
sql優化(一)
---
title: sql語句的優化(一)
date: 2018-10-20
categories: 資料庫優化
---
# Explain 命令
資料庫查詢效率的快慢往往是評價一個數據庫是好是差其中的一個標準。
對於好的資料庫而言,往往離不開良好的資料庫設計,硬體配置,網路等諸多因數。
那麼我們在日常開發中,提高資料庫查詢效率最簡單可行的方式就是優化sql語句。
### 導致資料庫查詢緩慢的原因
1. 資料量過大
2. 表設計不合理
3. 沒有合理使用索引
4. sql語句寫得不好
5. 硬體效能低
6. 網速不給力,不穩定
#### 如何找出導致效能慢的原因
此部落格主要是針對sql語句的優化,所以首先你要知道是否跟sql語句有關,我們可以使用資料庫自帶的效能檢測工具,比如:**mysql 的 explain命令 檢視 sql 的執行計劃**
#### Explain
優化查詢效率,主要原則就是應儘量避免**全表掃描**,應該考慮在**合適的列上建立索引**。
explain命令可以檢視sql語句的執行計劃,檢視該sql語句**有沒有使用索引,有沒有做全表掃描***,這都可以通過explain命令來檢視。
##### Explian的使用
---
***語法***:
EXPLAIN 表名
或:
EXPLAIN SELECT 語句 (**重要**)
> * 1. explain語句可以用作descibe的一個同義詞.
程式碼示例:
> * 2. select語句前放上關鍵詞explain,MySQL將解釋它如何處理select,提供有關表如何聯接和聯接的次序。
程式碼示例:

藉助於explain命令,我們可以知道什麼時候必須為表加入索引,以得到一個使用索引來尋找記錄的更快的select。
explain的每個輸出行提供一個表的相關資訊,並且每個行包括下面的10個列
###### 1. id: select識別符,select的查詢序列號.
表示查詢中**執行select子句或操作表的順序**
* id相同,執行順序由上至下
例如:

* 如果是子查詢,id的序號會遞增,id值越大優先順序越高,越先被執行
例如:

###### 2. select_type: 表示查詢中每個select子句的型別
包含如下值:
1. SIMPLE :查詢中不包含 子查詢 或者 UNION 
2. PRIMARY: 最外面的SELECT(查詢中若包含任何複雜的子部分,最外層查詢則被標記為:PRIMARY)

3. UNION:若第二個SELECT出現在UNION之後,則被標記為UNION

4. DEPENDENT UNION:UNION中的第二個或後面的SELECT語句,DEPENDENT意味著SELECT依賴於外層查詢中發現的資料。
5. UNION RESULT: 從UNION表獲取結果的SELECT被標記為:UNION RESULT
6. SUBQUERY: 在SELECT或WHERE列表中包含了子查詢,該子查詢被標記為:SUBQUERY
7. DEPENDENT SUBQUERY: 子查詢中的第一個SELECT,取決於外面的查詢

8. DERIVED: 用來表示包含在from子句中的子查詢的select語句(衍生表)

###### 3. table: 輸出行所引用的表
###### 4. type: 表示mysql在掃描表中找到所需行的方式,又稱“訪問型別”。
常見型別如下:( 從左到右,效能從最差到最好 )
ALL, index,range, ref, eq_ref, const, system
> 完整的型別為:
>
> 結果值從好到壞依次是:
>
> system > const > eq_ref > ref > fulltext > ref_or_null
> index_merge > unique_subquery > index_subquery
> range > index > ALL
>
ALL: 全表掃描,mysql將遍歷全表以找到匹配的行

