groupby(['smoker','day']).apply(top,n=1,column='total_bill')
#輸出結果如下:
# total_bill tip sex smoker day time size tip_pct
# smoker day
# No Fri 24.71 5.85 Male False Thur Lunch 2 0.23
# Sat 20.69 5 Male False Sun Dinner 5 0.24
# Yes Fri 14.3 4 FeMale True Sat Dinner 4 0.28
# Sat 14.3 4 FeMale True Sat Dinner 4 0.28
# Sun 14.3 4 FeMale True Sat Dinner 4 0.28
result=tips.groupby('smoker')['tip_pct'].describe()
print result
#輸出結果如下:
# smoker
# No count 151
# mean 0.159
# std
# min
# 25%
# 50%
# 75%
# max
# Yes count
# mean
# std
# min
# 25%
# 50%
# 75%
# max
print result.unstack('smoker') #行,列互換
#輸出結果如下:
# smoker No Yes
# count 151 93
# mean 0.15 0.16
# std 0.03 0.08
# min 0.05 0.03
# 25% 0.13 0.10
# 50% 0.15 0.15
# 75% 0.18 0.18
# max 0.28 0.71
#(4)GroupBy中,當你呼叫諸如describe之類的方法時,實際上只應用了下面兩條程式碼的快捷方式而己:
f=lambda x:x.describe()
print grouped.apply(f)禁止分組鍵:group_keys=False
分組鍵會跟原始物件的索引共同構成結果物件中的層次化索引。將group_keys=False傳入groupby即可禁止該效果:#分組鍵會跟原始物件的索引共同構成結果物件中的層次化索引。將group_keys=False傳入groupby即可禁止該效果:
def top(df,n=5,column='tip_pct'):
return df.sort_index(by=column)[-n:]
print tip.groupby('smoker',group_keys=False).apply(top)
#輸出結果如下:
# total_bill tip sex smoker day time size tip_pct
# 109 14 4 Female True Sat Dinner 2 0.27
# 183 23 6.5 Male True Sun Dinner 4 0.28
# 232 11 3.3 Male False Sat Dinner 2 0.29
# 67 3 1 Female True Sat Dinner 1 0.32
# 178 9.6 4 Female True Sun Dinner 2 0.41
# 172 7.25 5.15 Male True Sun Dinner 2 0.71分位數和桶分析:
pandas有一些能根據指定面元或樣本分位數將資料拆分成多塊的工具(比如cut和qcut).將這些函式跟groupby結合起來,
就能非常輕鬆地實現對資料集的桶(bucket)或分位數(quantile)分析了。
下面的例子是以隨機資料集為例,我們利用cut將其裝入長度相等的桶中:每個等矩離區間就是一個桶
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
#(1)cut:bins為1表示整數--將X劃分為多個個等間矩的區間
frame=DataFrame({'data1':np.random.randn(1000),
'data2':np.random.randn(1000)})
factor=pd.cut(frame.data1,4) #將frame.data1劃分為等間矩的區間,4是precision=4精確度
print factor[:10]
#輸出結果如下:
# 0 (1.465, 3.234]
# 1 (-2.074, -0.304]
# 2 (-0.304, 1.465]
# 3 (-2.074, -0.304]
# 4 (-2.074, -0.304]
# 5 (-2.074, -0.304]
# 6 (-2.074, -0.304]
# 7 (-0.304, 1.465]
# 8 (-0.304, 1.465]
# 9 (-2.074, -0.304]
# Name: data1, dtype: category
# Categories (4, interval[float64]): [(-3.85, -2.074] < (-2.074, -0.304] < (-0.304, 1.465] <
# (1.465, 3.234]]
#(2)由於cut返回的Factor物件可直接用於groupby.
