
Group by 和distinct對比
阿新 • • 發佈:2018-11-06
** Group by 和distinct對比**CREATE TABLE sbtest1 (id int(11) NOT NULL AUTO_INCREMENT,k int(11) NOT NULL DEFAULT '0',c char(120) NOT NULL DEFAULT '',pad char(60) NOT NULL DEFAULT '',
PRIMARY KEY (id),
KEY k_1 (k)
) ENGINE=InnoDB AUTO_INCREMENT=10000001 DEFAULT CHARSET=utf8;
1000w資料量
1、 對於主鍵Group by的執行計劃
Distinct的執行計劃
可以看到group by使用了主鍵,而distinct使用了輔助索引k_1
這說明了distinct可能是一種統計操作,也就是Innodb在有輔助索引時候,統計會走輔助索引,如下圖,進行count(*)也是走的k_1輔助索引。

2、 對於輔助索引Group by的執行計劃
Distinct的執行計劃
通過以上對比,可以看出來他們是等價的,執行計劃一致。
3、 對於普通欄位Group by的執行計劃,這裡做了一個order by null的處理,就是不排序
Distinct的執行計劃,按理說,如果distinct要是統計的話為啥沒有走k_1
通過以上對比,可以看出來也是等價的,執行計劃一致。
4、 Group by 需要聚合,而distinct不需要聚合
5、 Group by 比 distinct效率高,distinct需要讀取所有記錄,而group by只需要讀取分組的數量的記錄。
set profiling=1;
select distinct(k) from sbtest1
select k from sbtest1 group by k
再通過show profiles檢視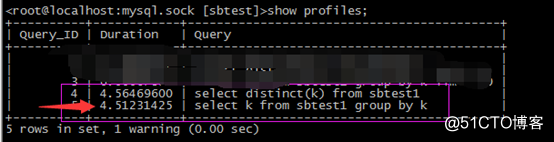
Group by比distinct快了0.05秒多