
決策樹之ID3演算法實現(python) [置頂] 怒寫一個digit classification(不斷更新中)
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
決策樹之ID3演算法實現(python)
分類: python 演算法 2013-09-27 11:40 107人閱讀決策樹的概念其實不難理解,下面一張圖是某女生相親時用到的決策樹:
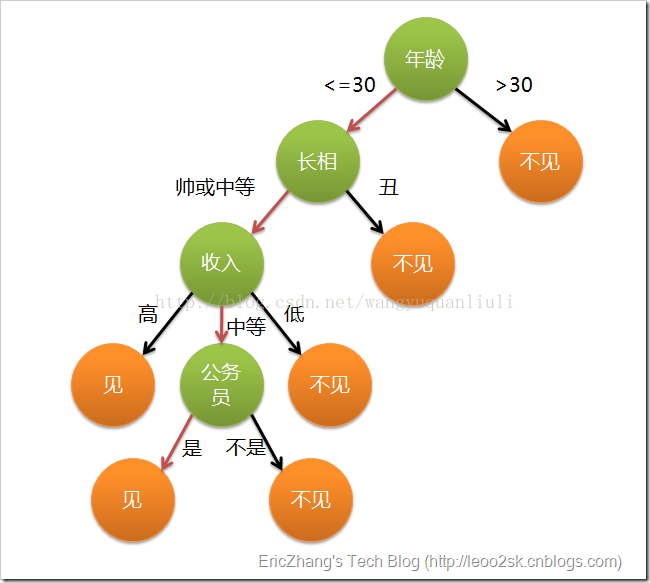
基本上可以理解為:一堆資料,附帶若干屬性,每一條記錄最後都有一個分類(見或者不見),然後根據每種屬性可以進行劃分(比如年齡是>30還是<=30),這樣構造出來的一棵樹就是我們所謂的決策樹了,決策的規則都在節點上,通俗易懂,分類效果好。
那為什麼跟節點要用年齡,而不是長相?這裡我們在實現決策樹的時候採用的是ID3演算法,在選擇哪個屬性作為節點的時候採用資訊理論原理,所謂的資訊增益。資訊增益指原有資料集的熵-按某個屬性分類後資料集的熵。資訊增益越大越好(說明按某個屬性分類後比較純),我們會選擇使得資訊增益最大的那個屬性作為當層節點的標記,再進行遞迴構造決策樹。
首先我們構造資料集:
[python] view plain copy- def createDataSet():
- dataSet = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']]
- features = ['no surfacing','flippers']
- return dataSet,features
構造決策樹:(採用python字典來遞迴構造,一些程式碼看看就能看懂)
- def treeGrowth(dataSet,features):
- classList = [example[-1] for example in dataSet]
- if classList.count(classList[0])==len(classList):
- return classList[0]
- if len(dataSet[0])==1:# no more features
- return classify(classList)
- bestFeat = findBestSplit(dataSet)#bestFeat is the index of best feature
- bestFeatLabel = features[bestFeat]
- myTree = {bestFeatLabel:{}}
- featValues = [example[bestFeat] for example in dataSet]
- uniqueFeatValues = set(featValues)
- del (features[bestFeat])
- for values in uniqueFeatValues:
- subDataSet = splitDataSet(dataSet,bestFeat,values)
- myTree[bestFeatLabel][values] = treeGrowth(subDataSet,features)
- return myTree
當沒有多餘的feature,但是剩下的樣本不完全是一樣的類別是,採用出現次數多的那個類別:
[python] view plain copy- def classify(classList):
- '''''
- find the most in the set
- '''
- classCount = {}
- for vote in classList:
- if vote not in classCount.keys():
- classCount[vote] = 0
- classCount[vote] += 1
- sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1),reverse = True)
- return sortedClassCount[0][0]
尋找用於分裂的最佳屬性:(遍歷所有屬性,算資訊增益)
[python] view plain copy- def findBestSplit(dataset):
- numFeatures = len(dataset[0])-1
- baseEntropy = calcShannonEnt(dataset)
- bestInfoGain = 0.0
- bestFeat = -1
- for i in range(numFeatures):
- featValues = [example[i] for example in dataset]
- uniqueFeatValues = set(featValues)
- newEntropy = 0.0
- for val in uniqueFeatValues:
- subDataSet = splitDataSet(dataset,i,val)
- prob = len(subDataSet)/float(len(dataset))
- newEntropy += prob*calcShannonEnt(subDataSet)
- if(baseEntropy - newEntropy)>bestInfoGain:
- bestInfoGain = baseEntropy - newEntropy
- bestFeat = i
- return bestFeat
選擇完分裂屬性後,就行資料集的分裂:
[python] view plain copy- def splitDataSet(dataset,feat,values):
- retDataSet = []
- for featVec in dataset:
- if featVec[feat] == values:
- reducedFeatVec = featVec[:feat]
- reducedFeatVec.extend(featVec[feat+1:])
- retDataSet.append(reducedFeatVec)
- return retDataSet
計算資料集的熵:
- def calcShannonEnt(dataset):
- numEntries = len(dataset)
- labelCounts = {}
- for featVec in dataset:
- currentLabel = featVec[-1]
- if currentLabel not in labelCounts.keys():
- labelCounts[currentLabel] = 0
- labelCounts[currentLabel] += 1
- shannonEnt = 0.0
- for key in labelCounts:
- prob = float(labelCounts[key])/numEntries
- if prob != 0:
- shannonEnt -= prob*log(prob,2)
- return shannonEnt
下面根據上面構造的決策樹進行資料的分類:
- def predict(tree,newObject):
- while isinstance(tree,dict):
- key = tree.keys()[0]
- tree = tree[key][newObject[key]]
- return tree
- if __name__ == '__main__':
- dataset,features = createDataSet()
- tree = treeGrowth(dataset,features)
- print tree
- print predict(tree,{'no surfacing':1,'flippers':1})
- print predict(tree,{'no surfacing':1,'flippers':0})
- print predict(tree,{'no surfacing':0,'flippers':1})
- print predict(tree,{'no surfacing':0,'flippers':0})
結果如下:
決策樹是這樣的:
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
四個預測:
yes
no
no
no
和給定的資料集分類一樣(預測的資料是從給定資料集裡面抽取的,當然一般資料多的話,會拿一部分做訓練資料,剩餘的做測試資料)
歸納一下ID3的優缺點:
優點:實現比較簡單,產生的規則如果用圖表示出來的話,清晰易懂,分類效果好
缺點:只能處理屬性值離散的情況(連續的用C4.5),在選擇最佳分離屬性的時候容易選擇那些屬性值多的一些屬性。
[置頂] 怒寫一個digit classification(不斷更新中)
分類: python 演算法 2013-09-12 16:11 151人閱讀 評論(0) 收藏 舉報 digit classification knn svm naive bayes decision tree
最近開始學習machine learning方面的內容,大致瀏覽了一遍《machine learning in action》一書,大概瞭解了一些常用的演算法如knn,svm等具體式幹啥的。
在kaggle上看到一個練手的專案:digit classification,又有良好的資料,於是打算用這個專案把各種演算法都跑一遍,加深自己對各演算法的研究,該文會不斷更新。。。。。。
我們的資料集是mnist,連結:http://yann.lecun.com/exdb/mnist/
mnist的結構如下,選取train-images
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
吶,由於智商比較拙急,看了這個形式居然沒看明白,所以特此寫出要注意的點,送給同樣沒看明白的童鞋。
首先該資料是以二進位制儲存的,我們讀取的時候要以'rb'方式讀取,其次,真正的資料只有[value]這一項,其他的[type]等只是來描述的,並不真正在資料檔案裡面。
由offset我們可以看出真正的pixel式從16開始的,一個int 32位元組,所以在讀取pixel之前我們要讀取4個 32 bit integer,也就是magic number,number of images,number of rows,number of columns,讀取二進位制檔案用struct比較方便,struct.unpack_from('>IIII',buf,index)表示按照大端方式讀取4個int.