#因此,我們可以像下面這樣對data2做一些統計計算:
def get_stats(group):
return {'min':group.min(),'max':group.max(),
'count':group.count(),'mean':group.mean()}
#data2按factor(等矩離區間)分組,factor的等矩離區間:但是每次執行一次就是隨機資料,所以每次執行會不一樣。
# [(-3.85, -2.074] < (-2.074, -0.304] < (-0.304, 1.465] <(1.465, 3.234]]
grouped=frame.data2.groupby(factor)
#分組後用apply呼叫方法,unstack再將行列轉換
print grouped.apply(get_stats).unstack()
#輸出結果如下:
# count max mean min
# data1
# (-3.85, -2.074] 24.0 1.771732 -0.037332 -1.769997
# (-2.074, -0.304] 356.0 3.781041 0.060009 -3.552757
# (-0.304, 1.465] 549.0 3.146836 -0.057476 -3.123641
# (1.465, 3.234] 71.0 2.765544 -0.056112 -1.968819
#(3)上面的都是長度相等的桶。要根據樣本分位數得到大小相等的桶,使用qcut.傳入labels=False即可只獲取分位數的編號。
#返回分位數編號
grouping=pd.qcut(frame.data1,10,labels=False) #qcut與cut區別是qcuat是根據這些值的頻率來選擇的,而cut是根據值來選擇的
# print grouping
grouped=frame.data2.groupby(grouping)
print grouped.apply(get_stats).unstack()
#輸出結果如下:
# count max mean min
# data1
# 0 100.0 2.835962 0.031973 -1.992897
# 1 100.0 3.049567 0.071329 -2.239653
# 2 100.0 3.032595 0.123676 -2.090986
# 3 100.0 1.662204 -0.103337 -3.066419
# 4 100.0 2.660674 0.032828 -2.237807
# 5 100.0 2.834181 0.201375 -1.970967
# 6 100.0 2.444546 -0.129342 -2.436978
# 7 100.0 2.260455 0.066945 -1.728250
# 8 100.0 2.339373 0.035168 -2.050225
# 9 100.0 2.102498 0.012707 -3.043281“長度相等的桶”指的是“區間大小相等”,“大小相等的桶”指的是“資料點數量相等”
示例:用特定於分組的值填充缺失值
對於缺失資料的清理工作,有時你會用dropna將其濾除,而有時則可能會希望用一個固定值或由資料集本身所衍生出來的
值去填充NA值。這時就得使用fillna這個工具了。在下面的例子中,用平均值去填充NA值。
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
s=Series(np.random.randn(6))
s[::2]=np.nan #s[::2]從頭到尾,步長為2
print s
#輸出結果如下:
# 0 NaN
# 1 -2.199721
# 2 NaN
# 3 -0.286466
# 4 NaN
# 5 -0.660635
# dtype: float64
print s.fillna(s.mean())
#輸出結果如下:
# 0 -0.570229
# 1 -0.423539
# 2 -0.570229
# 3 0.055381
# 4 -0.570229
# 5 -1.342529
# dtype: float64
#假設需要對不同的分組填充不同的值。只需將資料分組,並使用apply和一個能夠對各資料塊呼叫fillna的函式即可。
#下面是一些有關美國幾個州的示例資料,這些州又被分為東部和西部:
states=['Ohio','New York','Vermont','Florida',
'Oregon','Nevada','California','Idaho']
group_key=['East']*4+['West']*4
print group_key
#輸出結果:
# ['East', 'East', 'East', 'East', 'West', 'West', 'West', 'West']
data=Series(np.random.randn(8),index=states)
data[['Vermont','Nevada','Idaho']]=np.nan
print data
#輸出結果如下:
# Ohio 0.640267
# New York -0.313729
# Vermont NaN
# Florida 2.214834
# Oregon 1.363352
# Nevada NaN
# California 0.265563
# Idaho NaN
# dtype: float64
print data.groupby(group_key).mean()
#輸出結果如下:
# Ohio -0.657227
# New York 0.502025
# Vermont NaN
# Florida 0.045405
# Oregon 0.960563
# Nevada NaN
# California -0.366368
# Idaho NaN
# dtype: float64
# East -0.036599
# West 0.297098
# dtype: float64
#可以用分組平均值去填充NA值,如下所示:
fill_mean=lambda g:g.fillna(g.mean()) #每個空值用g.fillna(g.mean)來填充
print data.groupby(group_key).apply(fill_mean) #按group_key分組,分完組呼叫fill_mean的lambda方法
#即用mean填充Nan值
# Ohio 0.980489
# New York 1.151041
# Vermont 0.786433
# Florida 0.227769
# Oregon -1.550078
# Nevada -1.025264
# California -0.500450
# Idaho -1.025264
# dtype: float64
#此外,也可以在程式碼中預定義各組的填充值。由於分組具有一個name屬性,所以我們可以拿來用一下。
fill_values={'East':0.5,'West':-1}
fill_func=lambda g:g.fillna(fill_values[g.name]) #每個空值用fill_values的name來填充
print data.groupby(group_key).apply(fill_func) #group_key分組,分完後呼叫函式fill_func來填充
#輸出結果如下:
