
CSV檔案的讀取,TensorFlow和pandas
阿新 • • 發佈:2018-11-07
csv檔案的讀取,有兩種方法:呼叫pandas庫函式或者直接用TensorFlow讀取,
1、呼叫pandas
data.csv是自己隨便搞的一個數據檔案,資料樣例和讀取程式碼如下:
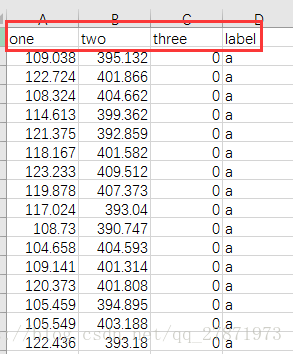
import tensorflow as tf import pandas as pd def pd_read_csv(): data_frame = pd.read_csv("data.csv", sep=",") data1 = [] data2 = [] data3 = [] data4 = [] for index in data_frame.index: data_row = data_frame.loc[index] data1.append(data_row["one"]) data2.append(data_row["two"]) data3.append(data_row["three"]) data4.append(data_row["label"]) return (data1,data2,data3,data4) data1, data2, data3, data4 = pd_read_csv()
資料的第一行都是有特徵的,比如one、two.......,當然也可以是純數字,只需要修改如下:
#部分程式碼修改
data_frame = pd.read_csv("data.csv", header=None)
dataset = data_frame.values
data_x = dataset[:, 0:3].astype(float)#前三列為data1-data3
label = dataset[:, 3] #第四列為data4或者label
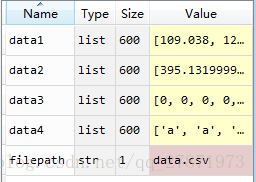
得到的結果為:
2、使用TensorFlow方法
TensorFlow讀取csv檔案相比較pandas要複雜,還是使用上面的資料檔案,只不過把第一行的特徵刪掉 ,data1是data的副本,TensorFlow這個讀取方法可以一次讀取多個檔案。過程如下:
- 產生檔名列表,可以一次讀取多個csv檔案;
- 讀取原始資料;
- 解析讀出的原始資料,轉化成數值資料或指定格式的資料;
- 開啟多執行緒協調器,啟動輸入管道;
- 讀取結束。
import tensorflow as tf filename_queue = tf.train.string_input_producer(["data.csv", "data1.csv"]) reader = tf.TextLineReader() key, value = reader.read(filename_queue) # key返回的是讀取檔案和行數資訊;value是按行讀取到的原始字串,送到decoder解析 record_defaults = [[1.0], [1.0], [1.0], ["Null"]] # 這裡的資料型別和檔案資料型別一致,必須是list形式 col1, col2, col3, col4 = tf.decode_csv(value, record_defaults=record_defaults) features = tf.stack([col1, col2, col3]) with tf.Session() as sess: coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(coord=coord) for i in range(600): example, label = sess.run([features, col4]) print (example,col4) coord.request_stop() coord.join(threads)
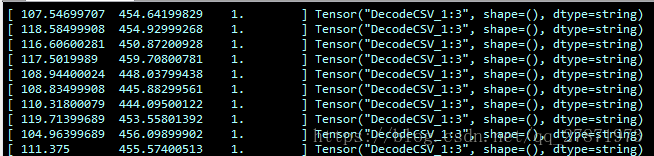
結果如下:
這裡有幾個點需要注意,程式碼註釋中也已經寫明。
- 檔名列表可以自己生成,也可以手寫。
- key是檔案資訊和當前讀取的行數,value是原始字串。
- defualt有兩個作用,一個是指定當前列的資料型別,一個是替補空值。
- 按行讀取後讀出的每個值都是rank為0的標量。
- stack函式可以堆疊,組成一個新的tensor,預設axis=0,因此就會橫向把前面的標量串成一個rank為1的tensor。
參考:
[1] https://blog.csdn.net/freedom098/article/details/56006130