index:使用索引掃描,index與ALL區別為index型別只遍歷索引樹
**在學生表中學生姓名類添加了索引**

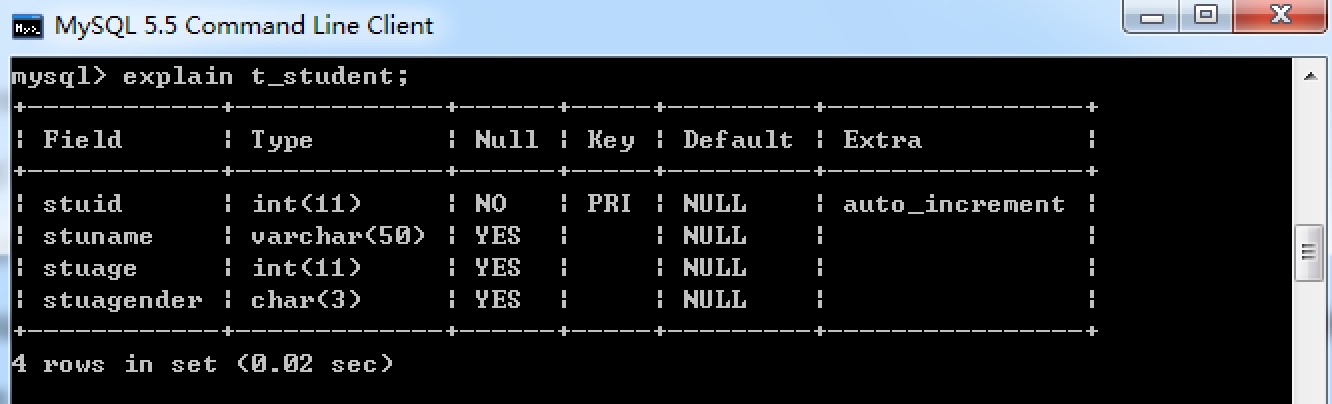
range: 索引範圍掃描,只檢索給定範圍的行,使用一個索引來選擇行。
注意: 學生編號為主鍵列,主鍵列自定建立主鍵索引,所以按學生編號範圍查詢則使用了 range,
學生年齡沒有建立索引,所以按學生年齡範圍查詢沒有使用range,而是使用全表掃描。
ref:使用非唯一索引掃描或者唯一索引掃描,返回匹配某個單獨值的記錄行

eq_ref: 類似ref, 簡單來說,就是多表連線中使用primary key或者 unique key 作為關聯條件.

const: 表最多有一個匹配行,它將在查詢開始時被讀取。因為僅有一行,在這行的列值可被優化器剩 餘部分認為是常數。const表很快,因為它們只讀取一次!
const用於用常數值比較PRIMARY KEY或UNIQUE索引的所有部分時.

