
python之scrapy(四)downloader middlewares的用法
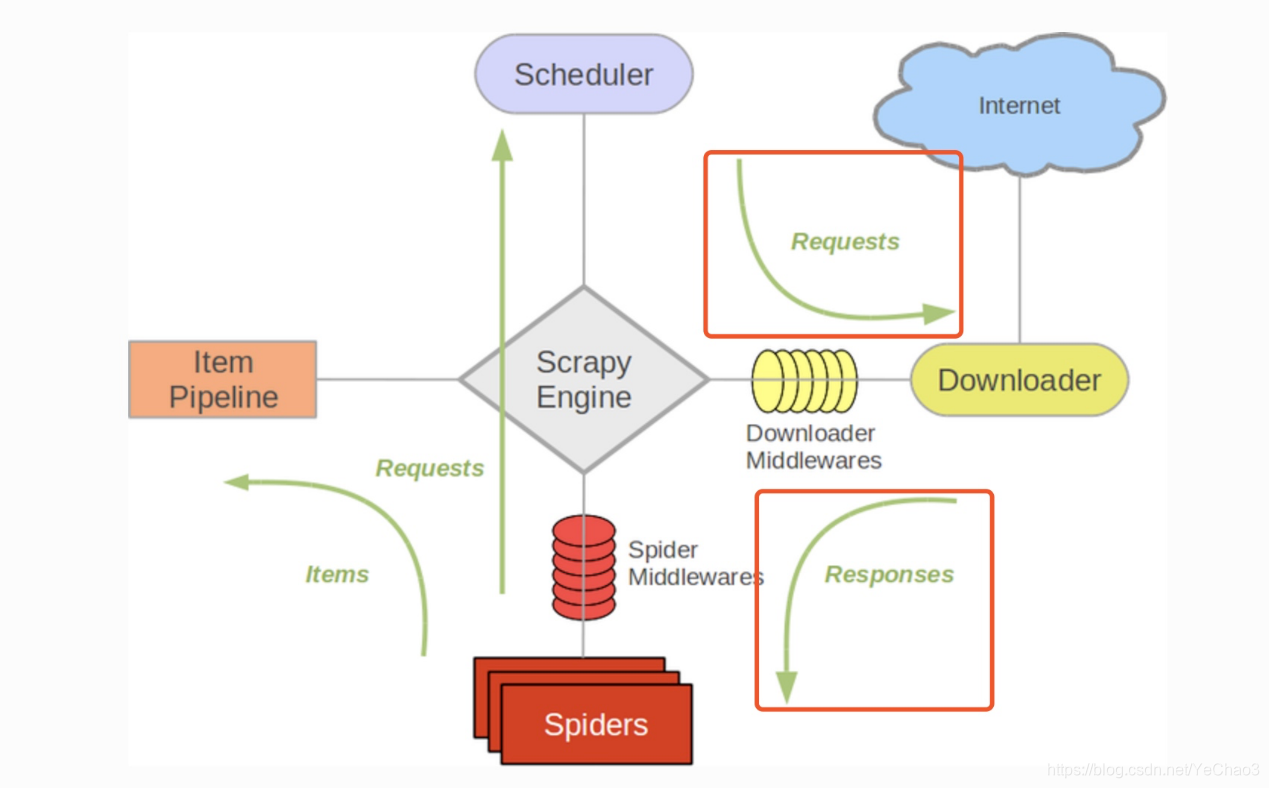
下載中介軟體是處於引擎(Engine)和下載器(DownLoader))之間的一層元件,可以有多個下載中介軟體被載入執行。
-
當引擎傳遞請求給下載器的過程中,下載中介軟體可以對請求進行處理 (例如增加http header資訊,增加proxy資訊等);
-
在下載器完成http請求,傳遞響應給引擎的過程中, 下載中介軟體可以對響應進行處理(例如進行gzip的解壓等)
1.使用說明
需要說明的是Scrapy其實已經提供了很多Downloader Middlewares,比如失敗重試、自動重定向等,他們被定義在DOWNLOADER_MIDDLEWARES_BASE裡面。
{"scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware":100, "scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware":300, "scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware":350, "scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware":400, "scrapy.downloadermiddlewares.useragent.UserAgentMiddleware":500, "scrapy.downloadermiddlewares.retry.RetryMiddleware":550, "scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware":560, "scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware":580, "scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware":590,
"scrapy.downloadermiddlewares.redirect.RedirectMiddleware":600, "scrapy.downloadermiddlewares.cookies.CookiesMiddleware":700, "scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware":750, "scrapy.downloadermiddlewares.stats.DownloaderStats": 850,
"scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware": 900}
可以通過在某專案下的終端輸入:
scrapy settings --get=DOWNLOADER_MIDDLEWARES_BASE
來檢視該專案開啟的內建Downloader Middlewares的名稱和優先順序。
要啟用自定義的下載器中介軟體元件,將其加入到 DOWNLOADER_MIDDLEWARES 設定中。 該設定是一個字典(dict),鍵為中介軟體類的路徑,值為其中介軟體的順序(order)。
這裡是一個例子:
DOWNLOADER_MIDDLEWARES = {
'mySpider.middlewares.MyDownloaderMiddleware': 543,
}
2.核心方法
Scrapy內建的Downloader Middleware為Scrapy提供了基礎的功能,但在專案實戰裡面我們往往需要單獨自定義Downloader Middleware。
每個Downloader Middleware都定義了一個或多個類方法,核心方法主要有三個:
-
process_request(request, spider)
-
process_response(request, response, spider)
-
process_exception(request, exception, spider)
2.1 process_request(request, spider)
當每個request通過下載中介軟體時,該方法被呼叫。該方法主要有兩個引數:
-
request (Request 物件) – 被處理的request
-
spider (Spider 物件) – 該request對應的spider
process_request() 必須返回以下其中之一:一個 None 、一個 Response 物件、一個 Request 物件或 丟擲 IgnoreRequest,返回的型別不同,產生的效果也不一樣:
-
如果其返回 None ,Scrapy將繼續處理該request,執行其他的中介軟體的相應方法,直到合適的下載器處理函式(download handler)被呼叫, 該request被執行(其response被下載)。
