
[翻譯]Hystrix wiki–Home
什麼是Hystrix?
在分散式系統中,不可避免地會出現許多依賴的服務不可用的情況。Hystrix通過實現容錯和延時容忍邏輯來實現對相互依賴的分散式服務的控制。Hystrix主要通過隔離服務的呼叫,阻止級聯的服務呼叫失敗以及提供降級策略來提升系統的整體可伸縮性(resiliency)。
Hystrix 在2011年開始由Netflix的API團隊開發,並逐漸在Netflix內部得到廣泛使用。
Hystrix的目的
Hystrix被設計用來:
- 通過引入第三方客戶端庫實現對保護應用避免受延時和失敗的服務呼叫帶來的影響。
- 在複雜的系統中防止級聯故障(cascading failures)
- 快速失敗,快速回復
- 回退和優雅降級
- 提供近實時的監控、告警和操作控制。
Hystrix解決什麼問題?
分散式系統中存在眾多的服務,每個服務都難免出現不可用的情況。如果主應用(關注的應用)沒有和這些不可用的服務隔離,將遭受被這些服務拖垮的危險。
例如,對於一個依賴30個可用性為99.99%服務的應用,其本身的可用性將是:
0.9999^30=99.7%
這意味著,10,000,000次前端中,將有30,000次失敗
每個月中,應用不可用的時間將至少是2小時
實際情況往往比這更差。
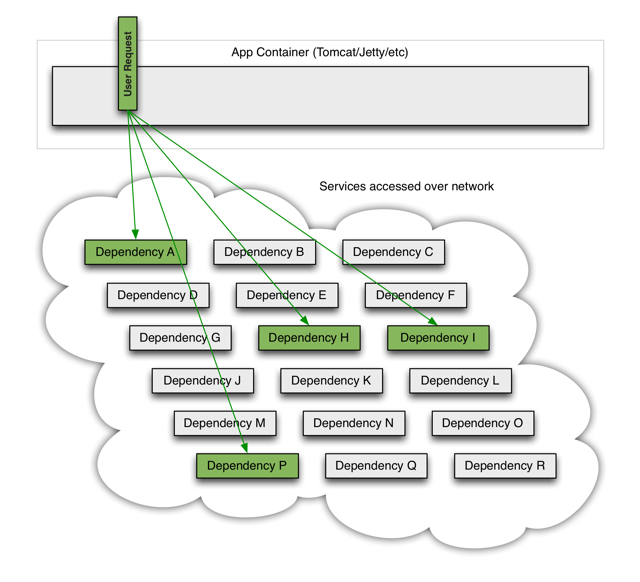
在一切都正常時,客戶發來的請求的呼叫示意如下:
當某一個後臺服務出現超時,或者不可用,他將阻塞整個請求: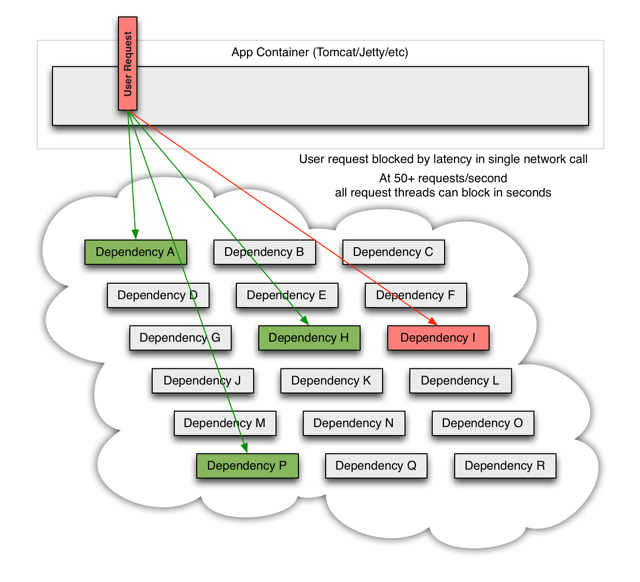
對於訪問量大的後臺服務,如果一旦出現超時,數秒內真個應用的系統資源可能會被立刻耗盡。
在應用中,任何一個通過網路實現的外部呼叫都是可能失敗的。更甚的是,這些不可用的服務,將會逐漸耗盡所有呼叫其提供服務的其他應用的資源,最終可能導致整個系統的雪崩。
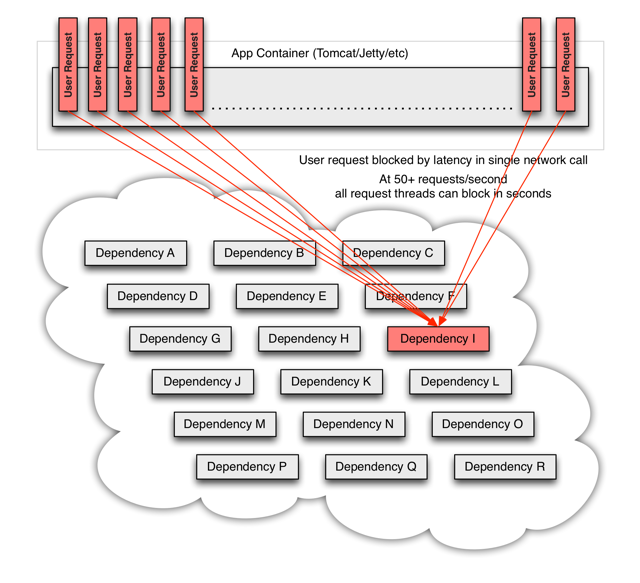
對於通過第三方元件實現網路訪問的情況,這種問題更加嚴重。第三方元件對於應用來說是一個黑盒,其實現細節不可見,對於不同的客戶端元件,網路和資源的配置情況各不相同,並且通常難以修改和監控。
更糟糕的是,還可能存在那些我們並不知道的由第三方元件引入的可變的依賴,引起巨大的網路資源消耗或者錯誤的遠端呼叫。
網路不可用;服務或者節點失效;新元件引入的功能改變;元件的bug。凡此種種,都是需要隔離起來的錯誤,避免一個服務的不可用導致整個應用或者系統的不可用。
##Hystrix 遵循的設計原則:
- 防止單個依賴耗盡整個容器使用者執行緒。
- 採用去掉負荷和快速失敗,而不是排隊
- 在任何可行的情況下通過降級避免失敗
- 通過隔離策略(隔離艙bulkhead,泳道swimlan,斷路器circuit break 設計模式)來限制單個依賴可能引起的影響
- 通過近實時的指標、監控和告警來降低錯誤發現時間
- 配置修改快速生效,支援動態屬性設定,提供實時修改配置功能
- 避免應用受到所有的依賴的失敗帶來的影響,而不只是網路擁堵
Hystrix如何實現其目標?
to be continue…