
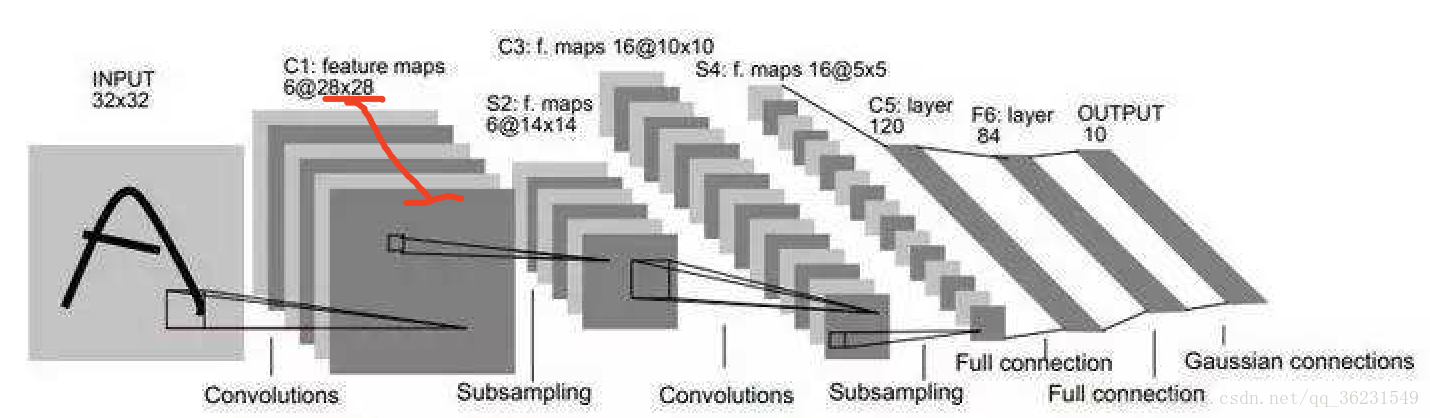
CNN中feature map、卷積核、卷積核個數、filter、channel的概念解釋,以及CNN 學習過程中卷積核更新的理解
feature map、卷積核、卷積核個數、filter、channel的概念解釋
feather map的理解
在cnn的每個卷積層,資料都是以三維形式存在的。你可以把它看成許多個二維圖片疊在一起(像豆腐皮一樣),其中每一個稱為一個feature map。
feather map 是怎麼生成的?
輸入層:在輸入層,如果是灰度圖片,那就只有一個feature map;如果是彩色圖片,一般就是3個feature map(紅綠藍)。
其它層:層與層之間會有若干個卷積核(kernel)(也稱為過濾器),上一層每個feature map跟每個卷積核做卷積,都會產生下一層的一個feature map,有N個卷積核,下層就會產生N個feather map。
多個feather map的作用是什麼?
在卷積神經網路中,我們希望用一個網路模擬視覺通路的特性,分層的概念是自底向上構造簡單到複雜的神經元。樓主關心的是同一層,那就說說同一層。
我們希望構造一組基,這組基能夠形成對於一個事物完備的描述,例如描述一個人時我們通過描述身高/體重/相貌等,在卷積網中也是如此。在同一層,我們希望得到對於一張圖片多種角度的描述,具體來講就是用多種不同的卷積核對影象進行卷,得到不同核(這裡的核可以理解為描述)上的響應,作為影象的特徵。他們的聯絡在於形成影象在同一層次不同基上的描述。
下層的核主要是一些簡單的邊緣檢測器(也可以理解為生理學上的simple cell)。
上層的核主要是一些簡單核的疊加(或者用其他詞更貼切),可以理解為complex cell。
多少個Feature Map?真的不好說,簡單問題少,複雜問題多,但是自底向上一般是核的數量在逐漸變多(當然也有例外,如Alexnet),主要靠經驗。
卷積核的理解
卷積核在有的文件裡也稱為過濾器(filter):
- 每個卷積核具有長寬深三個維度;
- 在某個卷積層中,可以有多個卷積核:下一層需要多少個feather map,本層就需要多少個卷積核。
卷積核的形狀
每個卷積核具有長、寬、深三個維度。在CNN的一個卷積層中:
- 卷積核的長、寬都是人為指定的,長X寬也被稱為卷積核的尺寸,常用的尺寸為3X3,5X5等;
- 卷積核的深度與當前影象的深度(feather map的張數)相同,所以指定卷積核時,只需指定其長和寬 兩個引數。例如,在原始影象層 (輸入層),如果影象是灰度影象,其feather map數量為1,則卷積核的深度也就是1;如果影象是grb影象,其feather map數量為3,則卷積核的深度也就是3.
