
File was loaded in the wrong encoding: 'UTF-8'
File was loaded in the wrong encoding: ‘UTF-8’
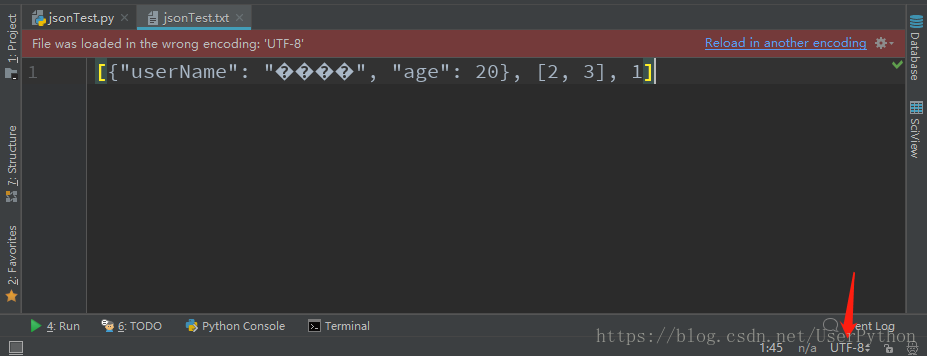
錯誤分析:當我們開啟一個檔案,可是中文出現亂碼,這是可能因為我們檔案使用UTF-8進行編輯,而Windows預設使用GBK編碼格式,所以導致開啟檔案時出現亂碼
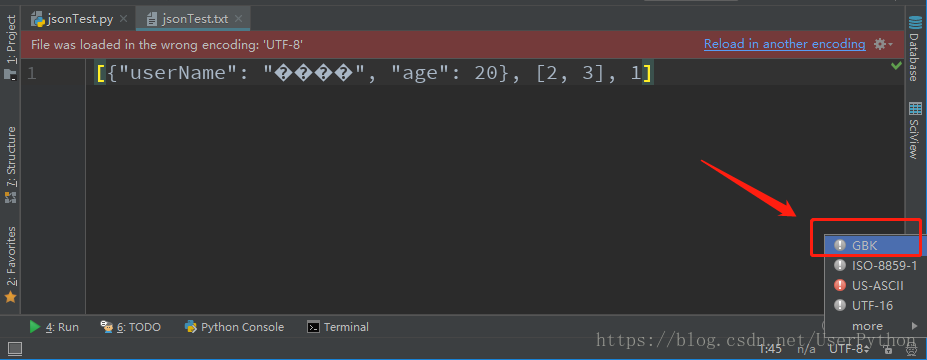
解決方法一:在開啟的文字中解決(治標不治本)。點選圖中右下角的UTF-8,選擇GBK,在彈出的視窗中選擇Reload(過載)


解決方法二:在編輯文字時,設定指定的編碼格式。

相關推薦
File was loaded in the wrong encoding: 'UTF-8'
File was loaded in the wrong encoding: ‘UTF-8’ 錯誤分析:當我們開啟一個檔案,可是中文出現亂碼,這是可能因為我們檔案使用UTF-8進行編輯,而Windows預設使用GBK編碼格式,所以導致開啟檔案時出現亂碼 解決方法一:在開啟的
匯入工程後file was loaded in the wrong encoding和Cannot find System Java Compiler等等
匯入一個工程,報了一些奇怪的問題,如下: 開啟一個java檔案,報:file was loaded in the wrong encoding UTF-8 然後重新編譯工程,報: Cannot fin
TensorFlow學習筆記(UTF-8 問題解決 UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte)
show 學習 github red star ims fas can pri 我使用VS2013 Python3.5 TensorFlow 1.3 的開發環境 UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte
【Python】讀取cvs文件報錯:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb1 in position 6: invalid start byte
spl 重慶 http posit nbsp div ack lin pan 現在有文件data.csv 文件編碼格式為:ANSI data.csv 1|1|1|北京市 2|1|2|天津市 3|1|3|上海市 4|1|4|重慶市 5|1|5|石家莊市 6|
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd0 in position 0: invalid continuation byte
原因 osi png utf ati src 另存為 ima inf 用pandas打開csv文件可能會出現這種情況,原因可能是excel自己新建一個*.csv文件時候容易出錯。進入文件另存為,然後選擇csv文件即可。UnicodeDecodeError: 'ut
python 網絡爬蟲報錯“UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position”解決方案
accept wid python3 header style 設置方法 能夠 error: posit Python3.x爬蟲, 發現報錯“UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0x8b in positi
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb9 in position 16: invalid start byte
nbsp 打開 invalid read osi erro class IT art 讀取一個csv文件失敗,提示: UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xb9 in position 16: inv
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 0: invalid continuation byte
__main__ 需求 tts auto att inf 登錄 == not 需求:python如何實現普通用戶登錄服務器後切換到root用戶再執行命令 解決參考: 代碼: def verification_ssh(host,username,password,port
py檔案增加encoding='utf-8',errors='ignore' 後仍然沒解決UnicodeDecodeError: 'gbk' codec can't decode byte
感覺和oracle的輸出字符集有關,gbk,gb18030都試了沒解決,注意紅色部分,修改後解決問題 #!/usr/bin/env python import sys import csv import cx_Oracle import codecs import os #os.envi
mysql-connector-python取二進位制位元組時報錯UnicodeDecodeError:'utf-8' codec can't decode byte 0xb0 in position 0
