
memory-ordering-at-compile-time
淺談Memory Reordering
Memory ordering
在我們編寫的 C/C++程式碼和它被在 CPU 上執行,按照一些規則,程式碼的記憶體互動會被亂序.記憶體亂序同時由編譯器(編譯時候)和處理器(執行時)造成,都為了使程式碼執行的更快.

被編譯開發者和處理器製造商遵循的中心記憶體排序準則是:
不能改變單執行緒程式的行為.
因為這條規則,在寫單執行緒程式碼時記憶體亂序被普遍忽略.即使在多執行緒程式中,它也被時常忽略,因為有 mutexes,semaphores 等來防止它們呼叫中的記憶體亂序.僅當 lock-free 技術被使用時,記憶體在不受任何互斥保護下被多個執行緒共享,記憶體亂序的影響能被看到.
下面先比較 Weak 和 Strong 的記憶體模型,然後分兩部分,實際記憶體亂序如何在編譯和執行時發生,並如何防止它們.
Weak VS strong Memory Models
Jeff Preshing 在 Weak vs. Strong Memory Models 中很好的總結了從 Weak 到 Strong 的型別:
| 非常弱 | 資料依賴性的弱 | 強制 | 順序一致 |
|---|---|---|---|
| DEC Alpha | ARM | X86/64 | dual 386 |
| C/C++11 low-level atomics | PowerPC | SPARC TSO | Java volatile/C/C++11 atomics |
弱記憶體模型
在最弱的記憶體模型中,可能經歷所有四種記憶體亂序 (LoadLoad, StoreStore, LoadStore and StoreLoad).任何 load 或 store 的操作能與任何的其他的 load 或 store 操作亂序,只要它不改變一個獨立程序的行為.實際中,這樣的亂序由於編譯器引起的指令亂序或處理器本身處理指令的亂序.
當處理器是弱硬體記憶體模式,通常稱它為 weakly-ordered 或 weak ordering.或說它有 relaxed memory model. DEC Alpha
C/C++的底層原子操作也呈現弱記憶體模型,無論程式碼的平臺是如 x86/64 的強序處理器.下面章節 Memory ordering at compile time 會演示其弱記憶體模型,並說明如何強制記憶體順序來保護編譯器亂序.
資料依賴性的弱
ARM 和 PowerPC 系列的處理器記憶體模型和 Alpha 同樣弱,除了它們保持 data dependency ordering.它意味兩個相依賴的load(load A, load B<-A)被保證順序load B<-A總能在 load A之後.(A data dependency barrier is a partial ordering on interdependent loads only; it is not required to have any effect on stores, independent loads or overlapping loads.)
強記憶體模型
弱和強記憶體模型區別存在分歧.Preshing 總結的定義是:
一個強硬體記憶體模型是在這樣的硬體上每條機器指令隱性的保證 acquire and release
semantics 的執行.因此,當一個 CPU 核進行了一串寫操作,每個其他的 CPU 核看到這些值的改變順序與其順序一致.
所以也就是保證了四種記憶體亂序 (LoadLoad, StoreStore, LoadStore and StoreLoad) 中的 3 種,除了不保證 StoreLoad 的順序.基於以上的定義,x86/64 系列處理器基本就是強順序的.之後 Memory ordering at processor time 可以看到 StoreLoad 在 X86/64 的亂序實驗.
順序一致
在順序一致 (Sequential consistency) 的記憶體模型中,沒有記憶體亂序存在.
如今,很難找到一個現代多核裝置保證在硬體層 Sequential consistency.也就早期的 386 沒有強大到能在執行時進行任何記憶體的亂序.
當用上層語言程式設計時,Sequential consistency 成為一個重要的軟體記憶體模型.Java5 和之後版本,用volatile宣告共享變數.在 C+11 中,可以使用預設的順序約束memory_order_seq_cst在做原子操作時.當使用這些術語後,編譯器會限制編譯亂序和插入特定 CPU 的指令來指定合適的 memory barrier 型別.
Memory ordering at compile time
看如下程式碼:
test.c
1 2 3 4 5 |
|
不開啟編譯器的優化,把它編譯成彙編,我們可以看到,B的賦值在A的後面,和原程式的順序一樣.
1 2 3 4 5 6 |
|
用O2開啟優化:
1 2 3 4 5 6 |
|
這次編譯器把B的賦值提到A的前面.為什麼它可以這麼做呢?記憶體順序的中心沒有破壞.這樣的改變並不影響單執行緒程式,單執行緒程式不能知道這樣的區別.
但是當編寫 lock-free 程式碼時,這樣的編譯器亂序就會引起問題.看如下例子,一個共享的標識來表明其他共享資料是否更新:
1 2 3 4 5 6 |
|
如果編譯器把update的賦值提到value賦值的前面.即使在單核處理器系統中,會有問題:在兩個引數賦值的中間這個執行緒被中斷,使得另外的程式通過update判斷以為value的值已經得到更新,實際上卻沒有.
顯性的 Compiler Barriers
一種方法是用一個特殊的被稱為 Compiler Barrier 的指令來防止編譯器優化的亂序.以下 asm volative 是 GCC 中的方法.
test_barrier.c
1 2 3 4 5 6 |
|
經過這樣的修改,開啟優化,B的儲存將保持在要求的順序上.
1 2 3 4 5 6 |
|
隱性的 Compiler Barriers
在 C++11 中原子庫中,每個不是 relaxed 的原子操作同時是一個 compiler barrier.
