
叢集排程框架的架構演進之路
叢集架構是現代資料中心非常重要的元件,在最近幾年中有長足發展。架構也從單體式設計轉向更加靈活、去中心化和分散式設計。然而,許多現代開源實現仍然是單體式設計或者缺少很多功能,而這些功能對實際使用者非常有用。這篇部落格是關於大型機群任務排程系列的第一篇,資源排程在Amazon、Google、Facebook、微軟或者Yahoo已經有很好實現,在其它地方的需求也在增長。排程是很重要的課題,因為它直接跟執行叢集的投入有關:一個不好的排程器會造成低利用率,昂貴投入的硬體資源被白白浪費。而光靠它自己也無法實現高利用率,因為資源利用相抵觸的負載必須要仔細配置,正確排程。
架構演進
這篇部落格討論了最近幾年排程架構如何演進,為什麼會這樣。圖一演示了不同的方法:灰色方塊對應一個裝置,不同顏色圈對應一個任務,有“S”的方形代表一個排程器。箭頭代表排程器的排程決定;三種顏色代表不同工作負載(例如,網站服務,批量分析,和機器學習)。 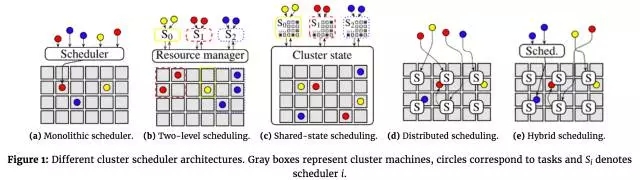
單體式排程 單一排程程序執行在一臺物理機內(例如Hadoop
V1中JobTacker,Kubernetes中的kube-scheduler),將任務指派給叢集內其它物理機。所有負載都服從於一個排程器,所有任務都通過這一個排程邏輯執行(參見圖一a)。這種架構最簡單格式唯一,在此基礎上發展起了很多負載的排程器,例如Paragon和Quasar排程器,採用機器學習方法來避免不同負載之間資源競爭。今天叢集都執行著不同型別的應用(與之相對應的是MapReduce早期作業場景),然而,採用單一排程器來處理這麼複雜異構負載會很棘手,有幾個原因:排程器必須區分對待長期執行服務作業和批量分析作業,這是合理的需求。因為不同應用有不同的需求,催生排程器內加入更多功能,增加業務邏輯和部署方式。排程器處理任務順序變成一個問題:如果排程器不仔細設計,佇列效果(例如線頭阻塞head-of-line
blocking)和回滾會成為問題。 總之,這聽起來像是給工程師帶來噩夢,排程器維護者面對的沒完沒了的功能請求證實了這點。
二級排程
二級排程通過將資源排程和任務排程分離解決了這個問題,這使得任務排程邏輯不僅可以根據不同應用要求而進行裁剪,而且保留了在叢集之間共享資源的可能性。儘管側重點不同,Mesos和
YARN叢集管理都使用了這種方法:Mesos中,資源是主動提供(offer)給應用層排程,而YARN則允許應用層排程請求(request)資源(,並且隨後接受被分配資源)。圖一b展示了這一概念,作業負責排程(S0-S2)跟資源管理器互動,資源管理器則給每個作業分配動態資源。這一方案賦予客戶靈活排程作業策略的可能性。然而,通過二級排程解決問題也有問題:應用層排程將資源全域性排程隱藏起來,也就是說,不再能看到全域性性的可選資源配置。相反,只能看到資源管理器主動提供(offer,對應於Mesos)或者請求/分配(request/allocate,對應於YARN)給應用的資源。由此帶來一些問題:重入優先權(也就是高優先權會將低優先權任務剔除)實現變的很困難。在基於offer模式,被執行中任務佔用的資源對高一級排程器不可見;在基於request模式,底層資源管理器必須理解重入策略(跟應用相關)。排程器不能介入執行中業務,有可能減低資源使用效率(例如,“飢餓鄰居”佔據了IO頻寬),因為排程器看不見他們。應用相關排程器更關注底層資源使用的不同情況,但是他們唯一選擇資源的方法就是資源管理器提供的Offer/request介面,這個介面很容易變的很複雜。
共享狀態架構