system: 表僅有一行(系統表)。這是const聯接型別的一個特例。
###### 5. possible_keys : 指出MySQL能使用哪個索引在該表中找到行,查詢涉及到的欄位上若存在索引,則該索引將被列出,但不一定被查詢使用
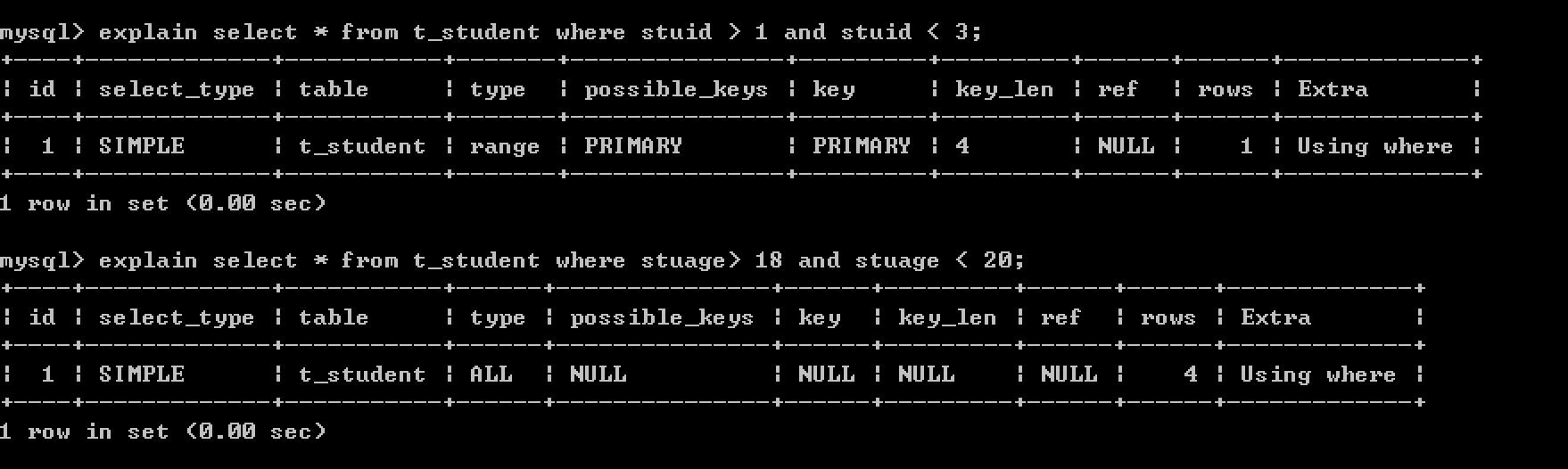
例如: 查詢所有的學生資訊,學生表中,學生姓名列添加了索引,但是此查詢並不會使用該索引。
但是查詢姓名叫李四的同學,則使用到了索引
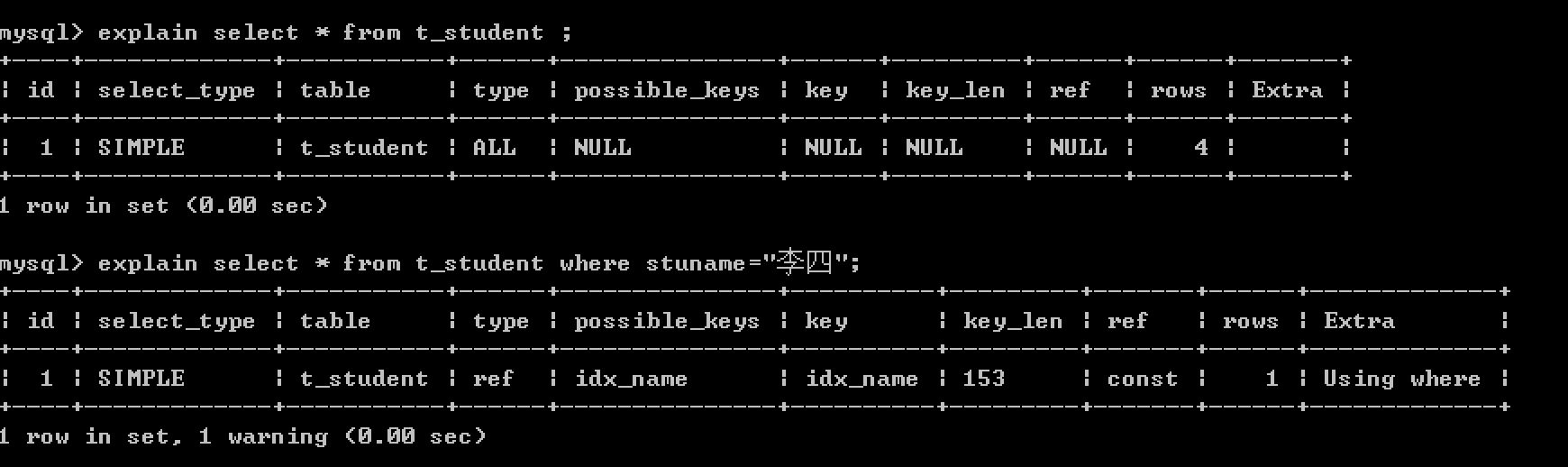
###### 6. key : 顯示MySQL在查詢中實際使用的索引,若沒有使用索引,顯示為NULL
示例中查詢所有的學生資訊沒有使用索引,所以為 null
查詢姓名叫李四的同學使用用到的索引為 idx_name, 所以key的值顯示為 idx_name