卷積核個數的理解
如下圖紅線所示:該層卷積核的個數,有多少個卷積核,經過卷積就會產生多少個feature map,也就是下圖中 `豆腐皮兒`的層數、同時也是下圖`豆腐塊`的深度(寬度)!!這個寬度可以手動指定,一般網路越深的地方這個值越大,因為隨著網路的加深,feature map的長寬尺寸縮小,本卷積層的每個map提取的特徵越具有代表性(精華部分),所以後一層卷積層需要增加feature map的數量,才能更充分的提取出前一層的特徵,一般是成倍增加(不過具體論文會根據實驗情況具體設定)!
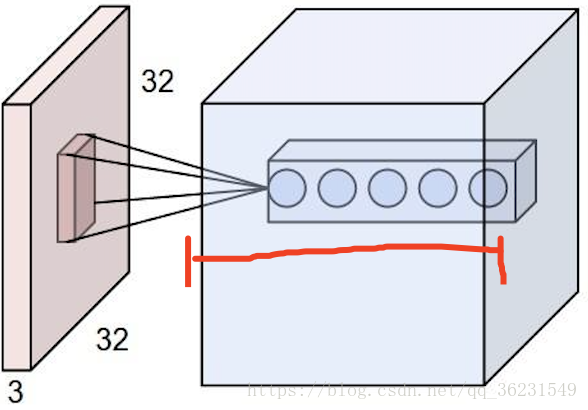
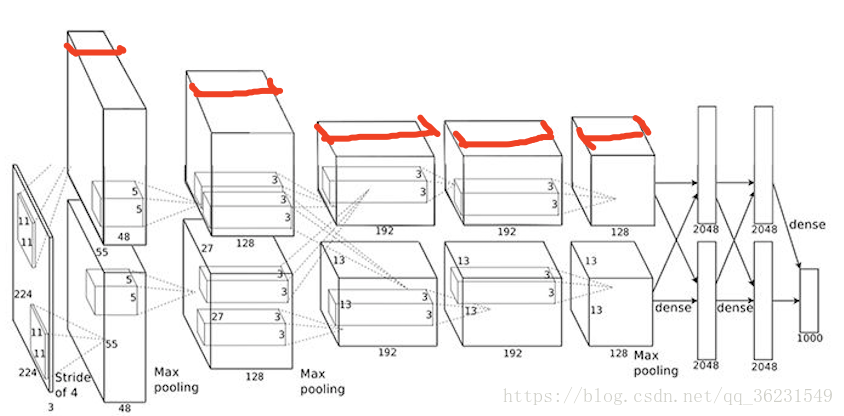
卷積核的運算過程
例如輸入224x224x3(rgb三通道),輸出是32位深度,卷積核尺寸為5x5。
那麼我們需要32個卷積核,每一個的尺寸為5x5x3(最後的3就是原圖的rgb位深3),每一個卷積核的每一層是5x5(共3層)分別與原圖的每層224x224卷積,然後將得到的三張新圖疊加(算術求和),變成一張新的feature map。 每一個卷積核都這樣操作,就可以得到32張新的feature map了。 也就是說:
不管輸入影象的深度為多少,經過一個卷積核(filter),最後都通過下面的公式變成一個深度為1的特徵圖。不同的filter可以卷積得到不同的特徵,也就是得到不同的feature map。。。
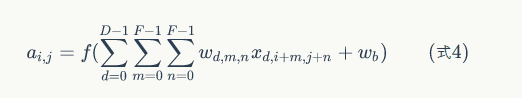

filter的理解
filter有兩種理解:
在有的文件中,一個filter等同於一個卷積核:只是指定了卷積核的長寬深;
而有的情況(例如tensorflow等框架中,filter引數通常指定了卷積核的長、寬、深、個數四個引數),filter包含了卷積核形狀和卷積核數量的概念:即filter既指定了卷積核的長寬深,也指定了卷積核的數量。
理解tensorflow等框架中的引數 channel(feather map、卷積核數量)
在深度學習的演算法學習中,都會提到 channels 這個概念。在一般的深度學習框架的 conv2d 中,如 tensorflow 、mxnet,channels 都是必填的一個引數。
channels 該如何理解?先看一看不同框架中的解釋文件。
首先,是 tensorflow 中給出的,對於輸入樣本中 channels 的含義。一般的RGB圖片,channels 數量是 3 (紅、綠、藍);而monochrome圖片,channels 數量是 1 。
channels : Number of color channels in the example images. For color images, the number of channels is 3 (red, green, blue). For monochrome images, there is just 1 channel (black). ——tensorflow
其次,mxnet 中提到的,一般 channels 的含義是,每個卷積層中卷積核的數量。
channels (int) : The dimensionality of the output space, i.e. the number of output channels (filters) in the convolution. ——mxnet