-
如果其返回 Response 物件,Scrapy將不會呼叫 任何 其他的 process_request() 或 process_exception() 方法,或相應地下載函式; 其將返回該response。 已安裝的中介軟體的 process_response() 方法則會在每個response返回時被呼叫。
-
如果其返回 Request 物件,Scrapy則停止呼叫 process_request方法並重新排程返回的request。當新返回的request被執行後, 相應地中介軟體鏈將會根據下載的response被呼叫。
-
如果其raise一個 IgnoreRequest 異常,則安裝的下載中介軟體的 process_exception() 方法會被呼叫。如果沒有任何一個方法處理該異常, 則request的errback(Request.errback)方法會被呼叫。如果沒有程式碼處理丟擲的異常, 則該異常被忽略且不記錄(不同於其他異常那樣)。
2.2 process_response(request, response, spider)
DownLoader獲得Response之後,會先經過Downloader Middlewares。所以我們可以通過process_response()的方法,對Response進行處理。該方法有三個引數:
-
request (Request 物件) – response所對應的request
-
response (Response 物件) – 被處理的response
-
spider (Spider 物件) – response所對應的spider
process_response() 必須返回以下其中之一: 返回一個 Response 物件、 返回一個 Request 物件或raise一個 IgnoreRequest 異常。
-
如果其返回一個 Response (可以與傳入的response相同,也可以是全新的物件), 該response會被在鏈中的其他中介軟體的 process_response() 方法處理。
-
如果其返回一個 Request 物件,則中介軟體鏈停止, 返回的request會被重新排程下載。處理類似於 process_request() 返回request所做的那樣。
-
如果其丟擲一個 IgnoreRequest 異常,則呼叫request的errback(Request.errback)。 如果沒有程式碼處理丟擲的異常,則該異常被忽略且不記錄(不同於其他異常那樣)。
2.3 process_exception(request, exception, spider)
當下載處理器(download handler)或 process_request() (下載中介軟體)丟擲異常(包括 IgnoreRequest 異常)時,Scrapy呼叫 process_exception()。主要有3個引數:
-
request (Request 物件) – response所對應的request。
-
exception (Exception 物件) – 丟擲的異常。
-
spider (Spider 物件) – response所對應的spider。
process_exception() 也是返回三者中的一個: 返回 None 、 一個 Response 物件、或者一個 Request 物件。
-
如果其返回 None,Scrapy將會繼續處理該異常,接著呼叫已安裝的其他中介軟體的 process_exception() 方法,直到所有中介軟體都被呼叫完畢,則呼叫預設的異常處理。
-
如果其返回一個 Response 物件,則已安裝的中介軟體鏈的 process_response() 方法被呼叫。Scrapy將不會呼叫任何其他中介軟體的 process_exception() 方法。
-
如果其返回一個 Request 物件, 則返回的request將會被重新呼叫下載。這將停止中介軟體的 process_exception() 方法執行,就如返回一個response的那樣。 這個是非常有用的,就相當於如果我們失敗了可以在這裡進行一次失敗的重試,例如當我們訪問一個網站出現因為頻繁爬取被封ip就可以在這裡設定增加代理繼續訪問
3.實戰
3.1 process_request()和process_exception()方法
新建一個專案,命令如下所示:
scrapy startproject httptest
進入專案,新建一個spider,命令如下:
scrapy genspider http httpbin.org
可以修改spider內容如下:
import scrapy
class HttpSpider(scrapy.Spider):
name = 'http'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/']
def parse(self, response):