# Ohio 0.095284
# New York -0.232429
# Vermont 0.500000
# Florida 0.039151
# Oregon 1.393373
# Nevada -1.000000
# California 0.756425
# Idaho -1.000000
# dtype: float64示例:隨機取樣和排列
假設你想要從一個大資料集中隨機抽取樣本以進行蒙特卡羅模擬或其他分析工作。“抽取”的方式有很多,
其中一些的效率會比其他的高很多。一個辦法是:選取np.random.permutation(N)的前K個元素,
其中N為完整資料的大小,K為期望的樣本大小。
下面是構造一副英語型撲克牌的一個方式:隨機抽取take,排列np.random.permutation
import numpy as np
from pandas import DataFrame,Series
import pandas as pd
#(1)紅桃(Hearts)、黑桃(Spades)、梅花(Clubs)、方片(Diamonds)
suits=['H','S','C','D']
card_val=(range(1,11)+[10]*3)*4 #1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10, 10, 4組這個數
base_names=['A']+range(2,11)+['J','K','Q']
print base_names
#輸出結果如下:['A', 2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'K', 'Q']
cards=[]
for suit in ['H','S','C','D']:
cards.extend(str(num)+suit for num in base_names)#num為base_name的值,str(num)+suit值
print cards
#輸出結果如下:'AH', '2H', '3H', '4H', '5H', '6H', '7H', '8H', '9H', '10H', 'JH', 'KH', 'QH',H/S/C/D4組與base_name組合
deck=Series(card_val,index=cards)
print deck
#輸出結果如下:index為H組合的如下,還有其它3組,AS..,AC..,AD...
# AH 1 #AH中A是牌名,H是花色 1是牌面的點數
# 2H 2
# 3H 3
# 4H 4
# 5H 5
# 6H 6
# 7H 7
# 8H 8
# 9H 9
# 10H 10
# JH 10
# KH 10
# QH 10
#(2)現在我有了一個長度為52的Series,其索引為牌名,值則是21點或其它遊戲中用於計分的點數,A的點數為1
print deck[:13] #取前13個數,即結果是上面展現的值
#(3)take從列表或者是Series中抽取,permutation(int)返回一個一維從0-9的序列的隨機排列
#現在從整副牌中抽出5張:
def draw(deck,n=5):
return deck.take(np.random.permutation(len(deck))[:n]) #permutation隨機排列的抽取5個數據
print draw(deck)
#輸出結果如下:
# 4H 4
# JH 10
# 7D 7
# 10H 10
# 9H 9
# dtype: int64
#(4)假設想要從每種花色中隨機抽取兩張牌。由於花色是牌名的最後一個字元。所以我們可以據此進行分組
get_suit=lambda card:card[-1] #card是牌名如:AH,card[-1]取牌名的最後一個字元是花色
print deck.groupby(get_suit).apply(draw,n=2) #按card[-1]花色分組,分好後抽取2張
#輸出結果如下:
# C QC 10
# 7C 7
# D QD 10
# 2D 2
# H 3H 3
# 2H 2
# S 4S 4
# 10S 10
# dtype: int64
#(5)另一種辦法:
print deck.groupby(get_suit,group_keys=False).apply(draw,n=2)
#輸出結果如下:
# 10C 10
# 5C 5
# 8D 8
# 5D 5
# 2H 2
# 4H 4
# 6S 6
# 10S 10
# dtype: int64示例:分組加權平均數和相關係數
根據groupby的“拆分(groupBy)-應用(apply)-合併(merge,concate)”,DataFrame的列與列之間或
兩個Series之間的運算(比如分組加權平均)成為一種標準作業。以下面這個資料集為例,它含有分組鍵、
值以及一些權重值:
import pandas as pd
import numpy as np
from pandas import DataFrame,Series
df=DataFrame({'category':['a','a','a','a','b','b','b','b'],
'data':np.random.randn(8),
'weight':np.random.rand(8)})
print df
#輸出結果如下:
# category data weight
# 0 a 0.613657 0.723545
# 1 a 0.973732 0.845376
# 2 a 0.201082 0.634316
# 3 a 0.597991 0.833267
# 4 b -1.017848 0.355760
# 5 b -0.017974 0.963866
# 6 b -0.352486 0.076372
# 7 b -0.975237 0.147921
#然後可以利用category計算分組加權平均數:
grouped=df.groupby('category') #按category分組
get_wavg=lambda g: np.average(g['data'],weights=g['weights']) #g['data']的平均值,weights加上權重的平均值
print grouped.apply(get_wavg)
#下面舉一個股票的收盤
close_px=pd.read_csv('cho9/stock_px.csv',parse_dates=True,index_col=0)
print close_px[-4:]
#計算收益率(通過百分比變化計算):
rets=close_px.pct_change().dropna()
spx_corr=lambda x:x.corrwith(x['SPX'])
by_year=rets.groupby(lambda x:x.year)
print by_year.apply(spx_corr)
#還可以計算列與列之間的相關係數:
by_year.apply(lambda g:g['AAPL'].corr(g['MSFT']))
示例:面向分組的線性迴歸
順著上一例子繼續,你可以用groupby執行更為複雜的分組統計分析,只要函式返回的是pandas物件或標量值即可。
例:我可以定義下面這個regress函式(利用statsmodels)庫對各資料塊執行普通最小二乘法迴歸(OLS)。
import statesmodels.api as sm 利用sm.OLS(Y,X).fit()最小二乘法
#利用OLS二乘法線性迴歸
import statesmodels.api as sm
def regress(data,yvar,xvars):
Y=data[yvar]
X=data[xvars]
X['intercept']=1.