為了更直觀的理解,下面舉個例子,圖片使用自 吳恩達老師的深度學習課程 。
如下圖,假設現有一個為 6×6×36×6×3 的圖片樣本,使用 3×3×33×3×3 的卷積核(filter)進行卷積操作。此時輸入圖片的 channels 為 33 ,而卷積核中的 in_channels 與 需要進行卷積操作的資料的 channels 一致(這裡就是圖片樣本,為3)。
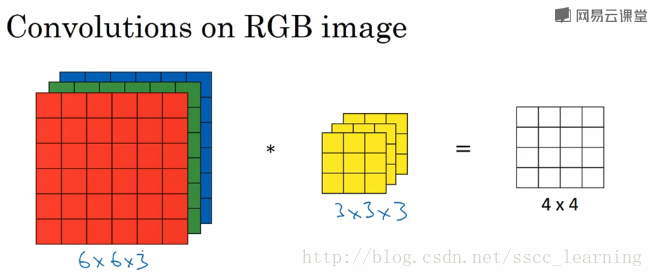
接下來,進行卷積操作,卷積核中的27個數字與分別與樣本對應相乘後,再進行求和,得到第一個結果。依次進行,最終得到 4×4 的結果。
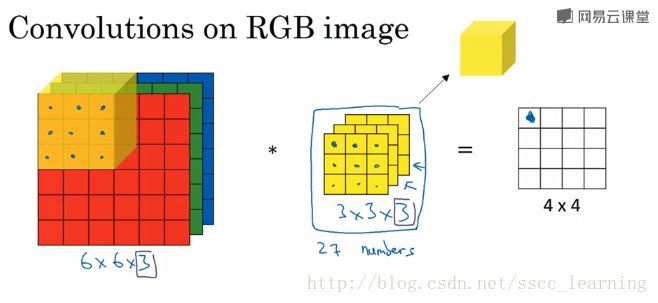
上面步驟完成後,由於只有一個卷積核,所以最終得到的結果為 4×4×1 , out_channels 為 1 。
在實際應用中,都會使用多個卷積核。這裡如果再加一個卷積核,就會得到 4×4×2 的結果。
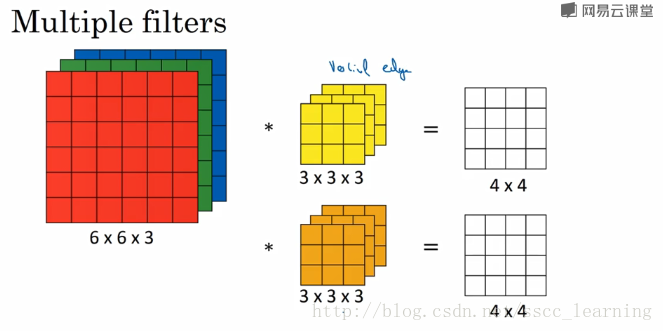
總結一下,我偏好把上面提到的 channels 分為三種:
- 最初輸入的圖片樣本的
channels,取決於圖片型別,比如RGB; - 卷積核中的
in_channels,就是要操作的影象資料的feather map張數,也就是卷積核的深度。(剛剛2中已經說了,就是上一次卷積的out_channels,如果是第一次做卷積,就是1中樣本圖片的channels); - 卷積操作完成後輸出的
out_channels,取決於卷積核的數量(下層將產生的feather map數量)。此時的out_channels也會作為下一次卷積時的卷積核的in_channels。
說到這裡,相信已經把 channels 講的很清楚了。在CNN中,想搞清楚每一層的傳遞關係,主要就是 height,width 的變化情況,和 channels 的變化情況。
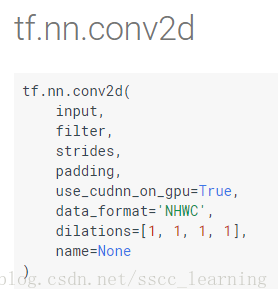
最後再看看 tensorflow 中 tf.nn.conv2d 的 input 和 filter 這兩個引數。 input : [batch, in_height, in_width, in_channels] , filter : [filter_height, filter_width, in_channels, out_channels(卷積核的數量/下層將產生的feather map數量)] 。
裡面的含義是不是很清楚了?
CNN的學習過程:更新卷積核的值(更新提取的影象特徵)
因為卷積核實際上就是如3x3,5x5這樣子的權值(weights)矩陣。我們的網路要學習的,或者說要確定下來的,就是這些權值(weights)的數值。網路不斷前後向的計算學習,一直在更新出合適的weights,也就是一直在更新卷積核們。卷積核在更新了,學習到的特徵也就被更新了(因為卷積核的值(weights)變了,與上一層的map卷積計算的結果也就變了,得到的新map就也變了。)。對分類問題而言,目的就是:對影象提取特徵,再以合適的特徵來判斷它所屬的類別。類似這種概念:你有哪些個子的特徵,我就根據這些特徵,把你劃分到某個類別去。
這樣就很說的通了,卷積神經網路的一整套流程就是:更新卷積核引數(weights),就相當於是一直在更新所提取到的影象特徵,以得到可以把影象正確分類的最合適的特徵們。(一句話:更新weights以得到可以把影象正確分類的特徵。)