self.logger.debug(response.text)
執行此spider,執行如下命令:
scrapy crawl http
獲取request的response資訊:
{"args":{},
"headers":{"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding":"gzip,deflate",
"Accept-Language":"en","Connection":"close","Host":"httpbin.org",
"User-Agent":"Scrapy/1.5.0(+https://scrapy.org)"},
"origin":"116.77.73.255",
"url":"http://httpbin.org/get"}
針對middleware.py檔案中,新增process_request(request, spider)的方法:
import longging
class ProxyMiddleware(object):
logger = logging.getLogger(__name__)
def process_request(self, request, spider):
self.logger.debug('啟動代理!')
request.meta['proxy']='http://118.190.95.43:9001'
return None
在settings裡面,將DOWNLOADER_MIDDLEWARES註釋去掉,並設定如下內容:
DOWNLOADER_MIDDLEWARES = {
'httptest.middlewares.ProxyMiddleware': 543,
}
執行此spider,執行如下命令:
scrapy crawl http
得到內容如下

由此可見,代理已經生效,同時修改的狀態碼,已經生效。
3.2 process_exception()方法
進入專案,新建一個spider,命令如下:
scrapy genspider google www.google.com
輸出相應資訊:
會進行重試。
為了不影響演示,我們將關於重試的功能關閉掉:
DOWNLOADER_MIDDLEWARES = {
#'httptest.middlewares.ProxyMiddleware': 543,
'scrapy.downloadermiddlewares.retry.RetryMiddleware':None,
}
接下來,我們考慮用process_exception()來實現錯誤重試,那麼我們在spider裡面修改內容如下:
import scrapy
class GoogleSpider(scrapy.Spider):
name = 'google'
allowed_domains = ['www.google.com']
start_urls = ['http://www.google.com/']
def make_requests_from_url(self, url):
return scrapy.Request(url=url,dont_filter=True,meta={'download_timeout':10},callback=self.parse)
def parse(self, response):
self.logger.debug(response.text)
接下來實現,在middleware.py檔案裡面實現process_exception():
class ProxyMiddleware(object):
logger = logging.getLogger(__name__)
# def process_request(self, request, spider):
# self.logger.debug('啟動代理!')
# request.meta['proxy']='http://118.190.95.43:9001'
# return None
#
# def process_response(self, request, response, spider):
# response.status=201
# return response
def process_exception(self, request, exception, spider):
self.logger.debug('異常處理')
return request
在settings裡面,將DOWNLOADER_MIDDLEWARES設定如下內容:
DOWNLOADER_MIDDLEWARES = {
'httptest.middlewares.ProxyMiddleware': 543,
'scrapy.downloadermiddlewares.retry.RetryMiddleware':None,
}
得到的輸出如下:

說明進入了process_exception()方法裡面,會不斷進行錯誤重試。