雖然資料集網站寫著“Users of Intel processors and other low-endian machines must flip the bytes of the header.”,而我的電腦就是intel處理器,但是我嘗試了一把還是得用大端方式讀,讀出來才是“2051 60000 28 28”,用小端方式讀取就不正確了,這個小小實驗一把就行。
下面先把資料檔案直觀的表現出來,用matplotlib把二進位制檔案用影象表現出來。具體如下:
- # -*- coding:utf-8
- import numpy as np
- import struct
- import matplotlib.pyplot as plt
- filename = 'train-images.idx3-ubyte'
- binfile = open(filename,'rb')#以二進位制方式開啟
- buf = binfile.read()
- index = 0
- magic, numImages, numRows, numColums = struct.unpack_from('>IIII',buf,index)#讀取4個32 int
- print magic,' ',numImages,' ',numRows,' ',numColums
- index += struct.calcsize('>IIII')
- im = struct.unpack_from('>784B',buf,index)#每張圖是28*28=784Byte,這裡只顯示第一張圖
- index += struct.calcsize('>784B' )
決策樹的概念其實不難理解,下面一張圖是某女生相親時用到的決策樹:
基本上可以理解為:一堆資料,附帶若干屬性,每一條記錄最後都有一個分類(見或者不見),然後根據每種屬性可以進行劃分(比如年齡是>30還是<=30),這樣構造出來的一棵樹就是我們所謂的決策樹了,決策的規則都在節點上,通俗易懂,分類效果好。
那為什麼跟節點要用年齡,而不是長相?這裡我們在實現決策樹的時候採用的是ID3演算法,在選擇哪個屬性作為節點的時候採用資訊理論原理,所謂的資訊增益。資訊增益指原有資料集的熵-按某個屬性分類後資料集的熵。資訊增益越大越好(說明按某個屬性分類後比較純),我們會選擇使得資訊增益最大的那個屬性作為當層節點的標記,再進行遞迴構造決策樹。
首先我們構造資料集:
[python] view plain copy- def createDataSet():
- dataSet = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']]
- features = ['no surfacing','flippers']
- return dataSet,features
構造決策樹:(採用python字典來遞迴構造,一些程式碼看看就能看懂)
- def treeGrowth(dataSet,features):
- classList = [example[-1] for example in dataSet]
- if classList.count(classList[0])==len(classList):
- return classList[0]
- if len(dataSet[0])==1:# no more features
- return classify(classList)
- bestFeat = findBestSplit(dataSet)#bestFeat is the index of best feature
- bestFeatLabel = features[bestFeat]
- myTree = {bestFeatLabel:{}}
- featValues = [example[bestFeat] for example in dataSet]
- uniqueFeatValues = set(featValues)
- del (features[bestFeat])
- for values in uniqueFeatValues:
- subDataSet = splitDataSet(dataSet,bestFeat,values)
- myTree[bestFeatLabel][values] = treeGrowth(subDataSet,features)
- return myTree
當沒有多餘的feature,但是剩下的樣本不完全是一樣的類別是,採用出現次數多的那個類別:
[python] view plain copy- def classify(classList):
- '''''
- find the most in the set
- '''
- classCount = {}
- for vote in classList:
- if vote not in classCount.keys():
- classCount[vote] = 0
- classCount[vote] += 1
- sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1),reverse = True)
- return sortedClassCount[0][0]
尋找用於分裂的最佳屬性:(遍歷所有屬性,算資訊增益)
[python] view plain copy- def findBestSplit(dataset):
- numFeatures = len(dataset[0])-1
- baseEntropy = calcShannonEnt(dataset)
- bestInfoGain = 0.0
- bestFeat = -1
- for i in range(numFeatures):
- featValues = [example[i] for example in dataset]
- uniqueFeatValues = set(featValues)
- newEntropy = 0.0
- for val in uniqueFeatValues:
- subDataSet = splitDataSet(dataset,i,val)
- prob = len(subDataSet)/float(len(dataset))
- newEntropy += prob*calcShannonEnt(subDataSet)
- if(baseEntropy - newEntropy)>bestInfoGain:
- bestInfoGain = baseEntropy - newEntropy
- bestFeat = i
- return bestFeat
選擇完分裂屬性後,就行資料集的分裂:
[python] view plain copy- def splitDataSet(dataset,feat,values):
- retDataSet = []
- for featVec in dataset:
- if featVec[feat] == values:
- reducedFeatVec = featVec[:feat]
- reducedFeatVec.extend(featVec[feat+1:])
- retDataSet.append(reducedFeatVec)
- return retDataSet
計算資料集的熵:
- def calcShannonEnt(dataset):
- numEntries = len(dataset)
- labelCounts = {}
- for featVec in dataset:
- currentLabel = featVec[-1]
- if currentLabel not in labelCounts.keys():
- labelCounts[currentLabel] = 0
- labelCounts[currentLabel] += 1
- shannonEnt = 0.0
- for key in labelCounts:
- prob = float(labelCounts[key])/numEntries
- if prob != 0:
- shannonEnt -= prob*log(prob,2)
- return shannonEnt
下面根據上面構造的決策樹進行資料的分類:
- def predict(tree,newObject):
- while isinstance(tree,dict):
- key = tree.keys()[0]
- tree = tree[key][newObject[key]]
- return tree
- if __name__ == '__main__':
- dataset,features = createDataSet()
- tree = treeGrowth(dataset,features)
- print tree
- print predict(tree,{'no surfacing':1,'flippers':1})
- print predict(tree,{'no surfacing':1,'flippers':0})
- print predict(tree,{'no surfacing':0,'flippers':1})
- print predict(tree,{'no surfacing':0,'flippers':0})
結果如下:
決策樹是這樣的:
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
四個預測:
yes
no
no
no
和給定的資料集分類一樣(預測的資料是從給定資料集裡面抽取的,當然一般資料多的話,會拿一部分做訓練資料,剩餘的做測試資料)
歸納一下ID3的優缺點:
優點:實現比較簡單,產生的規則如果用圖表示出來的話,清晰易懂,分類效果好
缺點:只能處理屬性值離散的情況(連續的用C4.5),在選擇最佳分離屬性的時候容易選擇那些屬性值多的一些屬性。
[置頂] 怒寫一個digit classification(不斷更新中)
分類: python 演算法 2013-09-12 16:11 151人閱讀 評論(0) 收藏 舉報 digit classification knn svm naive bayes decision tree
最近開始學習machine learning方面的內容,大致瀏覽了一遍《machine learning in action》一書,大概瞭解了一些常用的演算法如knn,svm等具體式幹啥的。
在kaggle上看到一個練手的專案:digit classification,又有良好的資料,於是打算用這個專案把各種演算法都跑一遍,加深自己對各演算法的研究,該文會不斷更新。。。。。。
我們的資料集是mnist,連結:http://yann.lecun.com/exdb/mnist/
mnist的結構如下,選取train-images
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
吶,由於智商比較拙急,看了這個形式居然沒看明白,所以特此寫出要注意的點,送給同樣沒看明白的童鞋。
首先該資料是以二進位制儲存的,我們讀取的時候要以'rb'方式讀取,其次,真正的資料只有[value]這一項,其他的[type]等只是來描述的,並不真正在資料檔案裡面。
由offset我們可以看出真正的pixel式從16開始的,一個int 32位元組,所以在讀取pixel之前我們要讀取4個 32 bit integer,也就是magic number,number of images,number of rows,number of columns,讀取二進位制檔案用struct比較方便,struct.unpack_from('>IIII',buf,index)表示按照大端方式讀取4個int.
雖然資料集網站寫著“Users of Intel processors and other low-endian machines must flip the bytes of the header.”,而我的電腦就是intel處理器,但是我嘗試了一把還是得用大端方式讀,讀出來才是“2051 60000 28 28”,用小端方式讀取就不正確了,這個小小實驗一把就行。
下面先把資料檔案直觀的表現出來,用matplotlib把二進位制檔案用影象表現出來。具體如下:
- # -*- coding:utf-8
- import numpy as np
- import struct
- import matplotlib.pyplot as plt
- filename = 'train-images.idx3-ubyte'
- binfile = open(filename,'rb')#以二進位制方式開啟
- buf = binfile.read()
- index = 0
- magic, numImages, numRows, numColums = struct.unpack_from('>IIII',buf,index)#讀取4個32 int
- print magic,' ',numImages,' ',numRows,' ',numColums
- index += struct.calcsize('>IIII')
- im = struct.unpack_from('>784B',buf,index)#每張圖是28*28=784Byte,這裡只顯示第一張圖
- index += struct.calcsize('>784B' )
最近開始學習machine learning方面的內容,大致瀏覽了一遍《machine learning in action》一書,大概瞭解了一些常用的演算法如knn,svm等具體式幹啥的。
在kaggle上看到一個練手的專案:digit classification,又有良好的資料,於是打算用這個專案把各種演算法都跑一遍,加深自己對各演算法的研究,該文會不斷更新。。。。。。
我們的資料集是mnist,連結:http://yann.lecun.com/exdb/mnist/
mnist的結構如下,選取train-images
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
吶,由於智商比較拙急,看了這個形式居然沒看明白,所以特此寫出要注意的點,送給同樣沒看明白的童鞋。
首先該資料是以二進位制儲存的,我們讀取的時候要以'rb'方式讀取,其次,真正的資料只有[value]這一項,其他的[type]等只是來描述的,並不真正在資料檔案裡面。
由offset我們可以看出真正的pixel式從16開始的,一個int 32位元組,所以在讀取pixel之前我們要讀取4個 32 bit integer,也就是magic number,number of images,number of rows,number of columns,讀取二進位制檔案用struct比較方便,struct.unpack_from('>IIII',buf,index)表示按照大端方式讀取4個int.
雖然資料集網站寫著“Users of Intel processors and other low-endian machines must flip the bytes of the header.”,而我的電腦就是intel處理器,但是我嘗試了一把還是得用大端方式讀,讀出來才是“2051 60000 28 28”,用小端方式讀取就不正確了,這個小小實驗一把就行。
下面先把資料檔案直觀的表現出來,用matplotlib把二進位制檔案用影象表現出來。具體如下:
- # -*- coding:utf-8
- import numpy as np
- import struct
- import matplotlib.pyplot as plt
- filename = 'train-images.idx3-ubyte'
- binfile = open(filename,'rb')#以二進位制方式開啟
- buf = binfile.read()
- &n