1 2 3 4 5 6 7 |
|
每一個擁有 compiler barrier 的函式本身也是一個 compiler barrier,即使它是 inline 的.
1 2 3 4 5 6 7 |
|
進一步推知,大多數被呼叫的函式是一個 compiler barrier.無論它們是否包含 memory barrier.排除 inline 函式,被宣告為pure attribution 或當 link-time code generation 使用時.因為編譯器在編譯時,並不知道UpdateValue的執行是否依賴於a或會改變a的值從而影響b,所以編譯器不會亂序它們之間的順序.
可以看到,有許多隱藏的規則禁止編譯指令的亂序,也防止了編譯器多進一步的程式碼優化,所以在某些場景 Why the “volatile” type class should not be used, 來讓編譯器進一步優化.
無緣由的儲存
有隱形的 Compiler Barriers,同樣 GCC 編譯器也有無緣由的儲存.來自這裡的例項:
1 2 3 4 5 6 7 8 |
|
在 i686,GCC 3.3.4–4.3.0 用O1編譯得到:
1 2 3 4 5 6 7 8 |
|
在單執行緒中,沒有問題,但多執行緒中呼叫f(0)僅僅只是讀取 v 的值,但中斷後回去覆蓋其他執行緒修改的值.引起 data rate.在新的 C++11 標準中明確禁止了這樣的行為,看最近 C+11 標準進行的 draft§1.10.22 節:
Compiler transformations that introduce assignments to a potentially shared memory location that would not be modified by the abstract machine are generally precluded by this standard.
Memory ordering at processor time
看一個簡單的 CPU 亂序的簡單例子,即使在強記憶體模型的 X86/64 也能看到.有兩個整數X和Y初始是 0,另外兩個變數 r1 和 r2 讀取它們的值,兩個執行緒並行執行,執行如下的機器程式碼:
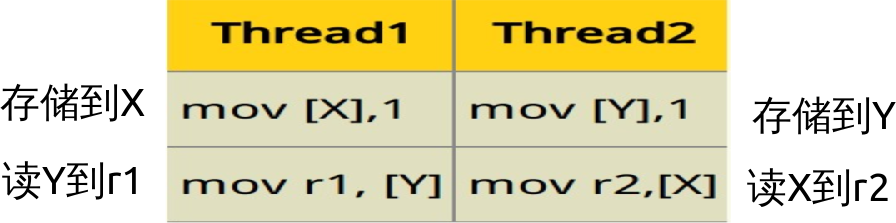
每個執行緒儲存 1 到一個共享變數,然後把對方變數讀取到一個變數或一個暫存器中.無論哪個執行緒先寫 1 到記憶體,另外個執行緒讀回那個值,意味著最後 r1=1 或 r2=1 或兩者都是.但是 X86/64 是強記憶體模型,它還是允許亂序機器指令.特別,每個執行緒允許延遲儲存到讀回之後.以致最後 r1 和 r2 能同時等於 0–違反直覺的一個結果.因為指令可能如下順序執行:

寫一個例項程式,實際看一下 CPU 的確亂序了指令.原始碼可以 Github 下載.兩個讀寫的執行緒程式碼如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
隨機的延遲被插入在儲存的開始處,為了交錯執行緒的開始時間,以來達到重疊兩個執行緒的指令的目的.隨機延遲使用執行緒安全的MersenneTwister類.彙編程式碼asm volatile("" ::: "memory");如上節所述只是用來 防止編譯器的亂序, 因為這裡是要看 CPU 的亂序,排除編譯器的亂序影響.
主執行緒如下,利用 POSIX 的 semaphore 同步它與兩個子執行緒的同步.先讓兩個子執行緒等待,直到主執行緒初始化X=0和 Y=0.然後主執行緒等待,直到兩個子執行緒完成操作,然後主執行緒檢查r1和r2的值.所以 semaphore 防止執行緒見的不同步引起的記憶體亂序,主執行緒程式碼如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
在 Intel i5-2435M X64 的 ubuntu 下執行一下程式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
差不多每 4000 次的迭代才發現一次 CPU 記憶體亂序.所以多執行緒的 bug 是多麼難發現.那麼如何消除這些亂序.至少有如下兩種方法:
- 讓兩個子執行緒在同一個 CPU 核下執行.(沒有可移植性方法,如下是 linux 平臺的).
- 使用 CPU 的 memory barrier 防止它的亂序.
Lock to one processor
讓兩個子執行緒在同一個 CPU 核下執行,程式碼如下:
1 2 3 4 5 |
|
Place a memory barrier
防止一個 Store 在 Load 之後的亂序,需要一個 StoreLoad 的 barrier.這裡使用 mfence的一個全部 memory barrier,防止任何型別的記憶體亂序.程式碼如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
More
- University of Cambridge 整理的文件和論文
- Paul McKenney 概括他們做的一些工作和工具
- The Art of Multiprocessor Programming
- C++ Concurrency in Action: Practical Multithreading
- Is Parallel Programming Hard, And, If So, What Can You Do About It?
- The C++11 Memory Model and GCC
Summarization
- 有兩種記憶體亂序存在:編譯器亂序和 CPU 亂序.
- 如何防止編譯器亂序.
- 如何防止 CPU 亂序.
Posted by DreamRunner Jun 28th, 2014 Multithreading