在儲存使用者密碼時,我使用了hmac演算法對使用者密碼加密,加密出來的hash值是一個二進位制位元組串,我把這個位元組串存到mysql的password欄位,password欄位的資料型別是varbinary。 在驗證使用者密碼時,我把使用者輸入的密碼經過同樣的hmac演算法得到hash值,然後從資
編碼錯誤UnicodeDecodeError at / 'utf-8' codec can't decode byte 0xb1 in position 30: invalid start byte
類似這種UnicodeDecodeError at / 'utf-8' codec can't decode byte 0xb1 in position 30: invalid start byte編碼錯誤,分析解決方案如下: 1、檢視控制檯報錯,找出引發錯誤的檔案,任何程式設計師自己編寫的檔案都
python 讀取資料出現UnicodeDecodeError:: 'utf-8' codec can't decode byte 0xc8 in position 0: invalid contin
之前寫程式時也出現過類似錯誤,每次解決了到第二次遇見又忘了具體方法,這次記錄一下。 一、字元編碼問題 先介紹一下字元編碼問題 1.ASCLL與GB2312 由於計算機是美國人發明的,因此,最早只有127個字元被編碼到計算機裡,也就是大小寫英文字母、數字和一些符號,這個編碼表被稱為
Python3解決UnicodeDecodeError:'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte
有兩種辦法: 這個時候可以選擇修改字符集引數,一般這種情況出現得較多是在國標碼(GBK)和utf8之間選擇出現了問題。 出現異常報錯是由於設定了decode()方法的第二個引數errors為嚴格(strict)形式造成的,因為預設就是這個引數,將其更改為ignore等即可。例如:
UnicodeDecodeError- 'utf-8' codec can't decode byte 0xc4 in position 0- invalid continuation byte的解決
在用pandas讀入csv文件是,因為文件中有中文所以會出現讀取不了的錯誤。錯誤的原因是'utf-8'編解碼器無法解碼0位的位元組0xc4 解決方案: 在讀入檔案後面加encoding=’gbk’, 如:pddata=pd.read_csv('felipus.cs
【轉載】讀取txt檔案報錯:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc8 in position 0
python在open讀取txt檔案時,出現UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xc8 in position 0: invalid continuation byte報錯 解決辦法有二: ①把編碼方式utf-8
basemap readshapefile UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb4 in position 0
在python中讀取shape檔案時,出現以下錯誤: 錯誤出在下面第三行的位置,說明前面兩個檔案讀的時候都沒問題,唯獨第三個檔案有問題,因此認為是第三個檔案本身的問題。 既然錯誤提到是utf-8編碼的問題,所以想著把shape檔案轉換成utf-8的格式儲存,首先嚐試了在notep
UnicodeEncodeError: 'utf-8' codec can't encode characters in position 50-51: surrogates not allowed
python manage.py collectstatic 收集報錯: Traceback (most recent call last): File "manage.py", line 23, in <module> exec
Python sys.setdefaultencoding('utf-8') 後就沒輸出
col 原來 com stdout 輸出 print bsp png http 為了解決Python的 UnicodeDecodeError: ‘ascii‘ codec can‘t decode byte ,我們可以加入以下代碼。 import sys reload(s
Django- UnicodeDecodeError:'utf-8' codec can't decode 問題解決
wid 問題解決 image one nic splay strong 20px 中文 最近用vs2017新建django模板項目時,頁面輸入中文時導致編碼錯誤,如下圖: 幾經排查,原來是對應的html文件保存的編碼錯誤,重新用utf-8保存即可Django- Unico
python中sys.setdefaultencoding('utf-8')的作用
error: ron load 而不是 ans Coding nbsp 我們 set 在python中,編碼解碼其實是不同編碼系統間的轉換,默認情況下,轉換目標是Unicode,即編碼unicode→str,解碼str→unicode,其中str指的是字節流,而str.de