
爬蟲-京東商品搜尋頁爬取
阿新 • • 發佈:2018-11-07
難點:
-
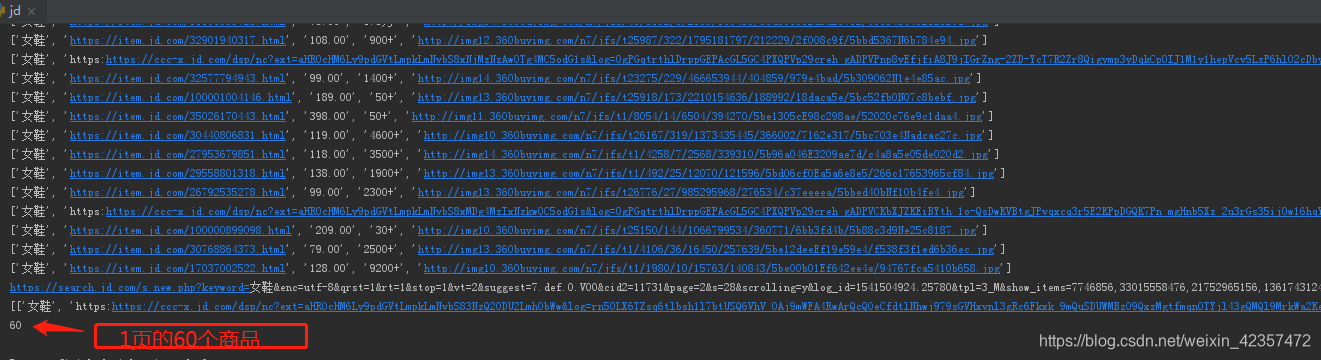
1,京東首次搜尋只展示30條資料,這個可以直接在原始碼取到,但是也要注意不同頁面抓取規則可能不一樣(頁面結構有變化需要判斷)
-
2,繼續下拉可以在ajax獲取到另外30條資料,但是這個requests提交需要各種引數,很麻煩,我這暫時沒有找到自動填寫的方法,只能根據搜尋需求人工改寫下
-
解析頁面資訊有好多坑,比如有的價格不全,同一個頁面需要解析的規則就不一樣
-
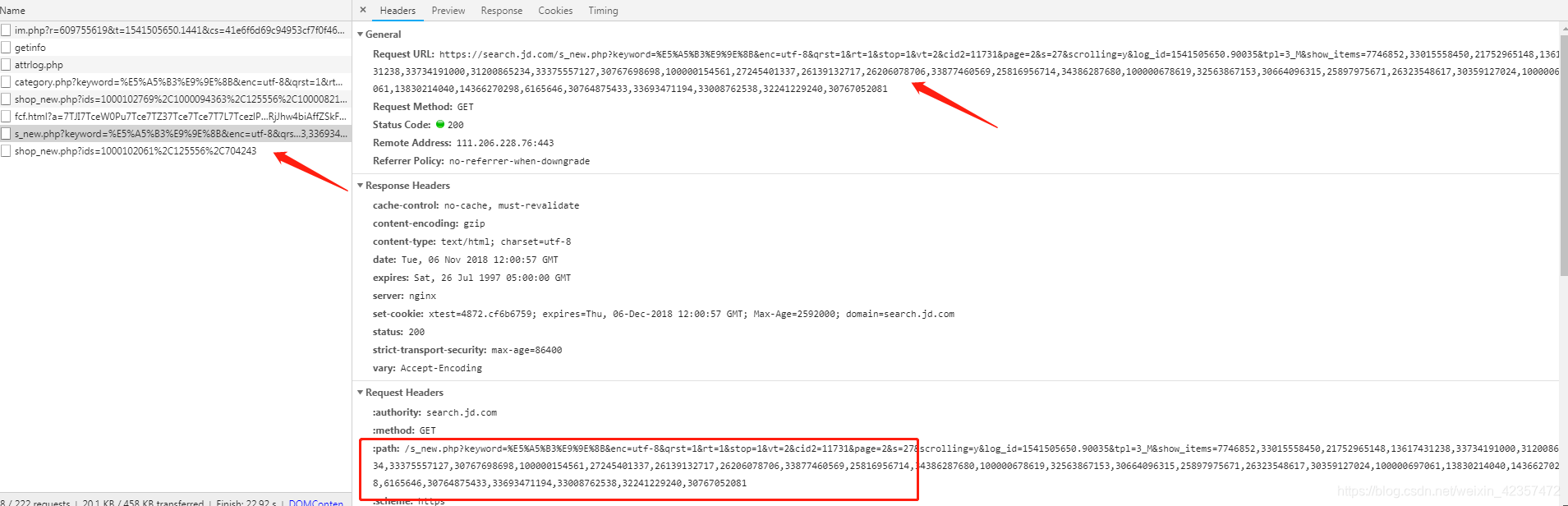
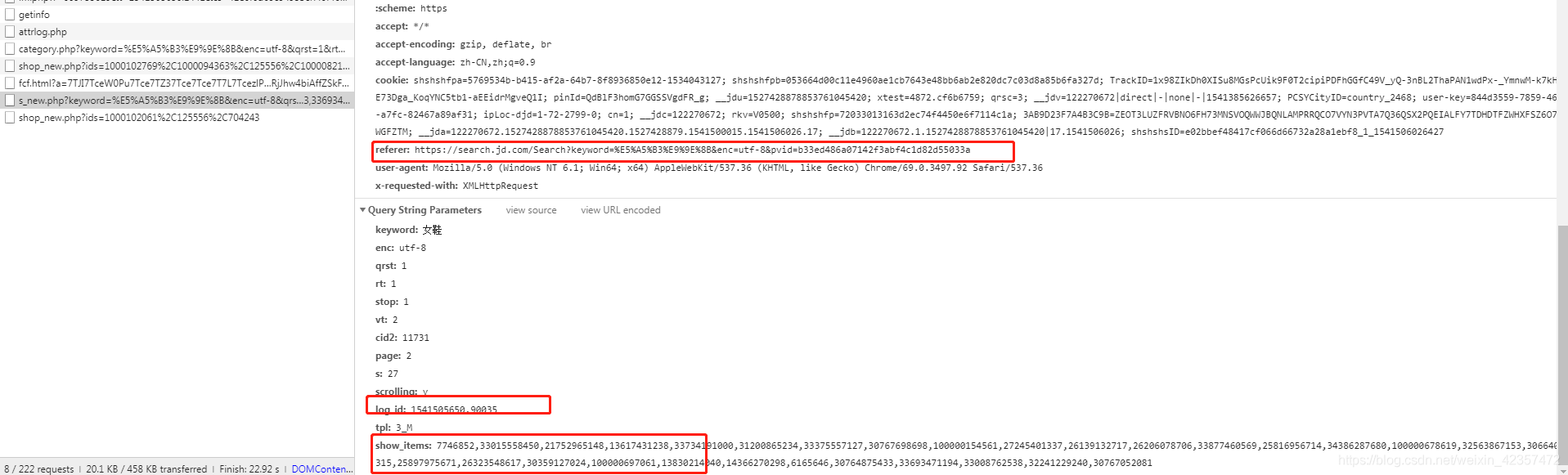
ajax引數,headers的path和referer和data的login_id和show_time這是在前30個上篇頁程式碼裡提取到拼湊的
程式碼:
import requests from lxml import etree import re keyword=input("請輸入查詢商品:") print(type(keyword)) g=[] for i in range(1,2): url="https://search.jd.com/Search?keyword={}&enc=utf-8&page={}".format(keyword,i*2-1) header={ # ":authority":"search.jd.com", # ":method":"GET", # ":scheme":" https", "upgrade - insecure - requests": "1", "user-agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36" } html=requests.get(url=url,headers=header) html.encoding="utf-8" # print(html.text) html=html.text newhtml=etree.HTML(html) print(newhtml) log_id=re.findall("log_id:'(.*?)'",html,re.S)[0] cid=re.findall("LogParm.*?cid:(.*?),",html,re.S)[0] print(cid) sku_id=newhtml.xpath('//*[@id="J_goodsList"]/ul/li/@data-sku') p_list=",".join('%s' % id for id in sku_id) print(sku_id) print(p_list) if len(newhtml.xpath('//*[@id="J_goodsList"]/ul/li//div[@class="p-price"]/strong/i/text()'))==30: img_url=newhtml.xpath('//div[@id="J_goodsList"]/ul/li//div[@class="p-img"]//img/@source-data-lazy-img') print(img_url) price=newhtml.xpath('//*[@id="J_goodsList"]/ul/li//div[@class="p-price"]/strong/i/text()') title=newhtml.xpath('//*[@id="J_goodsList"]/ul/li//div[contains(@class,"p-name")]/a/em/text()')#.strip() # title="".join(title) # title=title.split(":") product_url=newhtml.xpath('//*[@id="J_goodsList"]/ul/li//