
【極客時間】資料結構與演算法總結
【極客時間】資料結構與演算法總結:
02|
資料結構是為演算法服務的,演算法要作用在特定的資料結構之上。
20個最常用的最基礎的資料結構與演算法:
10個數據結構:陣列、連結串列、棧、佇列、散列表、二叉樹、堆、跳錶、圖、Trie樹
10個演算法:遞迴、排序、二分查詢、搜尋、雜湊演算法、貪心演算法、分治演算法、回溯演算法、動態規劃、字串匹配演算法
03|
大O時間複雜度表示法,表示程式碼執行時間隨資料規模增長的變化趨勢,也叫做漸進時間複雜度。
時間複雜度分析:
1.只關注迴圈執行次數最多的一段程式碼,我們通常忽略掉公式中的常量、低階、係數。只需要記錄一個最大階的量級。
2.加法法則:總複雜度等於量級最大的那段程式碼的複雜度。
T1(n)=O(f(n)),T2(n)=O(g(n))
T(n)=T1(n)+T2(n)=max(O(f(n)),O(g(n)))=O(max(f(n),g(n)))
3.乘法法則:巢狀程式碼的複雜度等於巢狀內外程式碼複雜度的乘積。
T1(n)=O(f(n)),T2(n)=O(g(n))
T(n)=T1(n)*T2(n)=max(O(f(n))*O(g(n)))=O(max(f(n)*g(n)))
幾種常見的時間複雜度:
多項式量級:
常量階 O(1)
只要演算法中不存在迴圈語句、遞迴語句
對數階 O(logn)
線性階 O(n)
線性對數階 O(nlogn)
歸併排序、快速排序的時間複雜度
平方階 O(n ),立方階以及k次方階
非多項式量級(擁有這個時間複雜度的演算法問題是NP問題):
指數階O(2 )
階乘階 O(n!)
空間複雜度分析:
表示演算法的儲存空間與資料規模之間的增長關係。
越高階複雜度的演算法,執行效率越低,從低階到高階可以是:
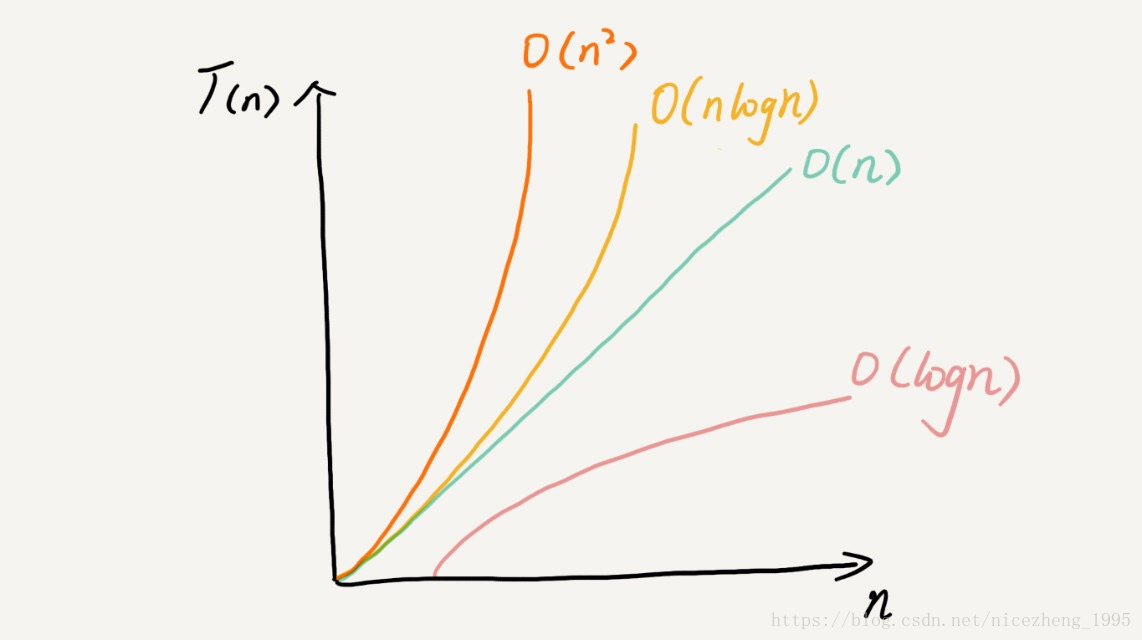
(圖來自於極客時間。)
04|
複雜度分析:
最好情況時間複雜度
最壞情況時間複雜度
平均情況時間複雜度
均攤時間複雜度:在程式碼執行的所有複雜度情況中絕大部分是低級別的複雜度。個別情況是高級別複雜度且發生具有時序關係時,可以將個別高級別複雜度均攤到低級別複雜度上,基本上均攤結果就等於低級別複雜度。
對一個數據結構進行一組連續操作中,大部分情況下時間複雜度都很低,只有個別情況下時間複雜度比較高,而且這些操作之間存在前後連貫的時序關係,這個時候,我們就可以將這一組操作放在一塊分析,看能否將較高時間複雜度那次操作的耗時,平攤到其他那些時間複雜度比較低的操作上。
在能夠運用均攤時間複雜度分析的場合,一般均攤時間複雜度就等於最好情況時間複雜度
加權平均時間複雜度/期望時間複雜度:把每種情況發生的概率也考慮進去
05|
陣列(Array)是一種線性表資料結構。它用一組連續的記憶體空間,來儲存一組具有相同型別的資料。
線性表:陣列、連結串列、佇列、棧等
非線性表(資料之間並不是簡單的前後關係):二叉樹、堆、圖
連續的記憶體空間和相同型別的資料:
因為這個,才有了陣列的特性“隨機訪問”
定址公式:
一維陣列:
a[i]_address=base_address+i*data_type_size
二維陣列:
對於m*n的陣列,
a[i][j]_address=base_address+(i*n+j)*data_type_size
陣列和連結串列的區別:
陣列支援隨機訪問,根據下標隨機訪問的時間複雜度O(1)
在某些特殊場景下,並不一定非要追求陣列中資料的連續性,所以可以將多次刪除操作集中在一起執行,可以提高刪除效率。
可以先記錄下已經刪除的資料。每次的刪除操作並不是真正地搬移資料,只是記錄資料已經被刪除。當陣列沒有更多空間儲存資料時,再觸發一次真正地刪除操作,這樣做可以大大減少刪除操作導致地資料搬移。
應用:JVM標記清除垃圾回收演算法的核心思想。
JVM標記清除演算法:
大多數主流虛擬機器採用可達性分析演算法來判斷物件是否存活,在標記階段,會遍歷所有GC ROOTS,將所有GC ROOTS可達的物件標記為存活。只有當標記工作完成後,清理工作才會開始。
不足:1.效率問題。標記和清理效率都不高,但是當知道只有少量垃圾產生時會很高效。
2.空間問題。會產生不連續的記憶體空間碎片。
容器與陣列的選擇:
ArrayList:可以將很多陣列操作的細節封裝起來,並且支援動態擴容(每次儲存空間不夠的時候,它都會將空間自動擴容1.5倍大小)
擴容操作涉及記憶體申請和資料搬移,是比較耗時,所以最好在建立ArrayList的時候事先指定資料大小。
Java ArrayList無法儲存基本型別,比如int,long,需要封裝為Integer、Long類。關注效能則可以使用陣列。
業務開發直接使用容器。