result=sm.OLS(Y,X).fit()
return result.params
#現在,為了按年計算AAPL對SPX收益率的線性迴歸:
print by_year.apply(regress,'AAPL',['SPX'])透視表和交叉表:透視表pivot_table用於分組求和(例求每個月買出的帽子總和)
透視表是各種電子表格程式和其它分析軟體中一種常見的資料彙總工具。它根據一個或多個鍵對資料進行聚合,並根據
行和列上的分組鍵將資料分配到各個矩形區域中。
在python和pandas中,可以用groupby功能以及(能夠利用層次化索引的)重塑運算製作透視表。
DataFrame有一個pivot_table方法,還有一個pand.pivot_table函式。pivot_table還可以新增分項小計(也叫margins)
import pandas as pd
import numpy as np
from pandas import DataFrame,Series
#(1)回到小費資料集,假設我想要根據sex和smoker計算分組平均數(pivot_table的預設聚合型別),並將sex和smoker放到行上
print tips.pivot_table(rows=['sex','smoker'])
#輸出結果如下:
# size tip tip_pct total_bill
# sex smoker
# Female No 2.59 2.77 0.15 18.10
# Yes 2.24 2.93 0.18 17.97
# Male No 2.71 3.11 0.16 19.79
# Yes 2.50 3.05 0.15 22.97
#上面的對於groupby來說也是很簡單就可以做到的事情。
#(2)現在我們只想聚合tip_pct和size,而且想根據day進行分組。我將smoker放到列上,把day放到行上。
tips.pivot_table(['tip_pct','size'],rows=['sex','day'])
#輸出結果如下:
# tip_pct size
# smoker No Yes No Yes
# sex day
# Female Fri 0.16 0.2 2.5 2.0
# SAT 0.14 0.16 2.3 2.2
# Male Fri 0.13 0.14 2.0 2.1
# SAT 0.16 0.13 2.65 2.62
#(3)還可以對這個表作進一步處理,傳入margins=True新增分項小計。這將會新增標籤為All的行和列。
#其值對應於單個等級中所有資料的分組統計。
# 在下面的這個例子中,All值為平均數:不單獨考慮菸民與非菸民(All列),不單獨考慮行分組兩個級別
#中的任何單項(All)行。
tips.pivot_table(['tip_pct','size'],rows=['sex','day'],
cols='smoker',margins=True)
#輸出結果如下:
# tip_pct size
# smoker No Yes No Yes All
# sex day
# Female Fri 2.16 2.2 2.5 2.0 0.199
# SAT 2.14 2.16 2.3 2.2 0.156
# Male Fri 2.13 2.14 2.0 2.1 0.180
# SAT 2.16 2.13 2.65 2.62 0.165
# All 2.66 2.40 2.56 2.22 0.160
#(4)要使用其它的聚合函式,將其傳給aggfunc即可
#例:使用count或len可以得到有關分組大小的交叉表:
tips.pivot_table('tip_pct',rows=['sex','smoker'],cols='day',
aggfunc=len,margins=True) #行:'sex','smoker';列:'day';margins=True分項小計All;len方法
#輸出結果如下:
# day Fri Sat Sun Thur All
# sex smoker
# Female No 2 13 14 25 54
# Yes 7 15 4 7 33
# Male No 2 32 43 20 97
# Yes 8 27 15 10 60
# All 19 87 76 62 244
#(5)如果存在空的組合(也就是NA),可能會希望設定一個fill_value:
tips.pivot_table('size',rows=['time','sex','smoker'],
cols='day',aggfunc='sum',fill_value=0)
#輸出結果如下:
# day Fri Sat Sun Thur
# time sex smoker
# Dinner Female No 2 30 43 2
# Yes 8 33 10 0
# Male No 2 85 143 0
# Yes 8 27 15 10
# Lunch Female No 3 0 0 60
# Yes 6 0 0 17
# Male No 0 0 0 50
# Yes 5 0 0 23
pivot_table的引數
引數名 說明
values 待聚合的列的名稱。預設聚合所有數值列
rows 用於分組的列名或其他分組鍵,出現在結果透視表的行
cols 用於分組的列名或其他分組鍵,出現在結果透視表的列
aggfunc 聚合函式或函式列表,預設為'mean'.可以是任何對groupby有效的函式
fill_value 用於替換結果表中的缺失值
margins 新增行,列小計和總計,預設為False
交叉表:crosstable(兩個變數)
import pandas as pd
import numpy as np
from pandas import DataFrame,Series
