
Python爬蟲_亂碼、轉碼
文章目錄
亂碼問題描述
在爬取網頁時,出現中文亂碼情況,如下圖:
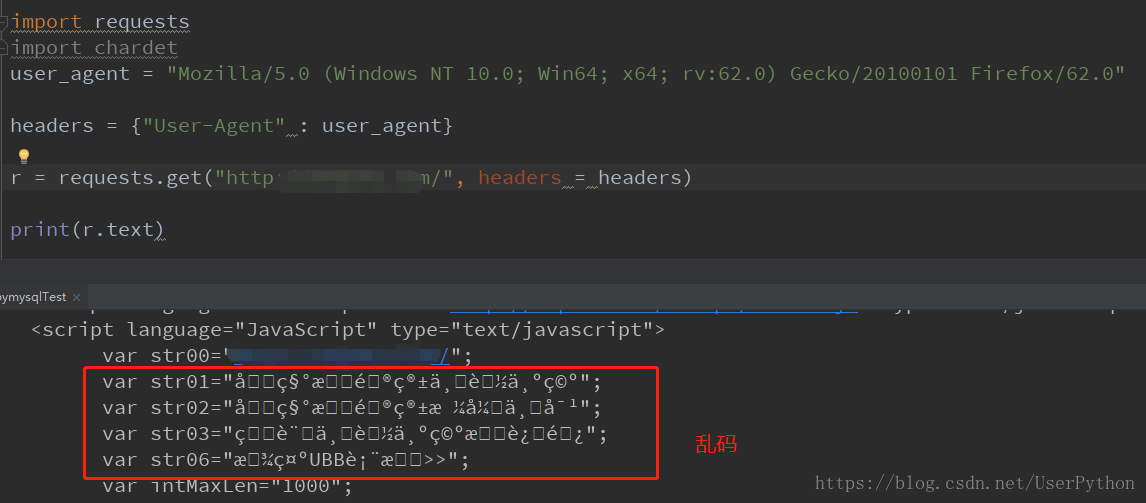
原因:源網頁編碼和爬取下來後的編碼格式不一致
利用encode和decode解決亂碼問題
字串在python內部的表示是Unicode編碼,在做編碼轉換時,通常需要以Unicode作為中間編碼,即先將其他編碼的字串解碼(decode)成Unicode,再從Unicode編碼(encode)成另一種編碼
decode的作用是將其他編碼的字串轉換成Unicode編碼,如str1.decode(“gb2312”),表示將gb2312編碼的字串str1轉換成Unicode編碼
encode的作用是將Unicode編碼轉換成其他編碼的字串,如str2.encode(“utf-8”),表示將Unicode編碼的字串str2轉換成utf-8編碼
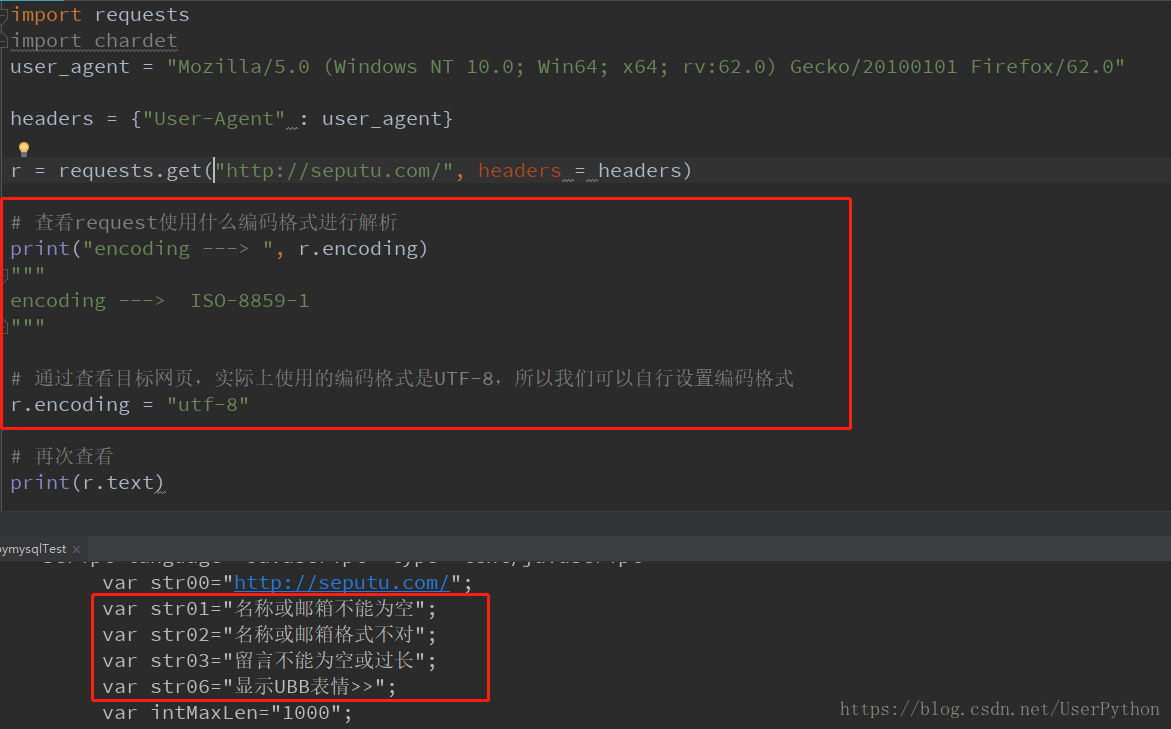
decode中寫的是想爬取的源網頁的編碼,或者文字檔案的編碼,encode是自己想設定的編碼
轉碼–bytes與str之間的互轉
在bytes和str的互相轉換過程中,實際就是編碼解碼的過程,必須顯式地指定編碼格式
str轉bytes
h = "字串str"
# h為字串
print(type(h)) #<class 'str'>
# 字串轉換為bytes型別,方式一
bytes1 = h.encode("utf-8")
print(type(bytes1)) #<class 'bytes'>
print(bytes1) #b'\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2str'
# 字串轉換為bytes型別,方式二
bytes2 = bytes(h, encoding="utf-8")
print(type(bytes2)) #<class 'bytes'> bytes是一種位元流(位元組流),它的存在形式是10010101101這種。我們無論是在寫程式碼,還是閱讀文章的過程中,肯定不會有人直接閱讀這種位元流,它必須有一個編碼方式,使得它變成有意義的位元流,而不是一堆晦澀難懂的01組合。
從上面例子可以看出,h是個字串型別。Python有個內建函式bytes()可以將字串str型別轉換成bytes型別,bytes1實際上是一串01的組合,但為了在ide環境中讓我們相對直觀的觀察,它被表現成了b’\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2str’這種形式,開頭的b表示這是一個bytes型別。\xe5是十六進位制的表示方式,它佔用1個位元組的長度,因此==“字串str”被編碼成utf-8後,我們可以數得出一共用了12個位元組,每個漢字佔用3個,英文字母用1個==。在使用內建函式bytes()的時候,必須明確encoding的引數,不可省略。
字串類str裡有一個encode()方法,它是從字串向位元組流的編碼過程。而bytes型別恰好有個decode()方法,它是從位元組流向字串解碼的過程
bytes轉str
H = b'\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2str'
# H為bytes
print(type(H)) #<class 'bytes'>
# bytes裝換為字串,方式一
string2 = H.decode("utf-8") #預設引數為utf-8
print(type(string2)) #<class 'str'>
print(string2) #字串str
# bytes轉換為字串,方式二
string1 = str(H, "utf-8")
print(type(string1)) #<class 'str'>
print(string1) #字串str