div[contains(@class,"p-name")]//a/@href') # commit=html.xpath('//*[@id="J_goodsList"]/ul/li[1]/div/div[4]/strong/text()')#.strip() commit=newhtml.xpath('//*[@id="J_goodsList"]/ul/li//div[@class="p-commit"]/strong/a/text()')#.strip() # shop_name=newhtml.xpath('//*[@id="J_goodsList"]/ul/li//div[@class="p-shop"]/span/a/text()') for i in range(30): list_1=[keyword,"https:"+product_url[i],price[i],commit[i],"http:"+img_url[i]] print(list_1) g.append(list_1) else: for n in range(30): if newhtml.xpath('//*[@id="J_goodsList"]/ul/li[%d]//div[@class="p-price"]/strong/i/text()'%(n+1)): img_url = newhtml.xpath('//div[@id="J_goodsList"]/ul/li[%d]//div[@class="p-img"]//img/@source-data-lazy-img'%(n+1)) # print(img_url) price = newhtml.xpath('//*[@id="J_goodsList"]/ul/li[%d]//div[@class="p-price"]/strong/i/text()'%(n+1)) title = newhtml.xpath('//*[@id="J_goodsList"]/ul/li[%d]//div[contains(@class,"p-name")]/a/em/font[1]/text()'%(n+1)) # .strip() # title="".join(title) # title=title.split(":") product_url = newhtml.xpath('//*[@id="J_goodsList"]/ul/li[%d]//div[contains(@class,"p-name")]//a/@href'%(n+1)) # commit=html.xpath('//*[@id="J_goodsList"]/ul/li[1]/div/div[4]/strong/text()')#.strip() commit = newhtml.xpath('//*[@id="J_goodsList"]/ul/li[%d]//div[@class="p-commit"]/strong/a/text()'%(n+1)) # .strip() list_2 = [keyword , "https:"+product_url[0], price[0], commit[0], "http:"+img_url[0]] print(list_2) g.append(list_2) else: img_url = newhtml.xpath('//div[@id="J_goodsList"]/ul/li[%d]//div[@class="p-img"]//img/@source-data-lazy-img'%(n+1)) # print(img_url) price = newhtml.xpath('//*[@id="J_goodsList"]/ul/li[%d]//div[@class="p-price"]/strong/@data-price'%(n+1)) title = newhtml.xpath('//*[@id="J_goodsList"]/ul/li[%d]//div[contains(@class,"p-name")]/a/em/font[1]/text()'%(n+1)) # .strip() # title="".join(title) # title=title.split(":") product_url = newhtml.xpath('//*[@id="J_goodsList"]/ul/li[%d]//div[contains(@class,"p-name")]//a/@href'%(n+1)) # commit=html.xpath('//*[@id="J_goodsList"]/ul/li[1]/div/div[4]/strong/text()')#.strip() commit = newhtml.xpath('//*[@id="J_goodsList"]/ul/li[%d]//div[@class="p-commit"]/strong/a/text()'%(n+1)) # .strip() list_3 = [keyword , "https:"+product_url[0], price[0], commit[0], "http:"+img_url[0]] print(list_3) g.append(list_3) header1={ 'authority': 'search.jd.com', 'method': 'GET', 'scheme': 'https', "path": "/s_new.php?keyword=%E5%A5%B3%E9%9E%8B&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E5%A5%B3%E9%9E%8B&cid2=11731&page=2&s=27&scrolling=y&log_id=1541499650.39561&tpl=3_M", "referer": "https://search.jd.com/Search?keyword=%E5%A5%B3%E9%9E%8B&enc=utf-8&wq=%E5%A5%B3%E9%9E%8B&pvid=11f0d7bbd549489ea0ff9c18280008e3", "user-agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36", "x-requested-with": "XMLHttpRequest", 'Cookie': '__jdv=122270672|direct|-|none|-|1541463047359; __jdc=122270672; __jdu=15414630473591816564566; PCSYCityID=country_2468; shshshfpa=06433229-fec9-71f1-ee80-5e4d2053f3b2-1541463051; xtest=1192.cf6b6759; ipLoc-djd=1-72-2799-0; shshshfpb=29d35c4b6bd0a4874aff06fde9a21bb415be00d7767a8105a1c51da983; rkv=V0000; qrsc=3; mt_xid=V2_52007VwMWV11dVVgeTB9eAW8DG1JaXFVfG04ebFVuVkJQVVFSRh5NSgsZYgERB0FQW1gYVRsJAjcFFFZZWQAKGHkaXQVuHxJSQVlVSx5AElgFbAcbYl9oUmocThBdBWAFE1RtWFdcGA%3D%3D; 