#交叉表:crosstab
#交叉表是一種用於計算分組頻率的特殊透透表。
#這個範例資料很典型,取自交駐表的Wikipedia頁:
data=DataFrame({'Sample':[1,2,3,4,5,6,7,8,9,10],
'Gender':['Female','Male','Female','Male','Male','Male',
'Female','Female','Male','Female'],
'Handedness':['Right-handed','Left-handed','Right-handed','Right-handed',
'Left-handed','Right-handed','Right-handed','Left-handed',
'Right-handed','Right-handed']})
# print data
#輸出結果如下:
# Gender Handedness Sample
# 0 Female Right-handed 1
# 1 Male Left-handed 2
# 2 Female Right-handed 3
# 3 Male Right-handed 4
# 4 Male Left-handed 5
# 5 Male Right-handed 6
# 6 Female Right-handed 7
# 7 Female Left-handed 8
# 8 Male Right-handed 9
# 9 Female Right-handed 10
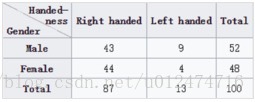
#(1)假設我們想要根據性別和用手習慣對這段資料進行統計彙總。
#雖然可以用pivot_table實現該功能,但是用pandas.crosstab函式更方便
print pd.crosstab(data.Gender,data.Handedness,margins=True) #index,columns,margins
#輸出結果如下:
# Handedness Left-handed Right-handed All
# Gender
# Female 1 4 5
# Male 2 3 5
# All 3 7 10
#(2)crosstab的前兩個引數可以是陣列、Series或陣列列表。再比如對小費資料集:
print pd.crosstab([tips.time,tips.day],tips.smoker,margins=True)
#輸出結果如下:
# smoker No Yes All
# time day
# Dinner Fri 3 9 12
# Sat 45 42 87
# Sun 57 19 76
# Thur 1 0 1
# Lunch Fri 1 6 7
# Thur 44 17 61
# All 151 93 244 示例:2012聯邦選舉委員會資料庫
用到了:mapping,get,pivot_table
import pandas as pd
import numpy as np
from pandas import DataFrame,Series
import os
import matplotlib.pyplot as plt
#獲取檔案的路徑
path1=os.path.abspath('..') #獲取當前指令碼所在路徑的上一級路徑
print path1
#(1)先將資料載入進來:
fec=pd.read_csv(path1+'/pydata-book-2nd-edition/datasets/fec/P00000001-ALL.csv')
print fec.ix[123456] #ix是取行索引ix[2]按下標取,下標從0開始算
#輸出結果如下:
# cmte_id C00431445
# cand_id P80003338
# cand_nm Obama, Barack
# contbr_nm ELLMAN, IRA
# contbr_city TEMPE
# contbr_st AZ
# contbr_zip 852816719
# contbr_employer ARIZONA STATE UNIVERSITY
# contbr_occupation PROFESSOR
# contb_receipt_amt 50
# contb_receipt_dt 01-DEC-11
# receipt_desc NaN
# memo_cd NaN
# memo_text NaN
# form_tp SA17A
# file_num 772372
# Name: 123456, dtype: object
#(2)上面的資料中沒有黨派資訊,因此最好把它加進去,通過unique,可以獲取全部的候選人名單。
unique_cands=fec.cand_nm.unique() #取fec(Series)中的cand_nm欄位的值
print unique_cands
#輸出結果如下:
# ['Bachmann, Michelle' 'Romney, Mitt' 'Obama, Barack'
# "Roemer, Charles E. 'Buddy' III" 'Pawlenty, Timothy' 'Johnson, Gary Earl'
# 'Paul, Ron' 'Santorum, Rick' 'Cain, Herman' 'Gingrich, Newt'
# 'McCotter, Thaddeus G' 'Huntsman, Jon' 'Perry, Rick']
print unique_cands[2]
#輸出結果如下:
# Obama, Barack
#(3)最簡單的辦法是利用字典說明黨派關係:
parties={'Bachmann, Michelle':'Republican',