共享狀態架構通過採用半分散式模式來解決這個問題,這種架構下叢集狀態多副本會被應用層次排程器獨立更新,如圖一C中所示。一旦本地有更新,排程器釋出一個併發交易更新所有共享叢集狀態。有時候因為另外一個排程器發出了一個衝突交易,交易更新有可能失敗。最重要的共享狀態架構例項是Google的Omega系統,以及微軟的Apollo和Hashicorp的Nomad容器排程。這些例子中,共享叢集狀態架構都是通過一個模組實現,也就是Omega中的“cell
state”,Apollo中的“resource monitor”,以及Nomad中的“plan
queue”。Apollo跟其他兩個不同之處在於共享狀態是隻讀的,排程交易直接提交到叢集裝置;裝置自身會檢查衝突,來決定接受或者拒絕更新,使得Apollo即使在共享狀態暫時不可用情況下也可以繼續執行。邏輯上來說,共享狀態設計不一定必需將全狀態分佈在其它地方,這種方式(有點像Apollo)每個物理裝置維護自己的狀態,將更新發送到其它感興趣的代理,例如排程器,裝置健康監控,和資源監控系統。每個物理裝置本地狀態就成為一個全域性共享狀態的“溝通片”(shard)。然而,共享狀態架構也有一些缺點,必須作用在穩定的(過時的,stale)資訊(這點跟中心化排程器不同),有可能在高競爭情況下造成排程器效能下降(儘管對其它架構也有這種可能)。全分散式架構看起來這種架構更加去中心化:排程器之間沒有任何協調,使用很多各自獨立排程器響應不同負載,如圖一d所示。每個排程器都作用於自己本地(部分或者經常過時的【stale】)叢集狀態資訊。典型的,作業可以提交到任何排程器,排程器可以將作業釋出到任何叢集節點上執行。跟二級排程器不同的是,每個排程器並沒有負責的分割槽,全域性排程和資源分割槽是服從統計意義和隨機分佈的,這有點像共享狀態架構,但是沒有中央控制。儘管說去中心化底層概念(去中心化隨機選擇)是從1996年出現,現代意義上分散式排程應該是從Sparrow論文開始的,當時有一個討論是:合適粒度(fine-grained)任務有很多優勢,Sparrow論文的關鍵假設是叢集上任務週期可以變得很短;接下來,作者假定大量任務意味著排程器必須支援很高通量的決策,而單一排程器並不能支援如此高的決策量(假定每秒上百萬任務量),Sparrow將這些負載分散到許多排程器上。這個實現意義重大:去中心化理論上意味著更多的仲裁,但是這非常適合某類負載,我們會在後面的連載中討論。現在,足夠理由證明,由於分散式排程是無協調的,因此相對於複雜單體式排程,二級排程或者分佈狀態時排程,更適合於簡單邏輯。例如:分散式排程是基於簡單的“時間槽(slot)”概念,將每臺裝置分成n個標準時間槽,同時執行n個併發任務,儘管這種簡化忽略了任務資源需求是各自不同的事實。在任務端(worker
side)使用服從簡單服務規則的佇列方式(例如Sparrow中FIFO),這樣排程器的靈活性受到限制,排程器只需決定在哪臺裝置上將任務入隊。因為沒有中央控制,分散式排程器對於全域性變數設定(例如,fairness
policies或者strict priority
precedence等)有一定難度。因為分散式排程是為基於最少知識做出快速決策而設計,因此無法支援或承擔複雜應用相關排程策略,因此避免任務之間干擾,對於全分散式排程來說很困難。混合式架構混合式架構是為了解決全分散式架構缺陷,最近(發端於學院派)提出的解決方式,它綜合了單體式或者共享狀態的設計。這種方式,例如Tarcil,Mercury和Hawk,一般有兩條排程路徑:一條是為部分負載設計的分散式路徑(例如,短時間任務或者低優先順序批量負載),另外一條集中式排程,處理剩下負載,如圖一e所示。對於所描述的負載來說,混合架構中發生作用的排程器都是唯一的。實際上,據我所知,目前還沒有真正的混合架構部署於生產系統中。實際意義不同調度架構相對價值,除了有很多研究論文外,其討論不僅僅侷限在學院內,從行業角度對於Borg,Mesos和Omega論文的深入討論,可以參見Andrew