###### 7. key_len : 顯示MySQL決定使用的鍵長度。如果鍵是NULL,則長度為NULL
如: 上圖的示例
###### 8. ref :表示上述表的連線匹配條件,即哪些列或常量(主鍵)被用於查詢索引列上的值
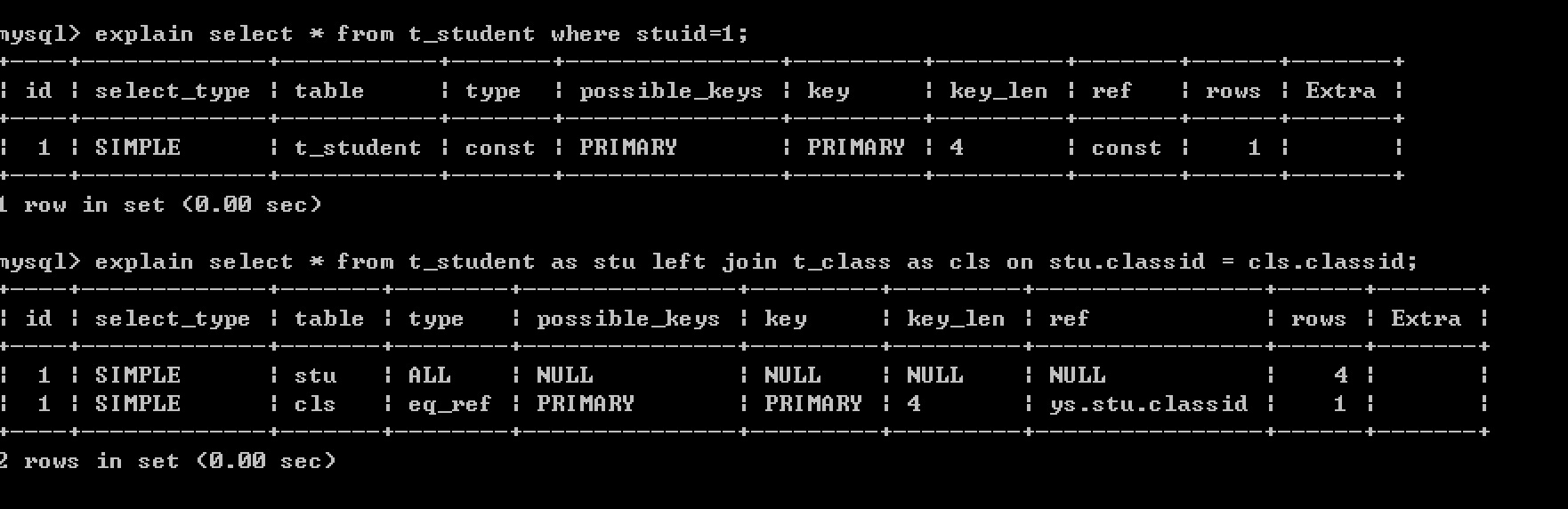
###### 9. rows : 顯示MySQL認為它執行查詢時必須檢查的行數。
該查詢表示: 先掃描班級表,所以掃描檢查3條資料,在掃描檢查學生表,則需要檢查4條資料

###### 10. Extra :該列包含MySQL解決查詢的詳細資訊(顯示十分重要的額外資訊)
該列可以顯示的不同的文字字串:
> Distinct
> Not exists
> range checked for each record
> Using filesort
> Using index
> Using temporary
> Using where
> Using join buffer
> Using sort_union(...)
> Using union(...)
> Using intersect(...)
> Using index for group-by
常見的額外資訊:
Using index:該值表示相應的select操作中使用了覆蓋索引(Covering Index)

Using where:表示mysql伺服器將在儲存引擎檢索行後再進行過濾。許多where條件裡涉及索引中的列,當(並且如果)它讀取索引時,就能被儲存引擎檢驗,因此不是所有帶where字句的查詢都會顯示"Using where"。有時"Using where"的出現就是一個暗示:查詢可受益與不同的索引。
Using join buffer:該值強調了在獲取連線條件時沒有使用索引,並且需要連線緩衝區來儲存中間結果。如果出現了這個值,那應該注意,根據查詢的具體情況可能需要新增索引來改進能。

Using temporary:為了解決查詢,MySQL需要建立一個臨時表來容納結果。典型情況如查詢包含可以 按不同情況列出列的GROUP BY和ORDER BY子句時。
Using filesort: MySQL中無法利用索引完成的排序操作稱為“檔案排序”

Impossible where:這個值強調了where語句會導致沒有符合條件的行。

explain檢視sql執行計劃後:
1. type屬性:如果是ALL,則表示sql需要優化了.
2. rows屬性:表示mysql認為它執行查詢時必須檢查的行數,行數越多效率越低。
3. Extra屬性:額外資訊出現 using fileSort,useing tempoary,則表示sql需要優化了.