'Romney, Mitt':'Republican',
'Obama, Barack':'Democrat',
"Roemer, Charles E. 'Buddy' III":'Republican',
'Pawlenty, Timothy':'Republican',
'Johnson, Gary Earl':'Republican',
'Paul, Ron':'Republican',
'Santorum, Rick':'Republican',
'Cain, Herman':'Republican',
'Gingrich, Newt':'Republican',
'McCotter, Thaddeus G':'Republican',
'Huntsman, Jon':'Republican',
'Perry, Rick':'Republican'}
#現在通過這個對映以及Series物件的map方法,你可以根據候選人姓名得到一組黨派資訊
print fec.cand_nm[123456:123461]
#輸出結果如下:
# Obama, Barack
# 123456 Obama, Barack
# 123457 Obama, Barack
# 123458 Obama, Barack
# 123459 Obama, Barack
# 123460 Obama, Barack
# Name: cand_nm, dtype: object
#(4)將其新增為一新列,使用map對映,有幾個欄位都對映為同一個,則values值相加
fec['party']=fec.cand_nm.map(parties) #fec.cand_nm有兩個值Obama, Barack,map(parties)對映後就是找出Obama, Barack對應parties的黨派
print fec['party'].value_counts()
#輸出結果如下:
# Democrat 593746
# Republican 407985
# Name: party, dtype: int64
#(5)這裡有兩個需要注意的地方。第一,該資料既包括贊助也包括退款(負的出資額)
#value_counts對值進行統計
print (fec.contb_receipt_amt>0).value_counts()
#輸出結果如下:
# True 991475
# False 10256
# Name: contb_receipt_amt, dtype: int64
#(6)為了簡化分析過程,限定該資料集只能有正的出資額:
fec=fec[fec.contb_receipt_amt>0]
#由於Barack Obama和Mitt Romney是最主要的兩名候選人,所以專門準備了一個子集,只包含針對他們兩人的競選活動的贊助商用:
fec_mrbo=fec[fec.cand_nm.isin(['Obama,Barack','Romney,Mitt'])]
# print fec_mrbo[-2:]
#(7)根據職業和僱主統計贊助資訊:
#例如律師們更傾向於民主黨
#首先,根據職業計算出資總額
print fec.contbr_occupation.value_counts()[:10] #統計出不同職業的總計
#輸出結果如下:
# RETIRED 233990
# INFORMATION REQUESTED 35107
# ATTORNEY 34286
# HOMEMAKER 29931
# PHYSICIAN 23432
# INFORMATION REQUESTED PER BEST EFFORTS 21138
# ENGINEER 14334
# TEACHER 13990
# CONSULTANT 13273
# PROFESSOR 12555
# Name: contbr_occupation, dtype: int64
#(8)不難看出,許多職業都涉及相同的基本工作型別,或者同一樣東西有多種變體。
#下面程式碼可以清理一些這樣的資料(將一個職業資訊對映到另一個)。注意:這裡巧妙地利用了dict.get,它允許沒有對映
#關係的職業也能"通過":
occ_mapping={'INFORMATION REQUESTED':'NOT PROVIDED',
'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED',
'INFORMATION REQUESTED(BEST EFFORTS)':'NOT PROVIDED',
'C.E.O':'CEO'}
#如果沒有提供相關對映,則返回x
f=lambda x:occ_mapping.get(x,x) #occ_mapping,get如有則返回x的mapping的值,如果沒有則返回原值
fec.contbr_occupation=fec.contbr_occupation.map(f)
print fec.contbr_occupation.value_counts()[:10] #將前面的3個REQUESTED都對映為'NOT PROVIDED'
#輸出結果如下:
# RETIRED 233990
# NOT PROVIDED 56245
# ATTORNEY 34286
# HOMEMAKER 29931
# PHYSICIAN 23432
# ENGINEER 14334
# TEACHER 13990
# CONSULTANT 13273
# PROFESSOR 12555
# NOT EMPLOYED 9828
# Name: contbr_occupation, dtype: int64
#(9)下面對僱主也進行了同樣的處理:
print fec.contbr_employer.value_counts()[:10]