Wang的專業部落格。然而,很多以上討論的系統都已經部署在大型企業生產系統中(例如,微軟的Apollo,Google的Borg,Apple的Mesos),反過來這些系統激勵了其它可用開源專案。如今,很多集群系統執行容器化負載,因此有一系列面向容器的“排程框架”(Orchestration
Framworks)出現,他們跟Google以及其它被稱為“叢集管理系統”類似。然而,很少關於這些排程框架和設計原則的討論,更多是集中於面向使用者排程的API(例如,這篇Armand
Grillet的報道,比較了Docker
Swarm,Mesos/Marathon和Kubernetes的預設排程器)。然而,很多客戶既不懂不同調度架構的不同,也不知道哪個更適合自己的應用。圖二展示了一部分開源編排框架的架構和排程器支援的功能。圖表底部,也包括google和微軟閉源系統作比較。資源粒度一列展示排程器分配任務給固定大小時間槽,還是按照多維需求(例如CPU,memory,磁碟IO,網路頻寬等)分配資源。

圖二:常用開源編排框架分類和功能比較,以及與閉源系統比較。決定一個合適排程架構主要因素在於你的叢集是否執行一個異構(或者說混合的)負載。例如,前端服務(例如,負載均衡web服務和memcached)和批量資料分析(例如,MapReduce或者Spark)混合在一起,這種組合對於提高系統利用率是有意義的,但是不同應用需要不同調度方式。在混合設定下,單體式排程很可能導致次優任務分配,因為基於應用需求,單體排程邏輯不能多樣化,而此時二級或者共享狀態排程可能更加適合一些。許多面向用戶服務負載執行的資源一般是滿足容器的峰值需求,但是實際上資源都是過分配的。這種情況下,能夠有機會降低給低優先順序負載過分配資源對高效叢集來說是關鍵。儘管Kubernetes擁有相對成熟方案,Mesos是目前唯一支援這種過分配策略的開源系統。這個功能未來應該有更大改善空間,因為根據Google
borg叢集來看很多叢集利用率任然小於60-70%。後續部落格我們將就資源預估,過分配和有效裝置利用等方面展開討論。最後,特殊分析和OLAP應用(例如,Dremel或者SparkSQL)非常適合全分散式排程。然而,全分散式排程(例如Sparrow)內建相對嚴格功能設定,因此當負載是同構(也就是,所有任務同時執行)、配置時間(set-up
times)很短(也就是,任務排程後長時間執行,如同MapReduce應用任務運行於YARN)、任務通量(churn)很高(也就是,許多排程決定必須很短時間內做出)時非常合適。我們將在下一個部落格中詳細討論這些條件,以及為什麼全分散式排程(以及混合架構中分佈模組)只對這種應用場景有效。現在,我們可以證明分散式排程比其他排程架構更加簡單,而且不支援其他資源維度,過分配或者重新排程。總之,圖二中表格表明,相對於更高階但是閉源的系統來說,開源框架仍然有很大提升空間。可以從如下幾方面採取行動:功能缺失,使用率不佳,任務效能不可預測,鄰居干擾(noisy
neighbours)降低效率,排程器精細調整以支援某些客戶忒別需求。然而,也有很多好訊息:儘管今天還有很多叢集仍然使用單體式排程,但是也已經有很多開始遷移到更加靈活架構。Kubernetes今天已經可以支援可插入式排程器(kube-scheduler
pod可以被其它API相容排程pod替代),更多排程器從1.2版本開始會支援“擴充套件器”提供客戶化策略。Docker
Swarm,據我理解,在未來也會支援可插入式排程器。