3AB9D23F7A4B3C9B=3DVBCHQ2ZQDBE7WHQNBTXMZIG2LRSITXIEP5G2KLLX7F665PL45NH2F4HIBZ7GYW7TBTBPQEGC27GWLCFQV3UVL2EQ; _gcl_au=1.1.201025286.1541468212; shshshfp=72033013163d2ec74f4450e6f7114c1a; __jda=122270672.15414630473591816564566.1541463047.1541468202.1541471285.4; wlfstk_smdl=607dk6qcnoo82vqtspoz07g6hf0a8h6f; TrackID=1aDczZLZIOi53VMMgAJw6R6jU_JwW0j0Q3kPXr2DBxehnhKeoPkixGxlJ1XFOqdIqsW5IHw3HorqriaLnpP7qx_rF45aE522LK_J72xHV0XU; thor=A2F041014FF97AD3CBE36A18D7A197BD280A27D92876522948662EEBEF7FAAE9D4EE69FADC66DD46EC5FB2DA15E3A77A2B031AB32800A19FDD8BF76438EC46467045B795A654A74E62B5D2C1BEE34F0566FBA73C6ADB9AE74640B83FFF64DB25EF4E84890A70EC7A2A054562CA4A906EBC3E8B8DE2E06A32A741577FBDE89130428D846DC18B195004A8AFE75665A1DA43AAC5AC651F19D0CCB3FDF2AD68D88A; pinId=Gs1wY_18rJHCJb2AcSkHc7V9-x-f3wj7; pin=jd_605257796165b; unick=%E6%B6%9F%E6%BC%AA%E5%9E%84; ceshi3.com=103; _tp=wwla5rjsr%2FuWFA%2FmLBXQrei5UhIKee6ThwQXFShjs60%3D; _pst=jd_605257796165b; __jdb=122270672.4.15414630473591816564566|4.1541471285; shshshsID=eaceb1587ae4eaba8646ed1b230970b4_2_1541472058709' } url1="https://search.jd.com/s_new.php?keyword=%s&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&suggest=7.def.0.V00&cid2=%s&page=2&s=28&scrolling=y&log_id=%s&tpl=3_M&show_items=%s"%(str(keyword),cid,log_id,p_list) html1=requests.get(url=url1,headers=header1) html1.encoding="utf-8" html2=html1.text # print(html2) html3=etree.HTML(html2) product_url=html3.xpath('//div[contains(@class,"p-name")]//a/@href') price=html3.xpath('//div[@class="p-price"]/strong/i/text()') commit=html3.xpath('//div[@class="p-commit"]/strong/a/text()') img_ul=html3.xpath('//div[@class="p-img"]//img/@source-data-lazy-img') title=html3.xpath('//div[contains(@class,"p-name")]/a/em') for i in range(30): list_4 = [keyword, "https:" + product_url[i], price[i], commit[i], "http:" + img_url[i]] print(list_4) g.append(list_4) print(url1) print(g) print(len(g))