#輸出結果如下:
# RETIRED 206675
# SELF-EMPLOYED 94505
# NOT EMPLOYED 45877
# INFORMATION REQUESTED 36135
# SELF 24385
# INFORMATION REQUESTED PER BEST EFFORTS 22260
# NONE 19929
# HOMEMAKER 18269
# SELF EMPLOYED 6274
# REQUESTED 4233
# Name: contbr_employer, dtype: int64
emp_mapping={'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDED',
'INFORMATION REQUESTED':'NOT PROVIDED',
'SELF':'SELF-EMPLOYED',
'SELF EMPLOYED':'SELF-EMPLOYED',}
#如果沒有提供相關的對映,則返回x:用get
f=lambda x:emp_mapping.get(x,x)
fec.contbr_employer=fec.contbr_employer.map(f)
print fec.contbr_employer.value_counts()[:10]
#輸出結果如下:
# RETIRED 206675
# SELF-EMPLOYED 125164
# NOT PROVIDED 58396
# NOT EMPLOYED 45877
# NONE 19929
# HOMEMAKER 18269
# REQUESTED 4233
# UNEMPLOYED 2514
# US ARMY 1817
# STUDENT 1786
# Name: contbr_employer, dtype: int64
#(10)可以通過pivot_table根據黨派和職業對資料進行聚合,然後過濾掉總出資額不足200萬美元的資料:
by_occupation=fec.pivot_table('contb_receipt_amt',index='contbr_occupation',
columns='party',aggfunc='sum')
print by_occupation
#輸出結果如下:
# party Democrat Republican
# contbr_occupation
# MIXED-MEDIA ARTIST / STORYTELLER 100.0 NaN
# AREA VICE PRESIDENT 250.0 NaN
# RESEARCH ASSOCIATE 100.0 NaN
# TEACHER 500.0 NaN
# THERAPIST 3900.0 NaN
# 'MIS MANAGER NaN 177.60
# (PART-TIME) SALES CONSULTANT & WRITER NaN 285.00
# (RETIRED) NaN 250.00
# - 5000.0 2114.80
# -- NaN 75.00
over_2mm=by_occupation[by_occupation.sum(1)>2000000]
print over_2mm
#輸出結果如下:
# party Democrat Republican
# contbr_occupation
# ATTORNEY 11141982.97 7.477194e+06
# C.E.O. 1690.00 2.592983e+06
# CEO 2074284.79 1.640758e+06
# CONSULTANT 2459912.71 2.544725e+06
# ENGINEER 951525.55 1.818374e+06
# EXECUTIVE 1355161.05 4.138850e+06
# HOMEMAKER 4248875.80 1.363428e+07
# INVESTOR 884133.00 2.431769e+06
# LAWYER 3160478.87 3.912243e+05
# MANAGER 762883.22 1.444532e+06
# NOT PROVIDED 4866973.96 2.023715e+07
# OWNER 1001567.36 2.408287e+06
# PHYSICIAN 3735124.94 3.594320e+06
# PRESIDENT 1878509.95 4.720924e+06
# PROFESSOR 2165071.08 2.967027e+05
# REAL ESTATE 528902.09 1.625902e+06
# RETIRED 25305116.38 2.356124e+07
# SELF-EMPLOYED 672393.40 1.640253e+06
#(11)把這些資料做成柱狀圖:
over_2mm.plot(kind='barh')
plt.show()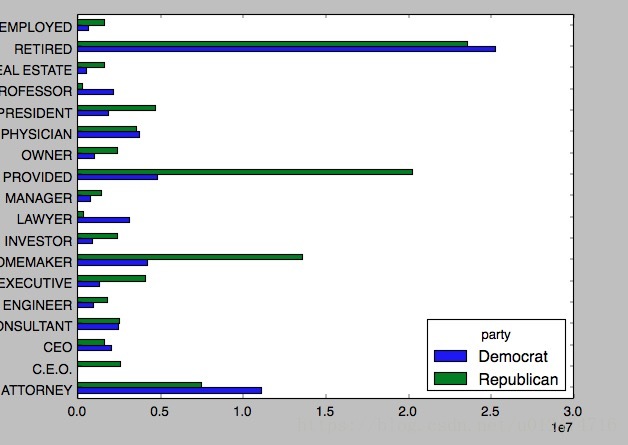
對各黨派總出資額最高的職業:繼續上面的例子
pandas中的order:是對值進行排序,或者用sort_values也是對值進行排序
pandas中的sort:是對行或列進行排序
#獲取檔案的路徑
path1=os.path.abspath('..') #獲取當前指令碼所在路徑的上一級路徑
print path1
#(1)先將資料載入進來:
fec=pd.read_csv(path1+'/pydata-book-2nd-edition/datasets/fec/P00000001-ALL.csv')
# print fec.ix[123456] #ix是取行索引ix[2]按下標取,下標從0開始算
#輸出結果如下:
# cmte_id C00431445
# cand_id P80003338
# cand_nm Obama, Barack
# contbr_nm ELLMAN, IRA
# contbr_city TEMPE
# contbr_st AZ
# contbr_zip 852816719
# contbr_employer ARIZONA STATE UNIVERSITY
# contbr_occupation PROFESSOR
# contb_receipt_amt 50
# contb_receipt_dt 01-DEC-11
# receipt_desc NaN
# memo_cd NaN
# memo_text NaN
# form_tp SA17A
# file_num 772372
# Name: 123456, dtype: object
fec=fec[fec.contb_receipt_amt>0]
print fec
#由於Barack Obama和Mitt Romney是最主要的兩名候選人,所以專門準備了一個子集,只包含針對他們兩人的競選活動的贊助商用:
fec_mrbo=fec[fec.cand_nm.isin(['Bachmann, Michelle','Perry, Rick'])] #無Obama的資料則換其它兩位
print fec_mrbo
#(1)看一下對Obama和Romney總出資額最高的職業和企業。
#我們先對候選人進行分組,然後使用本章前面介紹的那種求取最大值的方法:
def get_top_amounts(group,key,n=5):
totals=group.groupby(key)['contb_receipt_amt'].sum() #按key分組,然後取出'contb_receipt_amt'值,再對它求和
#根據key對totals進行降序排列:order已經沒了,改成sort_values也是對值進行排序
return totals.sort_values(ascending=False)[n:]
#(2)然後根據職業和僱主進行聚合:
grouped=fec_mrbo.groupby('cand_nm')
print grouped.apply(get_top_amounts,'contbr_occupation',n=7)
#輸出結果如下
# cand_nm contbr_occupation
# Bachmann, Michelle ATTORNEY 47084.00
# EXECUTIVE 38526.00
# CONSULTANT 32768.50
# C.E.O. 32123.00
# FARMER 25614.00
# MANAGER 24621.00
# SALES 22298.00
# CEO 21526.00
# INVESTOR 21111.00
# NONE 20253.00
# BUSINESS OWNER 15518.00
# SELF EMPLOYED 14686.00
# ACCOUNTANT 13304.00
# DIRECTOR 12131.00
# N 9850.00
# DOCTOR 9550.00
# CPA 9280.00
# REAL ESTATE 9275.00
# PASTOR 8870.00
# NURSE 8622.00
# LAWYER 8418.00
# CONTRACTOR 8319.00
# SELF-EMPLOYED 8182.00
# SELF 8038.00
# PILOT 7935.00
# PROFESSOR 7920.00
# MACHINIST 7905.00
# SMALL BUSINESS OWNER 7857.00
# VENTURE CAPITALIST 7500.00
# DENTIST 7335.00
# ...
# Perry, Rick MANAGING ATTORNEY 100.00
# SW TEST MGR 100.00
# LAW ENFORCEMENT 100.00
# CONSULTING ABSTRACTOR 100.00
# SALES PRINTING 100.00
# PROGRAMMER/RETIRED 100.00
# DIRECTOR ACQUISITIONS 100.00
# SALES MGR. 100.00
# SELF-EMP 100.00
# OPS SUPERVISOR 100.00
# SENIOR AUDIO DSP ENGINEER 100.00
# FEDERAL AGENT 100.00
# SENIOR LOAN OFFICER - CORPORATE 100.00
# AEROSPACE ENGINEER 100.00
# NATIONAL ACCOUNTS MANAGER 100.00
# ASST. D. A. RET'D 100.00
# TEXAS TEACHER 75.00
# RESEARCH ASST. 60.36
# JUNIOR BUYER 50.00
# LAB TECHNICIAN 50.00
# CUSTODIAN 50.00
# CHEM LAB SUPER 50.00
# SCHOOL COUNSELOR 50.00
# PHYSICIAN/MEDICAL DIRECTOR 30.00
# SSGT / NCOIC EVALUATIONS 25.00
# PRES. & CEO 25.00
# TAX DIRECTOR 25.00
# CEO/IT CONSULTANT 25.00
# APP DEV 25.00
# SPEC. ED. INSTR. AIDE 25.00
# Name: contb_receipt_amt, Length: 3211, dtype: float64
對出資額